MySQL JOIN关联查询的原理及优化
目录
- 1 关联查询的执行
- 2 没有索引的算法
1 关联查询的执行
关联查询的执行过程是:先遍历关联表t1(驱动表,全表扫描),然后根据从表t1中取出的每行数据中的a值,去表t2(被关联表,被驱动表)中查找满足条件的记录,可以走t2的索引搜索。在形式上,这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引,所以我们称之为“Index Nested-Loop Join”,简称NLJ。在join语句的执行流程中,驱动表是走全表扫描,而被驱动表是走索引树搜索。
假设被驱动表的行数是M。每次在被驱动表查一行数据,要先搜索索引a,再搜索主键索引。每次搜索一棵树近似复杂度是以2为底的M的对数,记为log2M,所以在被驱动表上查一行的时间复杂度是 2*log2M。
假设驱动表的行数是N,执行过程就要扫描驱动表N行,然后对于每一行,到被驱动表上匹配一次。
因此整个执行过程,近似复杂度是 N + N2log2M。显然,N对扫描行数的影响更大,因此应该让小表来做驱动表:N扩大1000倍的话,扫描行数就会扩大1000倍;而M扩大1000倍,扫描行数扩大不到10倍。
结论:如果使用join语句的话,需要让小表做驱动表,并且被驱动表的关联字段应该建立索引。一般来说,除非有其他理由,否则只需要在关联顺序中的第二个表的相应列上创建索引,即在被驱动的表的关联字段简历索引。
2 没有索引的算法
如果,被驱动表的关联字段没有使用索引,那么MySQL将使用另一种Block Nested-Loop Join算法。
- 把表t1的数据读入线程内存join_buffer中,这只会将查询需要返回的列放入,如果我们的语句中写的是select *,就会把整个表t1放入了内存;
- 扫描表t2,把表t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
这个过程的流程图如下:
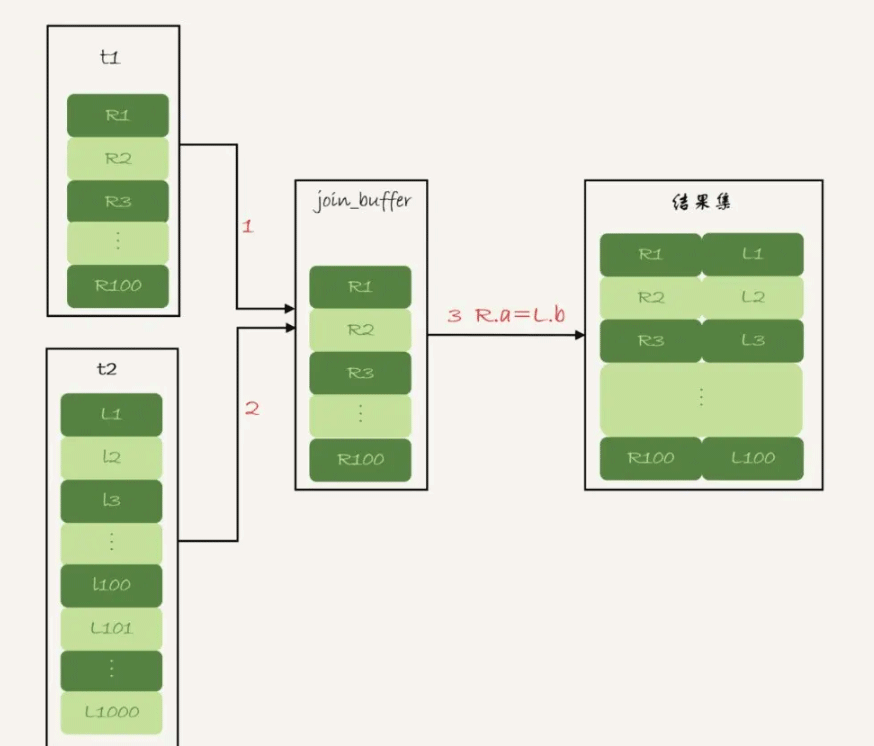
对应地,这条SQL语句的explain结果的Extra字段中将会展示:Block Nested Loop。在这个过程中,对表t1和t2都做了一次全表扫描,因此总的扫描行数是量表的数据总和M+N。由于join_buffer是以无序数组的方式组织的,因此对表t2中的每一行,都要做100次判断,总共需要在内存中做的判断次数是:M* N次。
假设小表的行数是N,大表的行数是M,那么在这个算法里:
- 两个表都做一次全表扫描,所以总的扫描行数是M+N;
- 内存中的判断次数是M*N,虽然不需要读盘,但是需要占用大量CPU进行计算。
可以看到,调换这两个算式中的M和N没差别,因此这时候选择大表还是小表做驱动表,执行耗时是一样的。
join_buffer的大小是由参数join_buffer_size设定的,默认值是256k。如果放不下表t1的所有数据话,策略很简单,就是将t1的数据分段放入、比较,假设表t1被分成了两次放入join_buffer中,那么会导致表t2会被扫描两次。虽然分成两次放入join_buffer,但是内存中判断等值条件的次数还是不变的,依然是M*N次。
假设,驱动表的数据行数是N,需要分K段才能完成算法流程,K大于等于1,被驱动表的数据行数是M。注意,这里的K不是常数,N越大K就会越大。
所以,在这个算法的执行过程中:
- 扫描行数是 N+K*M;
- 内存判断 N*M次。
可以看到,如果join_buffer_size没有足够大(这是常见的情况),那么N越小,这样K就更小,扫描的行数才会更少,因此仍然应该让小表当驱动表。而且K也是影响扫描行数的关键因素,这个值越小越好,如果N不变,那么影响K的就是join_buffer_size的大小。join_buffer_size越大,一次可以放入的行越多,分成的段数K也就越少,对被驱动表的全表扫描次数就越少。
因此,如果你的join语句很慢,除了让小表当驱动表,还有就把join_buffer_size改大。
如果确定“小表”呢?除了总行数之外,还应该是两个表按照各自的条件过滤,过滤完成之后,再计算参与join的各个字段的总数据量(因为还要放入内存中),数据量小的那个表,就是“小表”,应该作为驱动表。
实际在查询优化时,如果join不是使用的Index Nested-Loop Join算法,则应该尽量改为使用该算法。
到此这篇关于MySQL JOIN关联查询的原理及优化的文章就介绍到这了,更多相关MySQL JOIN关联查询 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MYSQL Left Join优化(10秒优化到20毫秒内)
