Java C++ 算法题解leetcode652寻找重复子树
目录
- 题目要求
- 思路一:DFS+序列化
- Java
- C++
- Rust
- 思路二:DFS+三元组
- Java
- C++
- Rust
- 总结
题目要求
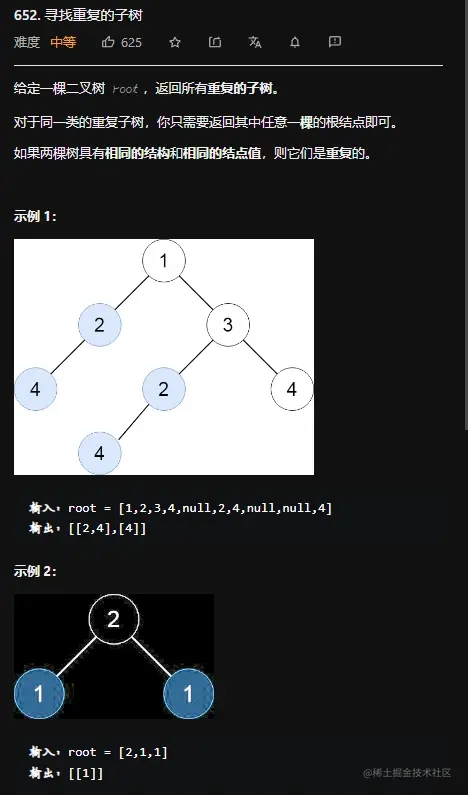
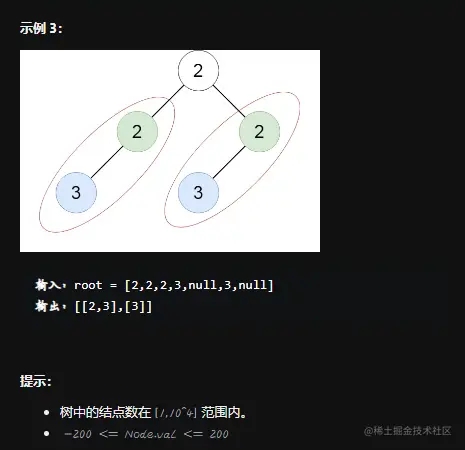
思路一:DFS+序列化
- 设计一种规则将所有子树序列化,保证不同子树的序列化字符串不同,相同子树的序列化串相同。
- 用哈希表存所有的字符串,统计出现次数即可。
- 定义map中的关键字(
key)为子树的序列化结果,值(value)为出现次数。
- 定义map中的关键字(
- 此处采用的方式是在DFS遍历顺序下的每个节点后添加"-",遇到空节点置当前位为空格。
Java
class Solution {
Map<String, Integer> map = new HashMap<>();
List<TreeNode> res = new ArrayList<>();
public List<TreeNode> findDuplicateSubtrees(TreeNode root) {
DFS(root);
return res;
}
String DFS(TreeNode root) {
if (root == null)
return " ";
StringBuilder sb = new StringBuilder();
sb.append(root.val).append("-");
sb.append(DFS(root.left)).append(DFS(root.right));
String sub = sb.toString(); // 当前子树
map.put(sub, map.getOrDefault(sub, 0) + 1);
if (map.get(sub) == 2) // ==保证统计所有且只记录一次
res.add(root);
return sub;
}
}
- 时间复杂度:O(n^2)
- 空间复杂度:O(n)
C++
- 要把节点值转换为字符串格式……呜呜呜卡了半天才意识到
class Solution {
public:
unordered_map<string, int> map;
vector<TreeNode*> res;
vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {
DFS(root);
return res;
}
string DFS(TreeNode* root) {
if (root == nullptr)
return " ";
string sub = "";
sub += to_string(root->val); // 转换为字符串!!!
