JavaScript处理XML DOM、XPath和XSLT方法详解
目录
- 一、浏览器对XML DOM的支持
- 1、将XML解析为DOM文档
- 2、将DOM文档序列化为XML文档
- 二、浏览器对XPath的支持
- 三、浏览器对使用XSLT的支持
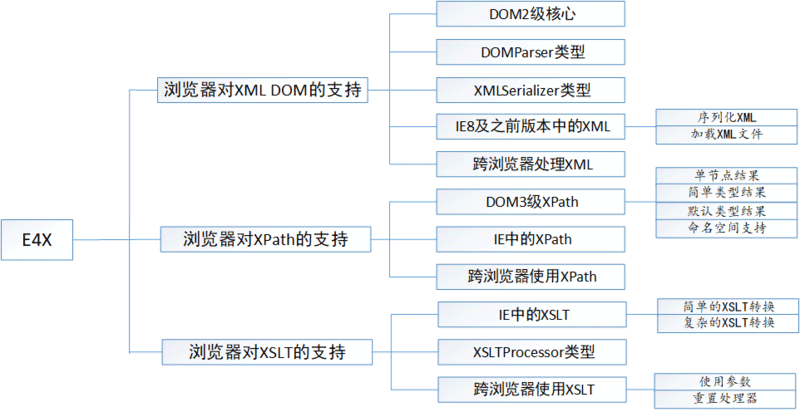
一、浏览器对XML DOM的支持
1、将XML解析为DOM文档
跨浏览器把XML解析为DOM文档:
这个 parseXml()函数只接收一个参数,即可解析的 XML 字符串。
function parseXml(xml) {
var xmldom = null;
if (typeof DOMParser != "undefined") {
xmldom = (new DOMParser()).parseFromString(xml, "text/xml");
var errors = xmldom.getElementsByTagName("parsererror");
if (errors.length) {
throw new Error("XML parsing error:" + errors[0].textContent);
}
} else if (typeof ActiveXObject != "undefined") {
xmldom = createDocument();
xmldom.loadXML(xml);
if (xmldom.parseError != 0) {
throw new Error("XML parsing error: " + xmldom.parseError.reason);
}
} else {
throw new Error("No XML parser available.");
}
return xmldom;
}
2、将DOM文档序列化为XML文档
跨浏览器将DOM文档序列化为XML文档:
这个 serializeXml()函数接收一个参数,即要序列化的 XML DOM 文档。
function serializeXml(xmldom) {
if (typeof XMLSerializer != "undefined") {
return (new XMLSerializer()).serializeToString(xmldom);
} else if (typeof xmldom.xml != "undefined") {
return xmldom.xml;
} else {
throw new Error("Could not serialize XML DOM.");
}
}
二、浏览器对XPath的支持
跨浏览器使用XPath:重新创建 selectSingleNode()和selectNodes()方法。
命名空间对象应该是下面这种字面量的形式。
{
prefix1: "uri1",
prefix2: "uri2",
prefix3: "uri3"
}
selectSingleNode和selectNodes函数接收三个参数:上下文节点、 XPath表达式和可选的命名空间对象。
selectSingleNode:
function selectSingleNode(context, expression, namespaces) {
var doc = (context.nodeType != 9 ? context.ownerDocument: context);
if (typeof doc.evaluate != "undefined") {
var nsresolver = null;
if (namespaces instanceof Object) {
nsresolver = function(prefix) {
return namespaces[prefix];
};
}
var result = doc.evaluate(expression, context, nsresolver, XPathResult.FIRST_ORDERED_NODE_TYPE, null);
return (result !== null ? result.singleNodeValue: null);
} else if (typeof context.selectSingleNode != "undefined") {
//create namespace string
if (namespaces instanceof Object) {
var ns = "";
for (var prefix in namespaces) {
if (namespaces.hasOwnProperty(prefix)) {
ns += "xmlns:" + prefix + "='" + namespaces[prefix] + "' ";
}
}
doc.setProperty("SelectionNamespaces", ns);
}
return context.selectSingleNode(expression);
} else {
throw new Error("No XPath engine found.");
}
}
//调用
var result = selectSingleNode(xmldom.documentElement, "wrox:book/wrox:author", { wrox: <a href="http://www.wrox.com/" rel="external nofollow" rel="external nofollow" target="_blank">http://www.wrox.com/</a>});
alert(serializeXml(result));
selectNodes:
function selectNodes(context, expression, namespaces) {
var doc = (context.nodeType != 9 ? context.ownerDocument: context);
if (typeof doc.evaluate != "undefined") {
var nsresolver = null;
if (namespaces instanceof Object) {
nsresolver = function(prefix) {
return namespaces[prefix];
};
}
