MySQL中如何重建表
目录
- 1.删除表数据,为什么表文件大小不变
- 2.删除操作
- 3.新增操作
- 4.重建表
- 总结
1.删除表数据,为什么表文件大小不变
在日常开发中,你会发现当你删除表的数据后,整个数据库文件大小还是没有变化。这就是数据库表的空间回收问题。
首先我们还是针对 MySQL 中应用最广泛的 InnoDB 引擎展开讨论。
一个 InnoDB 表包含两部分,即:表结构定义和数据。
- 在 MySQL 8.0 版本以前,表结构是存在以.frm 为后缀的文件里。
- 而 MySQL 8.0 版本,则已经允许把表结构定义放在系统数据表中了。因为表结构定义占用的空间很小,所以我们今天主要讨论的是表数据。
参数innodb_file_per_table的作用:
- 配置成on,表示每个InnoDB表数据存储在一个.ibd后缀的文件中。
- 配置成off,则表示表的数据存放在系统共享空间,也就是根据数据字典放在一块。
两者的区别就是
- 1.如果表数据是存储在系统共享空间中的,即使删除了表,空间也不会被回收的;
- 2.如果表数据是存储在单个文件中的,通过drop table命令删除的时候就会将数据文件删除掉。
show global variables where Variable_name = 'innodb_file_per_table'
从 MySQL 5.6.6 版本开始,它的默认值就是 ON 了。
- 因为,一个表单独存储为一个文件更容易管理,而且在你不需要这个表的时候,通过 drop table 命令,系统就会直接删除这个文件。
- 而如果是放在共享表空间中,即使表删掉了,空间也是不会回收的。
2.删除操作
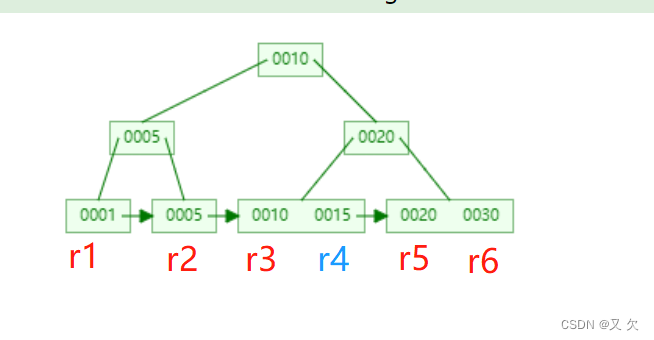
总所周知MySQL数据结构是B+树,现在假设删除掉r4的记录,InnoDB只会把r4这个记录标记为删除,如果之后插入一条10-20的记录,就会复用这个r4的位置,但是磁盘文件的大小并不会因为标记为删除而减小,类似于假删除。
当整个页从B+树里面摘掉以后,可以复用到任何位置,可以存储任何新增的数据。如果相邻的两个数据页利用率都很小,系统就会把这两个页上的数据合到其中一个页上,另外一个数据页就被标记为可复用。
如果我们用delete命令把整个表的数据删除呢?结果就是,所有的数据页都会被标记为可复用。但是磁盘上,文件不会变小。
实际上,delete命令其实只是把记录的位置,或者数据页标记为了“可复用”,但磁盘文件的大小是不会变的。也就是说,通过delete命令是不能回收表空间的。这些可以复用,而没有被使用的空间,看起来就像是“空洞”。
3.新增操作

假设上图PageA满了,我们在新增一条数据8会怎样.
