k8s中如何实现pod自动扩缩容详解
目录
- k8s应用自动扩缩容概述
- 为什么要自动扩缩容
- 扩缩容分类
- 按对象层面
- 按方式分类
- 如何实现自动扩缩容
- HPA运作方式
- 指标信息来源
- 部署HPA实现pod自动扩缩容
- 数据采集组件metrics-server
- 概述
- 部署
- 测试环境准备
- 创建php-apache服务
- 创建nginx服务
- HPA基于cpu自动扩缩容
- 创建HPA基于cpu自动扩缩容
- 压测php-apache服务,看扩容
- 停止对 php-apache 服务压测,看缩容
- HPA基于内存自动扩缩容
- 创建HPA基于内存自动扩缩容
- 压测nginx服务,看扩容
- 取消压测,看缩容
- kubernetes cluster-autoscaler概述
- 什么是 cluster-autoscaler呢?
- Cluster Autoscaler 什么时候伸缩集群?
- 什么时候集群节点不会被 CA 删除?
- HPA 如何与 Cluster Autoscaler 一起使用?
- Cluster Autoscaler 支持那些云厂商?
- 总结
k8s应用自动扩缩容概述
为什么要自动扩缩容
在实际的业务场景中,我们经常会遇到某个服务需要扩容的场景(例如:测试对服务压测、电商平台秒杀、大促活动、或由于资源紧张、工作负载降低等都需要对服务实例数进行扩缩容操作)。
扩缩容分类
按对象层面
- node扩缩容
在使用 kubernetes 集群经常问到的一个问题是,我应该保持多大的节点规模来满足应用需求呢?cluster-autoscaler 的出现解决了这个问题, 可以通过 cluster-autoscaler 实现节点级别的动态添加与删除,动态调整容器资源池,应对峰值流量。 - pod层面
我们一般会使用 Deployment 中的 replicas 参数,设置多个副本集来保证服务的高可用,但是这是一个固定的值,比如我们设置 10 个副本,就会启 10 个 pod 同时 running 来提供服务。
如果这个服务平时流量很少的时候,也是 10 个 pod 同时在 running,而流量突然暴增时,又可能出现 10 个 pod 不够用的情况。针对这种情况怎么办?就需要自动扩缩容。
按方式分类
- 手动模式::通过 kubectl scale 命令,这样需要每次去手工操作一次,而且不确定什么时候业务请求量就很大了,所以如果不能做到自动化的去扩缩容的话,这也是一个很麻烦的事情。
- 自动模式:
1、kubernetes HPA(Horizontal Pod Autoscaling):根据监控指标(cpu 使用率、磁盘、自定义的等)自动扩容或缩容服务中的pod数量,当业务需求增加时,系统将无缝地自动增加适量 pod 容器,提高系统稳定性。
2、kubernetes KPA(Knative Pod Autoscaler):基于请求数对 Pod 自动扩缩容,KPA 的主要限制在于它不支持基于 CPU 的自动扩缩容。
3、kubernetes VPA(Vertical Pod Autoscaler):基于 Pod 的资源使用情况自动设置 pod 的 CPU 和内存的 requests,从而让集群将 Pod 调度到有足够资源的最佳节点上。
如何实现自动扩缩容
HPA运作方式
- 整体逻辑:K8s 的 HPA controller 已经实现了一套简单的自动扩缩容逻辑,默认情况下,每 15s 检测一次指标,只要检测到了配置 HPA 的目标值,则会计算出预期的工作负载的副本数,再进行扩缩容操作。同时,为了避免过于频繁的扩缩容,默认在 5min 内没有重新扩缩容的情况下,才会触发扩缩容。
- 缺陷:HPA 本身的算法相对比较保守,可能并不适用于很多场景。例如,一个快速的流量突发场景,如果正处在 5min 内的 HPA 稳定期,这个时候根据 HPA 的策略,会导致无法扩容。
