解决sqoop import 导入到hive后数据量变多的问题
使用sqoop import 命令从postgresql导入数据到hive中,发现数据行数变多了,但是任务没有跑错,非常奇怪。
导入语句为:
sqoop import --connect jdbc:postgresql://*.*.*.*:5432/database_name --username name111 --password password111 --table table111 --hive-import --hive-database database111 --hive-table hive_table111 --hive-overwrite --delete-target-dir --hive-drop-import-delims --null-string '' --null-non-string '' -m5
导入前pgsql数据量为3698条,但是导入后再hive中的数据量为3938,数据竟然变多了。最后发现将参数-m5,改为-m1即可解决问题。
为什么呢?
我们先来了解一下参数-m的含义以及sqoop导入的原理。
首先用户输入一个 Sqoop import 命令,Sqoop 会从关系型数据库中获取元数据信息,比如要操作数据库表的 schema是什么样子,这个表有哪些字段,这些字段都是什么数据类型等。它获取这些信息之后,会将输入命令转化为基于 Map 的 MapReduce作业,这样 MapReduce作业中有很多 Map 任务,每个 Map 任务从数据库中读取一片数据,这样多个 Map 任务实现并发的拷贝,把整个数据快速的拷贝到 HDFS 上。
而决定切分成多少个map就是参数-m的作用,-m5代表切分为5个map,-m1代表切分为1个map,即不用切分。
而决定用什么字段来切分,就是用--split-by来制定的。当sqoop import 没有定义--split-by时,默认使用源数据表的key作为切分字段。
split-by 根据不同的参数类型有不同的切分方法,如int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来 确定划分几个区域。比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers(-m)为2的话,则会分成两个区域 (1,500)和(501-1000),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000.最后每个map各自获取各自SQL中的数据进行导入工作。

那回到最开始的问题,为什么切分数目不一样,结果就不一样呢?理论上无论怎么切分,导入的数据都应该是一样的,但现在甚至还多了?这是因为,用来切分的字段不友好,不是int型或者有排序规律的。
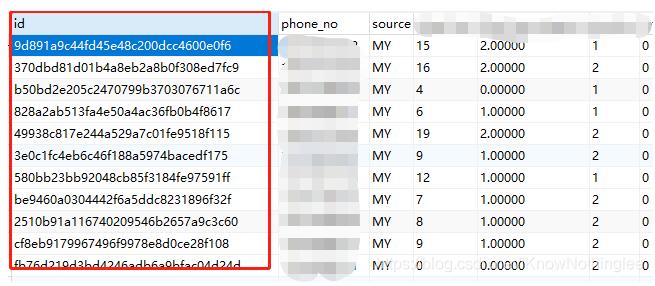
这种id内容是没有排序规则的,比如本来10条id切两份得到(5,5),现在切出来时(5,6),有一个id重复了,就导致数量变多了。
所以解决办法有两个:
一是将 -m5 改成 -m1 直接不切分;
二是 --split-by制定另外的字段,换一个int型的或者有明确排序顺序的字段。
除了以上这种原因导致数据变多,语句缺少 --hive-drop-import-delims 也可能导致问题的出现,解决如下:
关于在sqoop导入数据的时候,数据量变多的解决方案。
今天使用sqoop导入一张表,我去查数据库当中的数据量为650条数据,但是我将数据导入到hive表当中的时候出现了563条数据,这就很奇怪了,我以为是数据错了,然后多导入了几次数据发现还是一样的问题。
然后我去查数据字段ID的值然后发现建了主键的数据怎么可能为空的那。然后我去看数据库当中的数据发现,数据在存入的时候不知道加入了什么鬼东西,导致数据从哪一行截断了,导致多出现了三条数据。下面是有问题的字段。

这里我也不知道数据为啥会是这样,我猜想是在导入数据的时候hive默认行的分割符号是按照\n的形式导入进来的,到这里遇到了这样的字符就对其按照下一行进行对待将数据截断了。
然后我测试了一直自定义的去指定hive的行的分割符号,使用--lines-terminated-by 指定hive的行的分割符号,但是不幸的是好像这个是不能改的。他会报下面的错误:
FAILED: SemanticException 1:424 LINES TERMINATED BY only supports newline '\n' right now. Error encountered near token ''\164'' 于是上网找资料,然后发现可以使用一个配置清除掉hive当中默认的分割符号,然后导入数据,配置如下: --hive-drop-import-delims 这个参数是去掉hive默认的分割符号,加上这个参数然后在使用--fields-terminated-by 指定hive的行的分割符号 最终数据导入成功,数据量和原来数库当中的数据一致。