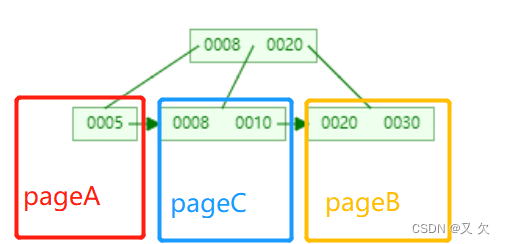
可以看到,由于page A满了,再插入一个ID是8的数据时,就不得不再申请一个新的页面 page C来保存数据了。
页分裂完成后,page A的末尾就留下了空洞(注意:实际上,可能不止1 个记录的位置是空洞)。
另外,更新索引上的值,可以理解为删除一个旧的值,再插入一个新值。不难理解,这也是会造 成空洞的。
也就是说,经过大量增删改的表,都是可能是存在空洞的。
所以,如果能够把这些空洞去掉,就 能达到收缩表空间的目的。 而重建表,就可以达到这样的目的。
4.重建表
方式一:新建一张表结构一样的表
- 1.可以新建一个与表A结构相同的表B,
- 2.然后按照主键ID递增的顺序,把数据一行一行地从表A里读出来再插入到表B中。由于表B是新建的表,所以表A主键索引上的空洞,在表B中就都不存在了。
- 3.显然地,表B的主键 索引更紧凑,数据页的利用率也更高。如果我们把表B作为临时表,数据从表A导入表B的操作完 成后,用表B替换A,从效果上看,就起到了收缩表A空间的作用。
方式二:alter table t engine=innodb,ALGORITHM=copy;(DDL)
可以使用**alter table t engine=innodb,ALGORITHM=copy;**命令来重建表。
在MySQL 5.5版本之前,这个命 令的执行流程跟我们前面描述的差不多,区别只是这个临时表B不需要你自己创建,MySQL会自 动完成转存数据、交换表名、删除旧表的操作。
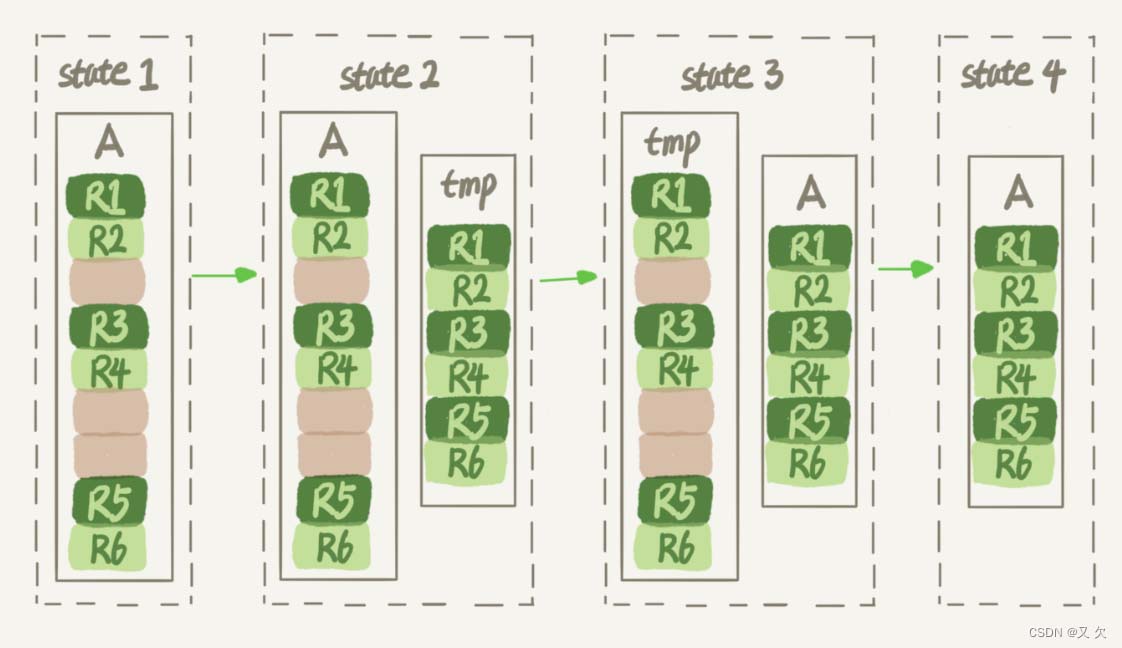
显然,花时间最多的步骤是往临时表插入数据的过程,如果在这个过程中,有新的数据要写入到 表A的话,就会造成数据丢失。因此,在整个DDL过程中,表A中不能有更新。也就是说,这个 DDL不是Online的。
方式三:alter table t engine=innodb,ALGORITHM=inplace;(Online DDL)
而在MySQL 5.6 M 版本开始引入的 版 Online DDL,之前的sql语句就变为了alter table t engine=innodb,ALGORITHM=inplace;
- 1.建立一个临时文件,扫描表A主键的所有数据页;
- 2.用数据页中表A的记录生成B+树,存储到临时文件中;
- 3.生成临时文件的过程中,将所有对A的操作记录在一个日志文件(rowlog)中,对应的是图 中state2的状态;
- 4.临时文件生成后,将日志文件中的操作应用到临时文件,得到一个逻辑数据上与表A相同的数据文件.