- pod数量计算方式:通过现有 pods 的 CPU 使用率的平均值(计算方式是最近的 pod 使用量(最近一分钟的平均值,从 metrics-server 中获得)除以设定的每个 Pod 的 CPU 使用率限额)跟目标使用率进行比较,并且在扩容时,还要遵循预先设定的副本数限制:MinReplicas <= Replicas <= MaxReplicas。
计算扩容后 Pod 的个数:sum(最近一分钟内某个 Pod 的 CPU 使用率的平均值)/CPU 使用上限的整数+1
指标信息来源
K8S 从 1.8 版本开始,各节点CPU、内存等资源的 metrics 信息可以通过 Metrics API 来获取,用户可以直接获取这些 metrics 信息(例如通过执行 kubect top 命令),HPA 使用这些 metics 信息来实现动态伸缩。
部署HPA实现pod自动扩缩容
基于1.23.1版kubernetes
HPA官网:https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale/
数据采集组件metrics-server
概述
metrics-server 是一个集群范围内的资源数据集和工具,同样的,metrics-server 也只是显示数据,并不提供数据存储服务,主要关注的是资源度量 API 的实现,比如 CPU、文件描述符、内存、请求延时等指标,metric-server 收集数据给 k8s 集群内使用,如 kubectl,hpa,scheduler 等。
github地址:https://github.com/kubernetes-sigs/metrics-server/
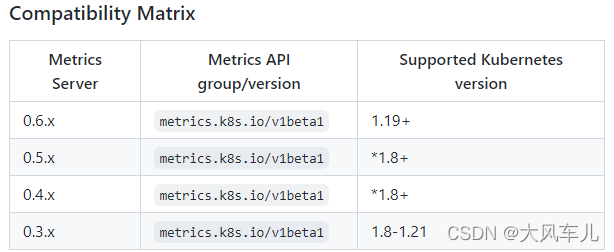
不同k8s版本根据官网安装对应版本的metrics-server
部署
1、镜像下载
所用镜像可提前自行下载:registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.6.1
2、导入镜像
docker load -i metrics-server-0.6.1.tar.gz
3、修改apiserver配置
注意:会中断业务,生产环境谨慎操作!
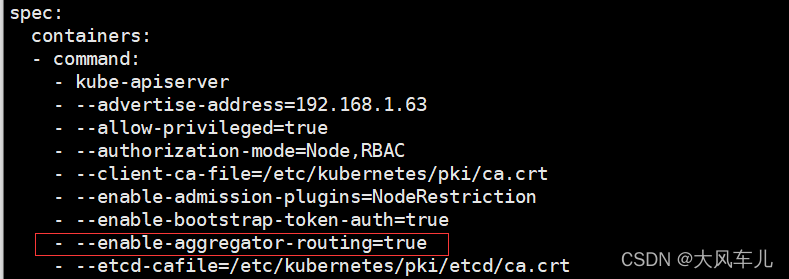
这个是 k8s 在 1.17 的新特性,如果是 1.16 版本的可以不用添加,1.17 以后要添加。这个参数的作用是 Aggregation 允许在不修改 Kubernetes 核心代码的同时扩展 Kubernetes API。
vim /etc/kubernetes/manifests/kube-apiserver.yaml
增加如下内容:
- --enable-aggregator-routing=true
添加后的效果如下图所示:
修改完成后重启kubelet
systemctl restart kubelet
4、部署metrics-server 服务
kubectl apply -f components.yaml
用到的yaml文件到github下载,地址:https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.6.1/components.yaml
5、验证metrics-server是否部署成功
kubectl get pods -n kube-system | grep metrics
可以看到pod处于Running状态:

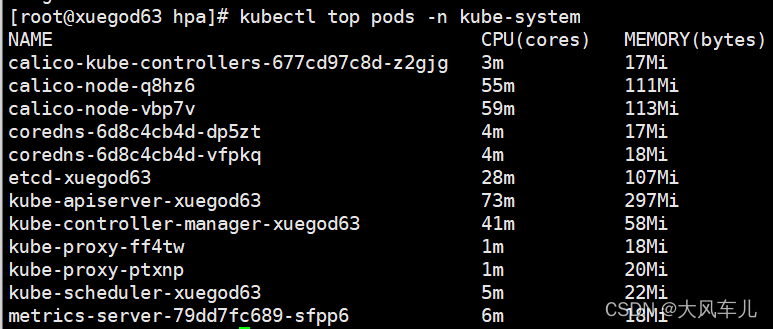
kubectl top nodes # 查看各节点资源使用情况

kubectl top pods -n kube-system # 查看kube-system名称空间下pod资源使用情况
测试环境准备
创建php-apache服务
1、镜像准备
使用 dockerfile 构建一个新的镜像,在 k8s 的 xuegod63 节点构建
mkdir php cd php vim dockerfile
dockerfile内容如下:
FROM php:5-apache ADD index.php /var/www/html/index.php RUN chmod a+rx index.php