sub += "-";
sub += DFS(root->left);
sub += DFS(root->right);
if (map.count(sub))
map[sub]++;
else
map[sub] = 1;
if (map[sub] == 2) // ==保证统计所有且只记录一次
res.emplace_back(root);
return sub;
}
};
- 时间复杂度:O(n^2)
- 空间复杂度:O(n)
Rust
- 在判定等于222的地方卡了好久,报错
borrow of moved value sub,没认真学rust导致闭包没搞好,然后根据报错内容猜了下,把上面的加了个clone()果然好了。
use std::rc::Rc;
use std::cell::RefCell;
use std::collections::HashMap;
impl Solution {
pub fn find_duplicate_subtrees(root: Option<Rc<RefCell<TreeNode>>>) -> Vec<Option<Rc<RefCell<TreeNode>>>> {
let mut res = Vec::new();
fn DFS(root: &Option<Rc<RefCell<TreeNode>>>, map: &mut HashMap<String, i32>, res: &mut Vec<Option<Rc<RefCell<TreeNode>>>>) -> String {
if root.is_none() {
return " ".to_string();
}
let sub = format!("{}-{}{}", root.as_ref().unwrap().borrow().val, DFS(&root.as_ref().unwrap().borrow().left, map, res), DFS(&root.as_ref().unwrap().borrow().right, map, res));
*map.entry(sub.clone()).or_insert(0) += 1;
if map[&sub] == 2 { // ==保证统计所有且只记录一次
res.push(root.clone());
}
sub
}
DFS(&root, &mut HashMap::new(), &mut res);
res
}
}
- 时间复杂度:O(n^2)
- 空间复杂度:O(n)
思路二:DFS+三元组
- 和上面其实差不多,三元组本质上也是一种序列化形式,可以指代唯一的子树结构:
- 三元组中的内容为(根节点值,左子树标识,右子树标识)(根节点值, 左子树标识,右子树标识)(根节点值,左子树标识,右子树标识);
- 这个标识是给每个不同结构的子树所赋予的唯一值,可用于标识其结构。
- 所以三元组相同则判定子树结构相同;
- 该方法使用序号标识子树结构,规避了思路一中越来越长的字符串,也减小了时间复杂度。
- 三元组中的内容为(根节点值,左子树标识,右子树标识)(根节点值, 左子树标识,右子树标识)(根节点值,左子树标识,右子树标识);
- 定义哈希表mapmapmap存储每种结构:
- 关键字为三元组的字符串形式,值为当前子树的标识和出现次数所构成的数对。
- 其中标识用从000开始的整数flagflagflag表示。
Java
class Solution {
Map<String, Pair<Integer, Integer>> map = new HashMap<String, Pair<Integer, Integer>>();
List<TreeNode> res = new ArrayList<>();
int flag = 0;
public List<TreeNode> findDuplicateSubtrees(TreeNode root) {
DFS(root);
return res;
}
public int DFS(TreeNode root) {
if (root == null)
return 0;
int[] tri = {root.val, DFS(root.left), DFS(root.right)};
String sub = Arrays.toString(tri); // 当前子树
if (map.containsKey(sub)) { // 已统计过
int key = map.get(sub).getKey();
int cnt = map.get(sub).getValue();
map.put(sub, new Pair<Integer, Integer>(key, ++cnt));
if (cnt == 2) // ==保证统计所有且只记录一次
res.add(root);
return key;
}
else { // 首次出现
map.put(sub, new Pair<Integer, Integer>(++flag, 1));
return flag;
}
}
}
- 时间复杂度:O(n)
- 空间复杂度:O(n)
C++
class Solution {
public:
unordered_map<string, pair<int, int>> map;
vector<TreeNode*> res;
int flag = 0;
vector<TreeNode*> findDuplicateSubtrees(TreeNode* root) {
DFS(root);
return res;
}
int DFS(TreeNode* root) {
if (root == nullptr)
return 0;