- 5.用临时文件替换表A的数据文件。
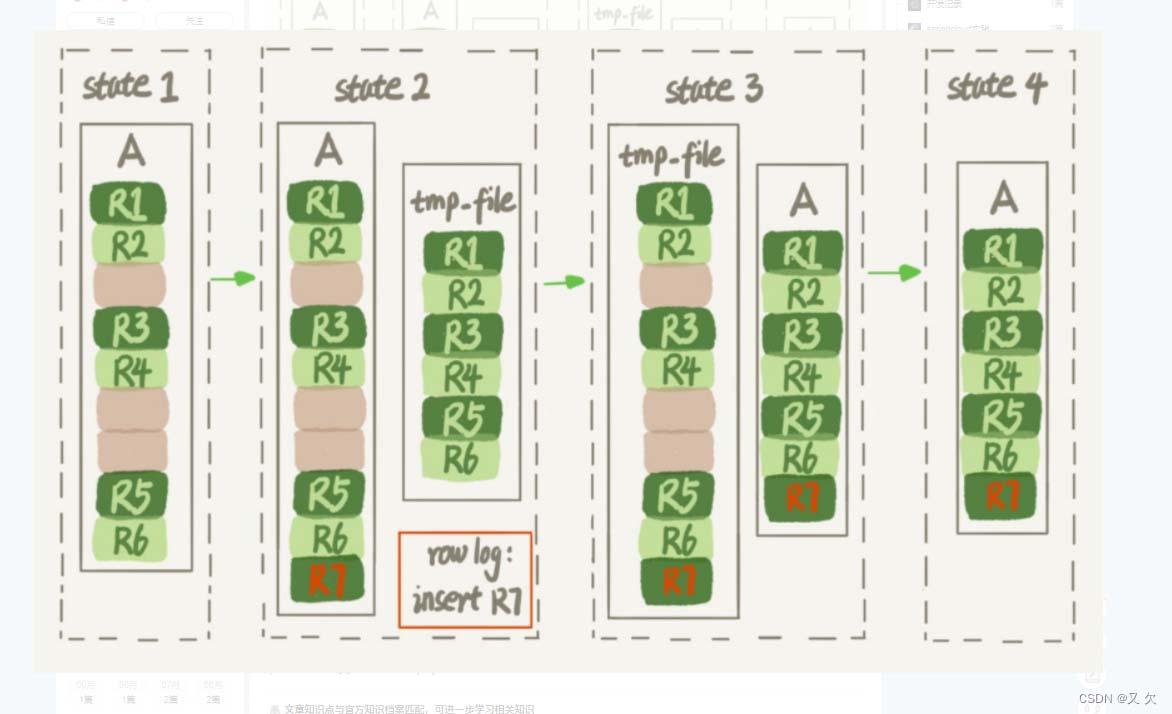
引入Online DDL的区别就是由于日志文件记录和重放操作这个功能的存在,这个方 案在重建表的过程中,允许对表A做增删改操作。这也就是Online DDL名字的来源。
在执行 alter table t engine=innodb,ALGORITHM=inplace; 语句的时候,需要获取到MDL锁,但是这个写锁在真正拷贝数据 之前就退化成读锁了。
Online DDL 其实是会先获取MDL写锁, 再退化成MDL读锁;但MDL写锁持有时间比较短,所以可以称为Online; 而MDL读锁,不阻止数据增删查改,但会阻止其它线程修改表结构;
- 1.拿MDL写锁
- 2.降级成MDL读锁
- 3.真正做DDL
- 4.升级成MDL写锁
- 5.释放MDL锁 1、2、4、5如果没有锁冲突,执行时间非常短。第3步占用了DDL绝大部分时间,这期间这个表可以正常读写数据,是因此称为“online
为什么要退化呢?为了实现Online,MDL读锁不会阻塞增删改操作。
那为什么不干脆直接解锁呢?为了保护自己,禁止其他线程对这个表同时做DDL。
区别:
两者的区别就是
- 方式二是根据源表重建出来的数据是存在临时表中的(tmp:“tmp_table”),表示的是强拷贝表,是将源表中重建的数据存放在一个临时表中,这个临时表是在server层中创建的。
- 方式三是根据源表重建出来的数据是存在临时文件中的(tmp_file),这个临时文件是InnoDB创建的,这个过程是在引擎层中发生的,对于server层来说就相当于原地操作的
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Mysql脏页flush及收缩表空间原理解析
mysql脏页 由于WAL机制,InnoDB在更新语句的时候,制作了写日志这一个磁盘操作,就是redo log,在内存写完redo log后,就返回给客户端, 即更新成功. 把内存里的数据写入磁盘的过程,术语就是flush,在flush之前,实际数据和数据库中的数据是不一致的,因为在redo log基础上更新了还未写入,数据库是老的,当内存数据页跟磁盘数据页内容不一致的时候,称这个内存页为脏页,内存写入后就一致了,称为干净页, 如果mysql偶尔运行速度很慢,很可能是在刷脏页.引发数据库flus
-

MySQL中修改表结构时需要注意的一些地方
MySql 在修改表结构的时候可能会中断产品的正常运行影响用户体验,甚至更坏的结果,丢失数据.不是所有的数据库管理员.程序员.系统管理员都非常了解Mysql能避免这种情况.DBA会经常碰到这种生产中断的情况,当升级脚本修改了应用层和数据库层,或者缺乏经验的管理员.开发在不是很了解Mysql内部工作机制的情况下修改了规范文件. 真相是: 直接修改表结构的过程中会锁表(在5.6版本之前) 在线的数据定义语言在5.6版本不总是在线的而且也会锁表 就算使用Percona工具包(在线修改定义文件)也会有若
-
MySQL 表空间碎片的概念及相关问题解决