创建index.php文件,内容如下:
<?php
$x = 0.0001;
for ($i = 0; $i <= 1000000;$i++) {
$x += sqrt($x);
}
echo "OK!";
?>
docker build -t k8s.gcr.io/hpa-example:v1 . # 构建镜像 docker save -o hpa-example.tar.gz k8s.gcr.io/hpa-example:v1 # 打包镜像 scp hpa-example.tar.gz xuegod64:/root/ # 将镜像传到工作节点
在工作节点导入镜像:
docker load -i hpa-example.tar.gz
2、通过 deployment 部署一个 php-apache 服务
cat php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: k8s.gcr.io/hpa-example:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
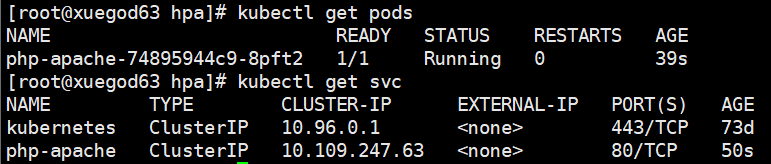
kubectl apply -f php-apache.yaml # 更新资源清单文件 kubectl get pods # 验证 php 是否部署成功
创建nginx服务
1、通过deployment部署一个nginx服务
cat nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-hpa
spec:
selector:
matchLabels:
app: nginx
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: http
protocol: TCP
resources:
requests:
cpu: 0.01
memory: 25Mi
limits:
cpu: 0.05
memory: 60Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
selector:
app: nginx
type: NodePort
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
nodePort: 30080
注意:nginx 的 pod 里需要有如下字段,否则 hpa 会采集不到内存指标
resources:
requests:
cpu: 0.01
memory: 25Mi
limits:
cpu: 0.05
memory: 60Mi
创建资源并查看:
kubectl apply -f nginx.yaml # 更新资源清单 kubectl get pods # 查看pod kubectl get svc # 查看service
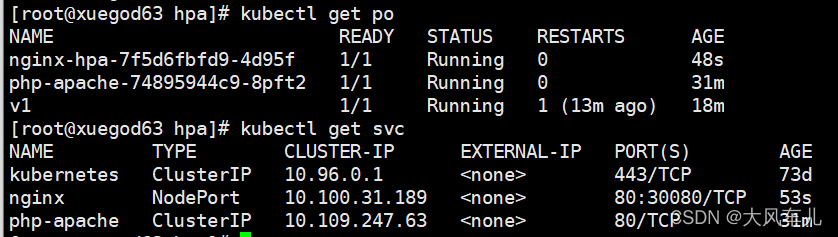
HPA基于cpu自动扩缩容
php-apache 服务正在运行,使用 kubectl autoscale 创建自动缩放器,实现对 php-apache 这个deployment 创建的 pod 自动扩缩容,下面的命令将会创建一个 HPA,HPA 将会根据 CPU资源指标增加或减少副本数,创建一个可以实现如下目的的 hpa:
(1)让副本数维持在 1-10 个之间(这里副本数指的是通过 deployment 部署的 pod 的副本数)
(2)将所有 Pod 的平均 CPU 使用率维持在 50%(通过 kubectl run 运行的每个 pod 如果是 200毫核,这意味着平均 CPU 利用率为 100 毫核)
创建HPA基于cpu自动扩缩容
创建:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
查看:
kubectl get hpa

可以看到cpu目标及当前状态,最大、最小、当前副本数。
压测php-apache服务,看扩容