var result = doc.evaluate(expression, context, nsresolver, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null);
var nodes = new Array();
if (result !== null) {
for (var i = 0,
len = result.snapshotLength; i < len; i++) {
nodes.push(result.snapshotItem(i));
}
}
return nodes;
} else if (typeof context.selectNodes != "undefined") {
//create namespace string
if (namespaces instanceof Object) {
var ns = "";
for (var prefix in namespaces) {
if (namespaces.hasOwnProperty(prefix)) {
ns += "xmlns:" + prefix + "='" + namespaces[prefix] + "' ";
}
}
doc.setProperty("SelectionNamespaces", ns);
}
var result = context.selectNodes(expression);
var nodes = new Array();
for (var i = 0,
len = result.length; i < len; i++) {
nodes.push(result[i]);
}
return nodes;
} else {
throw new Error("No XPath engine found.");
}
}
//调用
var result = selectNodes(xmldom.documentElement, "wrox:book/wrox:author", {wrox: <a href="http://www.wrox.com/" rel="external nofollow" rel="external nofollow" target="_blank">http://www.wrox.com/</a>});
alert(result.length);
三、浏览器对使用XSLT的支持
跨浏览器使用XSLT样式表转换XML文档
这个 transform()函数接收两个参数:要执行转换的上下文节点和 XSLT 文档对象。
function transform(context, xslt) {
if (typeof XSLTProcessor != "undefined") {
var processor = new XSLTProcessor();
processor.importStylesheet(xslt);
var result = processor.transformToDocument(context);
return (new XMLSerializer()).serializeToString(result);
} else if (typeof context.transformNode != "undefined") {
return context.transformNode(xslt);
} else {
throw new Error("No XSLT processor available.");
}
}
到此这篇关于JavaScript处理XML DOM、XPath和XSLT的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
简单了解JavaScript操作XPath的一些基本方法
Xpath现在很少被我们使用,因为JSON现在很盛行.可是在XML做为数据交换格式的年代,Xpath在我们随机访问大的xml文档结构的时候扮演着非常重要的位置.也许大家现在很多没有注意到,DOM Level 3 XPath指定的接口已经被Firefox,Safari, Chrome, and Opera实现了.他们所实现的核心接口就是XPathEvaluator,它包含一些能够使用xpath表达式进行工作的方法,最主要的方法就是evaluate(),它能够接受五个参数1.xpath查询字符串2.
-
js中使用DOM复制(克隆)指定节点名数据到新的XML文件中的代码
复制代码 代码如下: <?php /* <?xml version="1.0" encoding="utf-8"?> <article> <item> <title name="t1"></title> <content>content1</content> <pubdate>2009-10-11</pubdate> </ite
-
Javascript里使用Dom操作Xml
看了一天的XML资料,感觉CSDN上这篇讲的挺细致的.即有Dot Net写入XML文件的示例,又有JS读取的示例,值得一看.(Source:http://blog.csdn.net/flypigluo) 一.本笔记使用的Xml文件 二.IXMLDOMDocument/DOMDocument简介 2.1 属性 2.1.1 parseError 2.1.2 async. 2.1.3 xml 2.1.4 text3 2.1.5 attributes 2.1.6 nodeName
-
兼容Firefox的Javascript XSLT 处理XML文件
最近使用Firefox进行网页的调试,发现有些Javascript XSLT处理XML的语句仅仅支持IE浏览器.而网络中的一些介绍javascript XSLT 处理XML的文章基本上都是依据AJAX来做的. 无奈中,自己写了一个Javascript XSLT处理XML展现页面的小功能.现在帖出来和大家共享,希望大家给点改进意见. 在Firefox中使用XSLTProcessor对象处理XML,主要使用该对象的两个方法: 一.transformToFragment(). 二.transf
-
javascript下有关dom以及xml节点访问兼容问题
最近整理浏览器兼容的问题,搞的实在头大,在前人的帮助之下,还是有点进展,下面帖一些代码,我想会比较有用 复制代码 代码如下: var isIE = ????; // 全局变量,判断是否ie,自完善 // new dom 方法 function parseXML(st){ if (isIE){ var result = new ActiveXObject( "microsoft.XMLDOM" ); result