背景 经常使用 MySQL 的话,会发现 MySQL 数据文件的磁盘空间一般会不停的增长,而且有时候删了数据或者插入一批数据的时候,磁盘空间有时候还会毫无变化.引发这个其妙现象的就是 MySQL 的表空间碎片. 什么是表空间碎片? 表空间碎片指的是表空间中存在碎片,形象一点来比喻的话,就像是一张 A4 纸,"表空间碎片"就像是把这张 A4 纸撕碎,再重新拼起来,各个碎片之间都会有一些缝隙存在,这些缝隙就是"表空间碎片".重新拼起来的碎片实际上会比完整的 A4 纸大上
-
MySQL中如何重建表
目录 1.删除表数据,为什么表文件大小不变 2.删除操作 3.新增操作 4.重建表 总结 1.删除表数据,为什么表文件大小不变 在日常开发中,你会发现当你删除表的数据后,整个数据库文件大小还是没有变化.这就是数据库表的空间回收问题. 首先我们还是针对 MySQL 中应用最广泛的 InnoDB 引擎展开讨论. 一个 InnoDB 表包含两部分,即:表结构定义和数据. 在 MySQL 8.0 版本以前,表结构是存在以.frm 为后缀的文件里. 而 MySQL 8.0 版本,则已经允许把表结构定义放在
-
浅谈MYSQL中树形结构表3种设计优劣分析与分享
目录 简介 问题 设计1:邻接表 表设计 SQL示例 设计2:路径枚举 表设计 SQL示例 设计3:闭包表 表设计 SQL示例 结合使用 表设计 总结 简介 在开发中经常遇到树形结构的场景,本文将以部门表为例对比几种设计的优缺点: 问题 需求背景:根据部门检索人员, 问题:选择一个顶级部门情况下,跨级展示当前部门以及子部门下的所有人员,表怎么设计更合理 ? 递归吗 ?递归可以解决,但是势必消耗性能 设计1:邻接表 注:(常见父Id设计) 表设计 CREATE TABLE `dept_info01
-
MySQL中的全表扫描和索引树扫描 的实例详解
目录 引言 实例 引言 在学习mysql时,我们经常会使用explain来查看sql查询的索引等优化手段的使用情况.在使用explain时,我们可以观察到,explain的输出有一个很关键的列,它就是type属性,type表示的是扫描方式,代表 MySQL 使用了哪种索引类型,不同的索引类型的查询效率是不一样的. 在type这一列,有如下一些可能的选项: system:系统表,少量数据,往往不需要进行磁盘IOconst:常量连接eq_ref:主键索引(primary key)或者非空唯一索引(u
-
MySQL中dd::columns表结构转table过程及应用详解
目录 一.MySQL的dd表介绍 二.代码跟踪 三.知识应用 四.总结 一.MySQL的dd表介绍 MySQL的dd表是用来存放表结构和各种建表信息的,客户端建的表都存在mysql.table和mysql.columns表里,还有一个表mysql.column_type_elements比较特殊,用来存放SET和ENUM类型的字段集合值信息.看一下下面这张表的mysql.columns表和mysql.column_type_elements信息.为了缩短显示长度,这里只展示几个重要的值. #建表
-
在MySQL中操作克隆表的教程
可能有一种情况,当需要一个完全相同的副本表CREATE TABLE ... SELECT不适合需要,因为副本必须包含相同的索引,默认值,依此类推. 按下面的步骤,可以处理这种情况. 使用SHOW CREATE TABLE得到一个CREATE TABLE语句中指定源表的结构,索引等. 修改语句更改表名称的克隆表,并执行该语句.通过这种方式将有确切的克隆表. 或者,如果需要进行表的内容复制,使用INSERT INTO ... SELECT语句也可以搞定. 实例: 试试下面的例子来创建一个克隆表tut