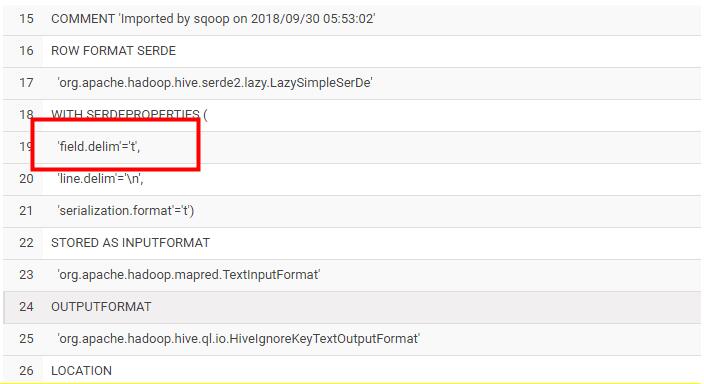
上面是sqoop脚本的部分内容,下面是执行完hive之后,hive创建的表,字段之间默认的分割符号。
至此问题得到了解决。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
Postgresql 检查数据库主从复制进度的操作
如何查看主从复制的状态,且备库应用落后了多少字节 这些信息要在主库中查询 查看流复制的信息可以使用主库上的视图 select pid,state,client_addr,sync_priority,sync_state from pg_stat_replication; pg_stat_replication中几个字断记录了发送wal的位置及备库接收到的wal的位置. sent_location--发送wal的位置 write_location--备库接收到的wal的位置 flush_locat
-
postgresql中wal_level的三个参数用法说明
wal_level中有三个主要的参数:minimal.archive和hot_standby 1.minimal是默认的值,它仅写入崩溃或者突发关机时所需要的信息(不建议使用). 2.archive是增加wal归档所需的日志(最常用). 3.hot_standby是在备用服务器上增加了运行只读查询所需的信息,一般实在流复制的时候使用到. 补充:postgresql WAL相关参数 配置文件 # - Settings - wal_level = minimal # minimal, replica
-
sqoop 实现将postgresql表导入hive表
使用sqoop导入数据至hive常用语句 直接导入hive表 sqoop import --connect jdbc:postgresql://ip/db_name --username user_name --table table_name --hive-import -m 5 内部执行实际分三部,1.将数据导入hdfs(可在hdfs上找到相应目录),2.创建hive表名相同的表,3,将hdfs上数据传入hive表中 sqoop根据postgresql表创建hive表 sqoop creat
-
在postgresql数据库中创建只读用户的操作
在pg数据库中创建只读用户可以采用如下方法.大体实现就是将特定schema的相关权限赋予只读用户. --创建用户 CREATE USER readonly WITH ENCRYPTED PASSWORD '123456'; --设置用户默认开启只读事务 ALTER USER readonly SET default_transaction_read_only = ON; --将schema中usage权限赋予给readonly用户,访问所有已存在的表 GRANT usage ON SCHEMA
-
postgresql流复制原理以及流复制和逻辑复制的区别说明
流复制的原理: 物理复制也叫流复制,流复制的原理是主库把WAL发送给备库,备库接收WAL后,进行重放. 逻辑复制的原理: 逻辑复制也是基于WAL文件,在逻辑复制中把主库称为源端库,备库称为目标端数据库,源端数据库根据预先指定好的逻辑解析规则对WAL文件进行解析,把DML操作解析成一定的逻辑变化信息(标准SQL语句),源端数据库把标准SQL语句发给目标端数据库,目标端数据库接收到之后进行应用,从而实现数据同步. 流复制和逻辑复制的区别: 流复制主库上的事务提交不需要等待备库接收到WAL文件后的确认
-

解决sqoop import 导入到hive后数据量变多的问题
使用sqoop import 命令从postgresql导入数据到hive中,发现数据行数变多了,但是任务没有跑错,非常奇怪. 导入语句为: sqoop import --connect jdbc:postgresql://*.*.*.*:5432/database_name --username name111 --password password111 --table table111 --hive-import --hive-database database111 --hive-tab
-
解决sqoop从postgresql拉数据,报错TCP/IP连接的问题
问题: sqoop从postgresql拉数据,在执行到mapreduce时报错Connection refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections 问题定位过程: 1.postgresql 5432端口已开放,执行任务的节点能telnet通,并且netcat测试通过 2.sqoop list-tables命令可正常执行,sq
-
hive从mysql导入数据量变多的解决方案