重新打开一个master节点的终端,进行如下操作:
kubectl run v1 -it --image=busybox --image-pull-policy=IfNotPresent /bin/sh while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
在原master终端查看hpa情况:
kubectl get hpa kubectl get pods

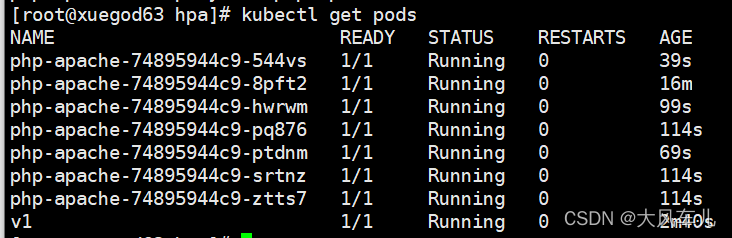
可以看到平均cpu使用率达到了98%,副本数已经变为5个。
注意:可能需要几分钟来稳定副本数。由于不以任何方式控制负载量,因此最终副本数可能会与此示例不同。
停止对 php-apache 服务压测,看缩容
停止向 php-apache 这个服务发送查询请求,在 busybox 镜像创建容器的终端中,通过 Ctrl+ C 把刚才 while 请求停止,然后,我们将验证结果状态(大约一分钟后):
kubectl get hpa

可以看到平均cpu使用率降为0%,副本数降为1。
HPA基于内存自动扩缩容
nginx 服务正在运行,使用 kubectl autoscale 创建自动缩放器,实现对 nginx 这个deployment 创建的 pod 自动扩缩容,下面的命令将会创建一个 HPA,HPA 将会根据内存资源指标增加或减少副本数,创建一个可以实现如下目的的 hpa:
(1)让副本数维持在 1-10 个之间(这里副本数指的是通过 deployment 部署的 pod 的副本数)
(2)将所有 Pod 的平均内存使用率维持在 60%
创建HPA基于内存自动扩缩容
hpa-v1.yaml 内容如下:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-hpa
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 60
kubectl apply -f hpa-v1.yaml # 更新资源清单 kubectl get hpa nginx-hpa # 查看创建的hpa

可以看到当前内存使用率、目标内存使用率,最大、最小、当前副本数。
压测nginx服务,看扩容
使用master节点的终端2登录到上面通过 pod 创建的 nginx,并生成一个文件,增加内存
kubectl exec -it nginx-hpa-7f5d6fbfd9-4d95f -- /bin/bash dd if=/dev/zero of=/tmp/a
使用终端1查看hpa情况:
kubectl get hpa nginx-hpa

可以看到平均内存使用率达到了238%,,副本数达到了4个。
取消压测,看缩容
到终端2使用 Ctrl + C 中断dd进程,删除/tmp/a这个文件
rm -rf /tmp/a
在终端1查看hpa的情况:
kubectl get hpa nginx-hpa

可以看到平均内存使用率已经降到5%,副本数也降为1。(需要等几分钟才能看到)
kubernetes cluster-autoscaler概述
什么是 cluster-autoscaler呢?
Cluster Autoscaler (CA)是一个独立程序,是用来弹性伸缩 kubernetes 集群的。它可以自动根据部署应用所请求的资源量来动态的伸缩集群。当集群容量不足时,它会自动去 Cloud Provider (支持GCE、GKE 和 AWS)创建新的 Node,而在 Node 长时间资源利用率很低时自动将其删除以节省开支。
项目地址:https://github.com/kubernetes/autoscaler
Cluster Autoscaler 什么时候伸缩集群?
在以下情况下,集群自动扩容或者缩放:
扩容:由于资源不足,某些 Pod 无法在任何当前节点上进行调度。
缩容: Node 节点资源利用率较低时,且此 node 节点上存在的 pod 都能被重新调度到其他 node节点上运行。
什么时候集群节点不会被 CA 删除?