-
MySQL中的回表和索引覆盖示例详解
目录 索引类型 索引结构 非聚簇索引查询 索引覆盖 总结 索引类型 聚簇索引: 叶子节点存储的是行记录,每个表必须要有至少一个聚簇索引.使用聚簇索引查询会很快,因为可以直接定位到行记录 普通索引:二级索引,除聚簇索引外的索引,即非聚簇索引.普通索引叶子节点存储的是主键(聚簇索引)的值. 聚簇索引递推规则: 如果表设置了主键,则主键就是聚簇索引 如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚簇索引 以上都没有,则会默认创建一个隐藏的row_id作为聚簇索引 索引结
-
MySQL中复制数据表中的数据到新表中的操作教程
MySQL是不支持SELECT - INTO语法的,使用INSERT INTO - SELECT替代相同用法,下面我们我们这里简答分一下新表存在和不存在两种情况,具体使用不同的语句. 1.新表不存在 复制表结构即数据到新表 create table new_table select * from old_talbe; 这种方法会将old_table中所有的内容都拷贝过来,用这种方法需要注意,new_table中没有了old_table中的primary key,Extra,auto_increm
-
MySql中把一个表的数据插入到另一个表中的实现代码
小编今天在写一个 将一个数据库的表数据 导入到 另一个数据库的表的时候 我是这么写的 复制代码 代码如下: <?php header("Content-type:text/html;charset=utf-8"); $conn = mysql_connect("localhost","root","");mysql_select_db('nnd',$conn);mysql_select_db('ahjk',$conn);
-
MySql中删除数据表的方法详解
目录 定义: 1 删除一个或多个没有被其他表关联的数据表 1.1 新建一张表 1.2 执行删除命令 1.3 结果检查 2 删除被其他表关联的主表 2.1 创建两张具有关联关系的表 2.2 执行删除DROP TABLE命令 2.3 取消外键关系,再删除. 定义: 删除数据表就是将数据库中已经存在的表从数据库中删除.注意,在删除表的同时,表的定义和表中所有的数据均会被删除.因此,在进行删除操作前,最好对表中的数据做一个备份,以免造成无法挽回的后果.本节将详细讲解数据库表的删除方法. 1 删除一个
-
mysql中如何查看表是否被锁问题
目录 如何查看是否发生死锁 死锁发生情况及原因 产生原因 发生死锁的几种情况 总结 如何查看是否发生死锁 在使用mysql的时候,如何查看表是否被锁呢? 查看表被锁状态和结束死锁步骤: 1.在mysql命令行执行sql语句 use dbName; // 切换到具体数据库 show engine innodb status; // 查询db是否发生死锁 2.查看数据表被锁状态 show OPEN TABLES where In_use > 0; 该语句可以查询到当前锁表的状态 3.分析锁表的SQL