原始导数命令: bin/sqoop import -connect jdbc:mysql://192.168.169.128:3306/yubei -username root -password 123456 -table yl_city_mgr_evt_info --split-by rec_id -m 4 --fields-terminated-by "\t" --lines-terminated-by "\n" --hive-import --hive-ov
-
解决Mybatis-Plus操作分页后数据失效问题
业务场景 我们知道在使用PageHelper分页插件时,会对执行PageHelper.startPage(pageNum, pageSize);方法后的第一条查询语句进行分页操作.在开发中总会遇到这样的业务情景,在进行分页查询后,需要对获得的列表数据包装成另一种类型,此时需要对新类型的列表进行分页,然而由于PageInfo<T>因为泛型的原因,导致处理后的列表不能加入到该类中. 如,我在数据库分页后查询到的类为PageInfo<User>,此时改类中的list属性为User,在当前
-
Python中import导入上一级目录模块及循环import问题的解决
import上一级目录的模块 python中,import module会去sys.path搜索,sys.path是个列表,并且我们可以动态修改. 要import某个目录的module,我们sys.path.insert(0,somedir)来加入搜索路径,就可以import了. 既然这样,要import上一级目录的module,可以sys.path.insert(0,parentdir). 不过这种写绝对路径的方式,如果文件放到其它地方,就不行了. 所以用动态方法来获取上一级目录. impor
-
使用sessionStorage解决vuex在页面刷新后数据被清除的问题
1.原因 2.解决方法 localStorage没有时间期限,除非将它移除,sessionStorage即会话,当浏览器关闭时会话结束,有时间期限,具有自行百度 我这里使用sessionStorage,这里需要注意的是vuex中的变量是响应式的,而sessionStorage不是,当你改变vuex中的状态,组件会检测到改变,而sessionStorage就不会了,页面要重新刷新才可以看到改变,所以应让vuex中的状态从sessionStorage中得到,这样组件就可以响应式的变化 3.具体实现
-
快速解决mysql导数据时,格式不对、导入慢、丢数据的问题
如果希望一劳永逸的解决慢的问题,不妨把你的mysql升级到mysql8.0吧,mysql8.0默认的字符集已经从latin1改为utf8mb4,因此现在UTF8的速度要快得多,在特定查询时速度提高了1800%! 但是如果时间等不及,就先用下面的办法快速解决一下. 问题一:格式不对(常出现时间格式不对的情况): 方法1:将excel文件另存为csv,再导入数据库: 方法2:导入的第一步时,默认编码方式是65001(UTF-8),可以尝试选择[10008 (MAC - Simplified Chin
-
解决Echarts2竖直datazoom滑动后显示数据不全的问题
垂直datazoom拖动后第一个和最后一个往往显示不出来,这可能是echart2的bug. 解决方法: 把dataZoom中的handleSize设置小一些可以了.默认值8,可设为4 补充知识:echarts踩坑,dataZoom和X坐标系文字重叠解决方法 找到echarts中的 grid 配置 : 代码写入bottom属性: grid:{ bottom: "70px" } 完成效果: 以上这篇解决Echarts2竖直datazoom滑动后显示数据不全的问题就是小编分享给大家的全部内容
-
解决MySQL读写分离导致insert后select不到数据的问题
MySQL设置独写分离,在代码中按照如下写法,可能会出现问题 // 先录入 this.insert(obj); // 再查询 Object res = this.selectById(obj.getId()); res: null; 线上的一个坑,做了读写分离以后,有一个场景因为想方法复用,只传入一个ID就好,直接去库里查出一个对象再做后续处理,结果查不出来,事务隔离级别各种也都排查了,最后发现是读写分离的问题,所以换个思路去实现吧. 补充知识:MySQL INSERT插入条件判断:如果不存在则
-
解决python中导入win32com.client出错的问题
准备写一个操作Excel脚本却在导入包的时候出现了一个小问题 导入包 from Tkinter import Tk from time import sleep, ctime from tkMessageBox import showwarning from urllib import urlopen import win32com.client as win32 报错提示 Traceback (most recent call last): File "estock.pyw", li