-

JavaScript处理XML DOM、XPath和XSLT方法详解
目录 一.浏览器对XML DOM的支持 1.将XML解析为DOM文档 2.将DOM文档序列化为XML文档 二.浏览器对XPath的支持 三.浏览器对使用XSLT的支持 一.浏览器对XML DOM的支持 1.将XML解析为DOM文档 跨浏览器把XML解析为DOM文档: 这个 parseXml()函数只接收一个参数,即可解析的 XML 字符串. function parseXml(xml) { var xmldom = null; if (typeof DOMParser != "undefined
-
JavaScript中BOM,DOM和事件的用法详解
目录 BOM 概念 对象组成 Window:窗口对象 Location:地址栏对象 History:历史记录对象 DOM 概念 W3C DOM 标准被分为 3 个不同的部分 核心DOM模型 HTML DOM 事件监听机制 概念 常见的事件 事件简单学习 BOM 概念 BOM全称Browser Object Model浏览器对象模型,将浏览器的各个组成部分封装成对象. 对象组成 Window:窗口对象 Navigator:浏览器对象 Screen:显示器屏幕对象 History:历史记录对象 Lo
-
JavaScript中windows.open()、windows.close()方法详解
windows.open()方法详解: window.open(URL,name,features,replace)用于载入指定的URL到新的或已存在的窗口中,并返回代表新窗口的Window对象.它有4个可选的 参数: URL:一个可选的字符串,声明了要在新窗口中显示的文档的 URL.如果省略了这个参数,或者它的值是空字符串,那么新窗口就不会显示任何文档. name:一个可选的字符串,该字符串是一个由逗号分隔的特征列表,其中包括数字.字母和下划线,该字符声明了新窗口的名称.这个名称可以用作标记
-
基于JavaScript中字符串的match与replace方法(详解)
1.match方法 match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配. match()方法的返回值为:存放匹配结果的数组. 2.replace方法 replace() 方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串. replace方法的返回值为:一个新的字符串. 3.说明 以上2个方法的参数在使用正则表达式时主要添加全局g,这样才能对字符串进行全部匹配或者替换. 示例代码: <!DOCTYPE html> <html lang
-
对python修改xml文件的节点值方法详解
这是我的xml文件结构 <?xml version='1.0' encoding='utf-8'?> <annotation> <folder>JPEGImages</folder> <filename>train_2018-05-08_1000.jpg</filename> <path>D:\all_data\2018-05-08\JPEGImages\train_2018-05-08_1000.jpg</path
-
C++ OpenCV读写XML或YAML文件的方法详解
目录 前言 1.如何使用 1.1第一步:XML.YAML文件的打开 1.2 第二步:进行文件读写操作 1.3 第三步:vector(array)和map的输入和输出 1.4 第四步:文件关闭 2.代码展示 2.1 写文件 2.2 读文件 2.3 完整的示例代码 前言 本节我们将认识XML和YAML这两种文件类型. 所谓XML,即eXtensible Markup Language,翻译成中文为“可扩展标识语言”.首先,XML是一种元标记语言.所谓元标记,就是开发者可以根据自身需要定义自己的标记,
-
JavaScript实现事件总线(Event Bus)的方法详解
目录 介绍 原理 分析 进阶 1. 如何在发送消息时传递参数 2. 订阅后如何取消订阅 3. 如何只订阅一次 4. 如何清除某个事件或者所有事件 5. TypeScript 版本 6. 单例模式 总结 介绍 Event Bus 事件总线,通常作为多个模块间的通信机制,相当于一个事件管理中心,一个模块发送消息,其它模块接受消息,就达到了通信的作用. 比如,Vue 组件间的数据传递可以使用一个 Event Bus 来通信,也可以用作微内核插件系统中的插件和核心通信. 原理 Event Bus 本质上
-
JavaScript判断两个值相等的方法详解
目录 前言 非严格相等 严格相等 同值零 同值 总结 前言 在 JavaScript 中如何判断两个值相等,这个问题看起来非常简单,但并非如此,在 JavaScript 中存在 4 种不同的相等逻辑,如果你不知道他们的区别,或者认为判断相等非常简单,那么本文非常适合你阅读. ECMAScript 是 JavaScript 的语言规范,在ECMAScript 规范中存在四种相等算法,如下图所示: 上图中四种算法对应的中文名字如下,大部分前端应该熟悉严格相等和非严格相等,但对于同值零和同值却不熟悉,
-
JavaScript React如何修改默认端口号方法详解
问题 我们在使用React的时候经常会遇到这种情况,3000端口号被占用.有时候可以关掉3000端口,但更多时候,我们需要打开多个项目的时候,就必须要开启多个端口了.这时候就需要修改默认端口号了. 解决办法 修改默认端口号 具体做法 第一步:找到start.js文件 这个文件的位置在:node_modules文件夹下 -> react-scripts文件夹下 -> scripts文件夹下 -> start.js node_modules下 start.js文件 51行处修改,整个文件端口
-
Android平台基于Pull方式对XML文件解析与写入方法详解
本文详细讲述了Android平台基于Pull方式对XML文件解析与写入方法.分享给大家供大家参考,具体如下: XML技术在跨平台的情况下的数据交互中得到了广泛的应用,假如我们需要开发一个Android应用程序,需要同服务器端进行数据交互,通过XML文件可以很方便的在Android平台和服务器之间进行数据传输,具体实现涉及到对XML文件进行解析及写入的技术.本文实现在Android平台上基于Pull方式对XML文件解析的技术. XmlPullParser是一个Java实现的开源API包(源码下载地