string sub = to_string(root->val) + to_string(DFS(root->left)) + to_string(DFS(root->right)); // 当前子树
if (auto cur = map.find(sub); cur != map.end()) { // 已统计过
int key = cur->second.first;
int cnt = cur->second.second;
map[sub] = {key, ++cnt};
if (cnt == 2) // ==保证统计所有且只记录一次
res.emplace_back(root);
return key;
}
else { // 首次出现
map[sub] = {++flag, 1};
return flag;
}
}
};
- 时间复杂度:O(n)
- 空间复杂度:O(n)
Rust
- 三元组不好搞,所以用了两个二元哈希表替代一个存放三元组和标识,另一个存放标识与出现次数。
use std::rc::Rc;
use std::cell::RefCell;
use std::collections::HashMap;
impl Solution {
pub fn find_duplicate_subtrees(root: Option<Rc<RefCell<TreeNode>>>) -> Vec<Option<Rc<RefCell<TreeNode>>>> {
let mut res = Vec::new();
fn DFS(root: &Option<Rc<RefCell<TreeNode>>>, sub_flag: &mut HashMap<String, i32>, flag_cnt: &mut HashMap<i32, i32>, res: &mut Vec<Option<Rc<RefCell<TreeNode>>>>, flag: &mut i32) -> i32 {
if root.is_none() {
return 0;
}
let (lflag, rflag) = (DFS(&root.as_ref().unwrap().borrow().left, sub_flag, flag_cnt, res, flag), DFS(&root.as_ref().unwrap().borrow().right, sub_flag, flag_cnt, res, flag));
let sub = format!("{}{}{}", root.as_ref().unwrap().borrow().val, lflag, rflag);
if sub_flag.contains_key(&sub) { // 已统计过
let key = sub_flag[&sub];
let cnt = flag_cnt[&key] + 1;
flag_cnt.insert(key, cnt);
if cnt == 2 { // ==保证统计所有且只记录一次
res.push(root.clone());
}
key
}
else { // 首次出现
*flag += 1;
sub_flag.insert(sub, *flag);
flag_cnt.insert(*flag, 1);
*flag
}
}
DFS(&root, &mut HashMap::new(), &mut HashMap::new(), &mut res, &mut 0);
res
}
}
- 时间复杂度:O(n)
- 空间复杂度:O(n)
总结
两种方法本质上都是基于哈希表,记录重复的子树结构并统计个数,在超过111时进行记录,不过思路二更巧妙地将冗长的字符串变为常数级的标识符。
以上就是Java C++ 算法题解leetcode652寻找重复子树的详细内容,更多关于Java C++ 寻找重复子树的资料请关注我们其它相关文章!
相关推荐
-

Java C++ 算法题解leetcode669修剪二叉搜索树示例
目录 题目要求 思路一:模拟迭代 Java C++ 思路二:递归 Java C++ Rust 题目要求 思路一:模拟迭代 依次判断每个节点是否合法: 首先找出结果的根,若原根小了就拉右边的过来,大了拉左边的过来做新根: 然后分别判断左右子树的大小,由于二叉搜索树的性质,子树只需要判断一边就好: 左子树判断是否>low,合法就向左下走,不合法往右下: 右子树判断是否<high,合法就向右下走,不合法往左下. Java class Solution { public TreeNode trimBS
-
Java C++题解leetcode672灯泡开关示例
目录 题目要求 思路:找规律 Java C++ Rust 总结 题目要求 思路:找规律 找到尽可能最精简的通项表达,今日参考:京城打工人 首先,归纳每个开关会影响的灯,其中(k=0,1,2,…): 开关 反转灯编号 一 k 二 2k 三 2k+1 四 3k+1 可见灯以6盏为周期具有相同变化,所以以下只需要推导第一个周期里的6盏灯即可. 观察前6盏灯: 灯 开关 1 一.三.四 2 一.二 3 一.三 4 一.二.四 5 一.三 6 一.二 发现灯2.6和3.5分别受同样的开关影响,所以状态相同
-
Java C++算法题解leetcode1592重新排列单词间的空格
目录 题目要求 思路:模拟 Java C++ Rust 题目要求 思路:模拟 模拟就完了 统计空格数量和单词数量,计算单词间应有的空格数,将它们依次放入结果字符串,若有余数则在末尾进行填补. Java class Solution { public String reorderSpaces(String text) { int n = text.length(), spcnt = 0; List<String> words = new ArrayList<>(); for (int
-