目录 [功能背景] [原始的SQL] [原始的SQL分析] [分析步骤] [优化后的SQL] [优化的SQL分析] 结合工作中的内容和大家分享一次Left Jon优化的过程,希望能给同学们新的思路. [功能背景] 我们需要按照用户订单号和商户号统计出购买的商品数量和售后的商品数量.涉及到的表和关系见下图: 很不幸工程师在起初进行表结构设计的时候没有在商户订单表中记录下购买的商品总数,在商户订单的售后单中也没记录下售后的商品数量. [原始的SQL] select o.no,s_order.
-
mysql高效查询left join和group by(加索引)
mysql高效查询 mysql牺牲了group by来增加left join的速度(前提是加了索引). user表:10万数据 实例1: 200秒左右 SELECT U.id, A.favorite_count FROM (SELECT id from user) U LEFT JOIN ( -- 点赞数 SELECT favorite_by AS user_id, SUM(favorite_count) AS favorite_count FROM favorite GROUP BY favo
-
MySQL数据库连接查询 join原理
目录 1.连接查询的分类 2.交叉连接 2.1.原理 2.2.基本语法 2.3.应用 3.内连接 3.1.原理 3.2.基本语法 3.3.应用 4.外连接 4.1.原理 4.2.基本语法 4.3.特点 4.4.应用 5.using关键字 5.1.原理 5.2.基本语法 1.连接查询的分类 交叉连接 内连接 外连接 左外链接(左连接) 右外连接(右连接) 自然连接 2.交叉连接 将两张表的数据与另外一张表彼此交叉 2.1.原理 笛卡尔积: 从第一张表一次取出每一条数据 取出每一条记录之后,与另外一
-

MySQL七种JOIN类型小结
在开始之前,我们创建两个表用于演示将要介绍的其中JOIN类型. 建表 CREATE TABLE `tbl_dept` ( `id` INT(11) NOT NULL AUTO_INCREMENT, `deptName` VARCHAR(30) DEFAULT NULL, `locAdd` VARCHAR(40) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8; CREAT
-
解决Mysql的left join无效及使用的注意事项说明
Mysql的left join无效及使用 今天写sql发现使用left join 没有把左边表的数据全部查询出来,让我郁闷了一会,后来仔细研究了一会才知道自己犯了个常识性的错误(我是菜鸟) 这是原sql 这样的查询并不能将tb_line这张表的数据都查询出来,好尴尬... 后面我才知道原来当我们进行多表查询,在执行到where之前,会先形成一个临时表 而on就是临时表中的条件筛选,使用left join则不管条件是否为真,都会查询出左边表的数据,条件为假的,则显示为null where则是在临时
-
Mysql体系化探讨令人头疼的JOIN运算
目录 前言 一图总览 SQL中的JOIN SQL对JOIN的定义 JOIN定义 JOIN分类 等值JOIN 空值处理规则下分类 JOIN的实现 笨办法 数据库对于JOIN优化 分布式系统下JOIN 等值JOIN的剖析 三种等值JOIN: 外键关联 同维表 主子表 JOIN的语法简化 外键属性化 同维表等同化 子表集合化 维度对齐语法 解决关联查询 多表JOIN问题 简化JOIN运算好处: 关联查询 外键预关联 全内存下外键关联情况 进一步的外键关联 外键序号化 借助集群的力量解决大维表问题. 有
-
MySQL JOIN关联查询的原理及优化
目录 1 关联查询的执行 2 没有索引的算法 1 关联查询的执行 关联查询的执行过程是:先遍历关联表t1(驱动表,全表扫描),然后根据从表t1中取出的每行数据中的a值,去表t2(被关联表,被驱动表)中查找满足条件的记录,可以走t2的索引搜索.在形式上,这个过程就跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引,所以我们称之为“Index Nested-Loop Join”,简称NLJ.在join语句的执行流程中,驱动表是走全表扫描,而被驱动表是走索引树搜索. 假设被驱动表的行数是M.每次
-
Mysql join连接查询的语法与示例
连接查询: 是将两个查询(或表)的每一行,以"两两横同对接"的方式,所得到的所有行的结果,即一个表中的某行,跟另一个表中的某行.进行"横向对接",得到一个新行. 连接查询包括以下这些不同形式,连接方式: 交叉连接.内连接.外连接(分:左外连接,右外连接) 连接查询语法: select * from 表名 [连接方式] join 表名 [on 连接条件] where ...; 测试数据: mysql> select * from test; +----+----
-
laravel join关联查询代码实例