1、节点上有 pod 被 PodDisruptionBudget 控制器限制。
2、节点上有命名空间是 kube-system 的 pods。
3、节点上的 pod 不是被控制器创建,例如不是被 deployment, replica set, job, stateful set 创建。
4、节点上有 pod 使用了本地存储。
5、节点上 pod 驱逐后无处可去,即没有其他 node 能调度这个 pod。
6、节点有注解:“cluster-autoscaler.kubernetes.io/scale-down-disabled”: “true”(在 CA 1.0.3 或更高版本中受支持)。
kubectl annotate node <nodename> cluster-autoscaler.kubernetes.io/scale-down-disabled=true
HPA 如何与 Cluster Autoscaler 一起使用?
Horizontal Pod Autoscaler 会根据当前 CPU 负载更改部署或副本集的副本数。如果负载增加,则 HPA 将创建新的副本,集群中可能有足够的空间,也可能没有足够的空间。如果没有足够的资源,CA将尝试启动一些节点,以便 HPA 创建的 Pod 可以运行。如果负载减少,则 HPA 将停止某些副本。结果,某些节点可能变得利用率过低或完全为空,然后 CA 将终止这些不需要的节点。
Cluster Autoscaler 支持那些云厂商?
- GCE https://kubernetes.io/docs/concepts/cluster-administration/cluster-management/
- GKE https://cloud.google.com/container-engine/docs/cluster-autoscaler
- AWS(亚马逊) https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
- Azure(微软) https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/azure/README.md
- Alibaba Cloud https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/alicloud/README.md
- OpenStack Magnum https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/magnum/README.md
- DigitalOcean https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/digitalocean/README.md
- CloudStack https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/cloudstack/README.md
- Exoscale https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/exoscale/README.md
- Packet https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/packet/README.md
- OVHcloud https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/ovhcloud/README.md
- Linode https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/linode/README.md
- Hetzner https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/hetzner/README.md
- Cluster API https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/clusterapi/README.md
总结
到此这篇关于k8s中如何实现pod自动扩缩容的文章就介绍到这了,更多相关k8s实现pod自动扩缩容内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

k8s查看pod日志的几种实用方法汇总
目录 通过kubectl 通过rancher rancher 2.5 rancher 2.6 总结 通过kubectl kubectl logs [-f] [-p] (POD | TYPE/NAME) [-c CONTAINER] 参数 简写 默认值 说明 container c 打印指定容器的日志 all-containers false 获取pod中所有容器的日志. selector l 通过标签筛选pod,支持 ‘=’.‘==’ 和 ‘!=’.例如 -l key1=value1
-
k8s监控数据组件Pod自动化进行扩缩容HPA
自动扩缩容HPA:全称是Horizontal Pod Autoscaler 我们安装k8s集群的时候,安装过一个metrics-server的组件,这是一个监控数据组件,提供HPA和基础资源监控的能力.就是这面这个Pod: [root@k8s-master01 ~]# kubectl get pod -n kube-system metrics-server-6bf7dcd649-5fhrw 1/1 Running 2 (3d5h ago) 8d 通过这个组件可以看到节点或者Pod的内存和CPU