Java C++ 题解leetcode1619删除某些元素后数组均值
目录 题目要求 思路:模拟 Java C++ Rust 题目要求 思路:模拟 根据题意模拟即可: 排序然后只取中间符合条件的数加和然后计算均值: 根据给出的数组长度n为20的倍数,5%可直接取n/20: 两边各去除5%,则剩余长度为0.9n. Java class Solution { public double trimMean(int[] arr) { Arrays.sort(arr); int n = arr.length, tot = 0; for (int i = n / 20; i
-
Java C++ 算法题解leetcode1582二进制矩阵特殊位置
目录 题目要求 思路:模拟 Java C++ Rust 题目要求 思路:模拟 直接按题意模拟,先算出每行每列中“111”的个数,然后判断统计行列值均为111的位置即可. Java class Solution { public int numSpecial(int[][] mat) { int n = mat.length, m = mat[0].length; int res = 0; int[] row = new int[n], col = new int[m]; for (int i =
-
Java C++ 算法题解leetcode145商品折扣后最终价格单调栈
目录 题目要求 思路一:暴力模拟 Java C++ Rust 思路二:单调栈 Java C++ Rust 题目要求 思路一:暴力模拟 由于数据范围不算离谱,所以直接遍历解决可行. Java class Solution { public int[] finalPrices(int[] prices) { int n = prices.length; int[] res = new int[n]; for (int i = 0; i < n; i++) { int discount = 0; fo
-
Java C++ 算法题解leetcode1608特殊数组特征值
目录 题目要求 思路一:枚举 + 二分 Java C++ 思路二:二分枚举 Java C++ 思路三:倒序枚举 Java C++ 题目要求 思路一:枚举 + 二分 逐一枚举值域内的所有值,然后二分判断是否合法. Java class Solution { public int specialArray(int[] nums) { Arrays.sort(nums); int n = nums.length; for (int x = 0; x <= nums[n - 1]; x++) { //
-
Java C++算法题解leetcode801使序列递增的最小交换次数
目录 题目要求 思路:状态机DP 实现一:状态机 Java C++ Rust 实现二:滚动数组 Java C++ Rust 总结 题目要求 思路:状态机DP 实现一:状态机 Java class Solution { public int minSwap(int[] nums1, int[] nums2) { int n = nums1.length; int[][] f = new int[n][2]; for (int i = 1; i < n; i++) f[i][0] = f[i][1]
-
java算法题解Leetcode15三数之和实例
目录 题目 解题思路 题目 15. 三数之和 给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有和为 0 且不重复的三元组. 注意:答案中不可以包含重复的三元组. 示例 1:输入:nums = [-1,0,1,2,-1,-4]输出:[[-1,-1,2],[-1,0,1]]示例 2:输入:nums = []输出:[]示例 3:输入:nums = [0]输出:[]提示:0 <= nums.length <=
-
java数据结构与算法之noDups去除重复项算法示例
本文实例讲述了java数据结构与算法之noDups去除重复项算法.分享给大家供大家参考,具体如下: public static void noDupa(int[] a){ int count = 0;//in int sub = 0;//计数器 for(int i=0; i<a.length-1; i++){//外层循环 if(a[i] != a[i+1]){ a[count] = a[i]; count++; } } } PS:感觉这个算法粗略看下觉得没啥子,实际上相当精妙!!先决条件---数
-
Go Java算法之K个重复字符最长子串详解
目录 至少有K个重复字符的最长子串 方法一:分治(Java) 方法二:滑动窗口(go) 至少有K个重复字符的最长子串 给你一个字符串 s 和一个整数 k ,请你找出 s 中的最长子串, 要求该子串中的每一字符出现次数都不少于 k .返回这一子串的长度. 示例 1: 输入:s = "aaabb", k = 3 输出:3 解释:最长子串为 "aaa" ,其中 'a' 重复了 3 次. 示例 2: 输入:s = "ababbc", k = 2 输出:5
-
java算法题解牛客BM99顺时针旋转矩阵示例
目录 题目描述 解题思路 实践代码 解法1 解法2 题目描述 BM99 顺时针旋转矩阵 描述 有一个NxN整数矩阵,请编写一个算法,将矩阵顺时针旋转90度. 给定一个NxN的矩阵,和矩阵的阶数N,请返回旋转后的NxN矩阵. 数据范围:0<n<300,矩阵中的值满足0≤val≤1000 要求:空间复杂度 O(N^2),时间复杂度 O(N^2) 进阶:空间复杂度 O(1),时间复杂度 O(N^2) 示例1输入:[[1,2,3],[4,5,6],[7,8,9]],3返回值:[[7,4,1],[8,5