laravel join关联查询 1.两表关联 $fbaInventoryTb = (new \App\Model\Amz\Fba\InventoryReport)->getTable(); $productTb = (new \App\Model\Amz\Product)->getTable(); $twInventoryTb = (new \App\Model\TWUsa\TwusaInventory)->getTable(); $qry = \DB::table($fbaInven
-
Yii2实现跨mysql数据库关联查询排序功能代码
背景:在一个mysql服务器上(注意:两个数据库必须在同一个mysql服务器上)有两个数据库: memory (存储常规数据表) 中有一个 user 表(记录用户信息) memory_stat (存储统计数据表) 中有一个 user_stat (记录用户统计数据) 现在在 user 表生成的 GridView 列表中展示 user_stat 中的统计数据 只需要在User的model类中添加关联 public function getStat() { return $this->hasOne(U
-
提高MySQL深分页查询效率的三种方案
开发经常遇到分页查询的需求,但是当翻页过多的时候,就会产生深分页,导致查询效率急剧下降.有没有什么办法,能解决深分页的问题呢?本文总结了三种优化方案,查询效率直接提升10倍,一起学习一下. 开发经常遇到分页查询的需求,但是当翻页过多的时候,就会产生深分页,导致查询效率急剧下降. 有没有什么办法,能解决深分页的问题呢? 本文总结了三种优化方案,查询效率直接提升10倍,一起学习一下. 1. 准备数据 先创建一张用户表,只在create_time字段上加索引: CREATE TABLE `user`
-
PHP中Laravel 关联查询返回错误id的解决方法
在 Laravel Eloquent 中使用 join 关联查询,如果两张表有名称相同的字段,如 id,那么它的值会默认被后来的同名字段重写,返回不是期望的结果.例如以下关联查询: PHP $priority = Priority::rightJoin('touch', 'priorities.touch_id', '=', 'touch.id') ->where('priorities.type', 1) ->orderBy('priorities.total_score', 'desc')
-
mysql关联子查询的一种优化方法分析
本文实例讲述了mysql关联子查询的一种优化方法.分享给大家供大家参考,具体如下: 很多时候,在mysql上实现的子查询的性能较差,这听起来实在有点难过.特别有时候,用到IN()子查询语句时,对于上了某种数量级的表来说,耗时多的难以估计.本人mysql知识所涉不深,只能慢慢摸透个中玄机了. 假设有这样的一个exists查询语句: select * from table1 where exists (select * from table2 where id>=30000 and table1.u
-
解析MySQL join查询的原理
MySQL用Nested-Loop Join算法实现join查询 区分驱动表和被驱动表,以驱动表的结果集为循环的基础,访问被驱动表过滤数据,然后合并结果,驱动表在外循环.被驱动表在内循环.如果还有第三张参与join查询的表,则以合并的结果为驱动表,第三张表作为被驱动表,以此类推. left join中的左表是驱动表.右表是被驱动表,right join刚好相反. Nested-Loop Join有三种实现 SNLJ Simple Nested-Loop Join 假设A是驱动表,B是被驱动表.
-
MySQL中表子查询与关联子查询的基础学习教程
MySQL 表子查询 表子查询是指子查询返回的结果集是 N 行 N 列的一个表数据. MySQL 表子查询实例 下面是用于例子的两张原始数据表: article 表: blog 表: SQL 如下: SELECT * FROM article WHERE (title,content,uid) IN (SELECT title,content,uid FROM blog) 查询返回结果如下所示: 该 SQL 的意义在于查找 article 表中指定的字段同时也存在于 blog 表中的所有的行(注
-
详解MySQL索引原理以及优化
前言 本文是美团一位大佬写的,还不错拿出来和大家分享下,代码中嵌套在html中sql语句是java框架的写法,理解其sql要执行的语句即可. 背景 MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能出色,但所谓"好马配好鞍",如何能够更好的使用它,已经成为开发工程师的必修课,我们经常会从职位描述上看到诸如"精通MySQL"."SQL语句优化"."了解数据库原理"等要求.我