-
k8s中如何实现pod自动扩缩容详解
目录 k8s应用自动扩缩容概述 为什么要自动扩缩容 扩缩容分类 按对象层面 按方式分类 如何实现自动扩缩容 HPA运作方式 指标信息来源 部署HPA实现pod自动扩缩容 数据采集组件metrics-server 概述 部署 测试环境准备 创建php-apache服务 创建nginx服务 HPA基于cpu自动扩缩容 创建HPA基于cpu自动扩缩容 压测php-apache服务,看扩容 停止对 php-apache 服务压测,看缩容 HPA基于内存自动扩缩容 创建HPA基于内存自动扩缩容 压测ngi
-
PHP中类型转换 ,常量,系统常量,魔术常量的详解
PHP中类型转换 ,常量,系统常量,魔术常量的详解 1.自动类型转换; 在运算和判断时,会进行自动类型转换; 1)其他类型转为bool,判断时转换; 1)整型转布尔型:0转false,非0转为true: 2) 空字符串和'0'("0")转为false,其他转为true; 3) 空数组转为false, 非空数组则转为true; 4) null转为false 5) 资源打开不成功为false 是0或空,打开不成功的转为'false','0'; 2)其他类型转为字符串(字符串拼接); nul
-
Android中gson、jsonobject解析JSON的方法详解
JSON的定义: 一种轻量级的数据交换格式,具有良好的可读和便于快速编写的特性.业内主流技术为其提供了完整的解决方案(有点类似于正则表达式 ,获得了当今大部分语言的支持),从而可以在不同平台间进行数据交换.JSON采用兼容性很高的文本格式,同时也具备类似于C语言体系的行为. JSON对象: JSON中对象(Object)以"{"开始, 以"}"结束. 对象中的每一个item都是一个key-value对, 表现为"key:value"的形式, ke
-
ASP.NET MVC中使用jQuery时的浏览器缓存问题详解
介绍 尽管jQuery在浏览器ajax调用的时候对缓存提供了很好的支持,还是有必要了解一下如何高效地使用http协议. 首先要做的事情是在服务器端支持HTTP GET,定义不同的URL输出不同的数据(MVC里对应的就是action).如果要使用同一个地址获取不同的数据,那就不对了,一个HTTP POST也不行因为POST不能被缓存.许多开发人员使用POST主要有2个原因:明确了数据不能被缓存,或者是避免JSON攻击(JSON返回数组的时候可以被入侵). 缓存解释 jQuery全局对象里的ajax
-
python中requests库session对象的妙用详解
在进行接口测试的时候,我们会调用多个接口发出多个请求,在这些请求中有时候需要保持一些共用的数据,例如cookies信息. 妙用1 requests库的session对象能够帮我们跨请求保持某些参数,也会在同一个session实例发出的所有请求之间保持cookies. 举个栗子,跨请求保持cookies,在命令行上输入下面命令: # 创建一个session对象 s = requests.Session() # 用session对象发出get请求,设置cookies s.get('http://ht
-
JSP 自动刷新的实例详解
JSP 自动刷新的实例详解 考虑一个网页被显示实时游戏得分或股市状况或货币兑换利率.对于所有这些类型的网页,你需要使用的刷新或重新加载按钮,您的浏览器定期刷新网页. JSP使这个工作变得简单,它提供一种机制,可以使网页在这样一种方式,它会在给定的时间间隔后自动刷新. 刷新网页的最简单的方法是使用方法setIntHeader()响应对象.下面是该方法的签名: public void setIntHeader(String header, int headerValue) 此方法发送回标题"刷新&q
-
Android中屏幕密度和图片大小的关系详解
Android中屏幕密度和图片大小的关系详解 前言 Android中支持许多资源,包括图片(Bitmap),对应于bitmap的文件夹是drawable,除了drawable,还有drawable-ldpi.drawable-mdpi.drawable-hdpi.drawable-xhdpi.drawable-xxhdpi等,同一张图片放到上面不同的文件夹中是有区别的,比如一张100 * 100像素大小的图片,分别放在上述各个文件夹中,然后将其设置为ImageView(假设宽高都是wrap_co
-
MySQL中Decimal类型和Float Double的区别(详解)
MySQL中存在float,double等非标准数据类型,也有decimal这种标准数据类型. 其区别在于,float,double等非标准类型,在DB中保存的是近似值,而Decimal则以字符串的形式保存数值. float,double类型是可以存浮点数(即小数类型),但是float有个坏处,当你给定的数据是整数的时候,那么它就以整数给你处理.这样我们在存取货币值的时候自然遇到问题,我的default值为:0.00而实际存储是0,同样我存取货币为12.00,实际存储是12. 幸好mysql提供
-
Spring中属性文件properties的读取与使用详解
Spring中属性文件properties的读取与使用详解 实际项目中,通常将一些可配置的定制信息放到属性文件中(如数据库连接信息,邮件发送配置信息等),便于统一配置管理.例中将需配置的属性信息放在属性文件/WEB-INF/configInfo.properties中. 其中部分配置信息(邮件发送相关): #邮件发送的相关配置 email.host = smtp.163.com email.port = xxx email.username = xxx email.password = xxx