Postgresql排序与limit组合场景性能极限优化详解
1 构造测试数据
create table tbl(id int, num int, arr int[]); create index idx_tbl_arr on tbl using gin (arr); create or replace function gen_rand_arr() returns int[] as $$ select array(select (1000*random())::int from generate_series(1,64)); $$ language sql strict; insert into tbl select generate_series(1,3000000),(10000*random())::int, gen_rand_arr(); insert into tbl select generate_series(1,500), (10000*random())::int, array[350,514,213,219,528,753,270,321,413,424,524,435,546,765,234,345,131,345,351];
2 查询走GIN索引
测试场景的限制GIN索引查询速度是很快的, 在实际生产中,可能出现使用gin索引后,查询速度依然很高的情况,特点就是执行计划中Bitmap Heap Scan占用了大量时间,Bitmap Index Scan大部分标记的块都被过滤掉了。
这种情况是很常见的,一般的btree索引可以cluster来重组数据,但是gin索引是不支持cluster的,一般的gin索引列都是数组类型。所以当出现数据非常分散的情况时,bitmap index scan会标记大量的块,后面recheck的成本非常高,导致gin索引查询慢。
我们接着来看这个例子
explain analyze select * from tbl where arr @> array[350,514,213,219,528,753,270] order by num desc limit 20;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=2152.02..2152.03 rows=1 width=40) (actual time=57.665..57.668 rows=20 loops=1)
-> Sort (cost=2152.02..2152.03 rows=1 width=40) (actual time=57.664..57.665 rows=20 loops=1)
Sort Key: num
Sort Method: top-N heapsort Memory: 27kB
-> Bitmap Heap Scan on tbl (cost=2148.00..2152.01 rows=1 width=40) (actual time=57.308..57.581 rows=505 loops=1)
Recheck Cond: (arr @> '{350,514,213,219,528,753,270}'::integer[])
Heap Blocks: exact=493
-> Bitmap Index Scan on idx_tbl_arr (cost=0.00..2148.00 rows=1 width=0) (actual time=57.248..57.248 rows=505 loops=1)
Index Cond: (arr @> '{350,514,213,219,528,753,270}'::integer[])
Planning time: 0.050 ms
Execution time: 57.710 ms
可以看到当前执行计划是依赖gin索引扫描的,但gin索引出现性能问题时我们如何来优化呢?
3 排序limit组合场景优化
SQL中的排序与limit组合是一个很典型的索引优化创景。我们知道btree索引在内存中是有序的,通过遍历btree索引可以直接拿到sort后的结果,这里组合使用limit后,只需要遍历btree的一部分节点然后按照其他条件recheck就ok了。
我们来看一下优化方法:
create index idx_tbl_num on tbl(num);
analyze tbl;
set enable_seqscan = off;
set enable_bitmapscan = off;
postgres=# explain analyze select * from tbl where arr @> array[350,514,213,219,528,753,270] order by num desc limit 10;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.43..571469.93 rows=1 width=287) (actual time=6.300..173.949 rows=10 loops=1)
-> Index Scan Backward using idx_tbl_num on tbl (cost=0.43..571469.93 rows=1 width=287) (actual time=6.299..173.943 rows=10 loops=1)
Filter: (arr @> '{350,514,213,219,528,753,270}'::integer[])
Rows Removed by Filter: 38399
Planning time: 0.125 ms
Execution time: 173.972 ms
(6 rows)
Time: 174.615 ms
postgres=# cluster tbl using idx_tbl_num;
CLUSTER
Time: 124340.276 ms
postgres=# explain analyze select * from tbl where arr @> array[350,514,213,219,528,753,270] order by num desc limit 10;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.43..563539.77 rows=1 width=287) (actual time=1.145..34.602 rows=10 loops=1)
-> Index Scan Backward using idx_tbl_num on tbl (cost=0.43..563539.77 rows=1 width=287) (actual time=1.144..34.601 rows=10 loops=1)
Filter: (arr @> '{350,514,213,219,528,753,270}'::integer[])
Rows Removed by Filter: 38399
Planning time: 0.206 ms
Execution time: 34.627 ms
(6 rows)
本例的测试场景构造可能没有最大程度的体现问题,不过可以看出cluster后走btree索引可以很稳定的达到34ms左右。
在gin性能存在问题的时候,这类limit + order by的SQL语句不妨常识强制(pg_hint_plan)走一下btree索引,可能有意想不到的效果。
4 高并发场景下的gin索引查询性能下降
GIN索引为PostgreSQL数据库多值类型的倒排索引,一条记录可能涉及到多个GIN索引中的KEY,所以如果写入时实时合并索引,会导致IO急剧增加,写入RT必然增加。为了提高写入吞吐,PG允许用户开启GIN索引的延迟合并技术,开启后,数据会先写入pending list,并不是直接写入索引页,当pending list达到一定大小,或者autovacuum 对应表时,会触发pending list合并到索引的动作。
查询时,如果有未合并到索引中的PENDING LIST,那么会查询pending list,同时查询索引也的信息。
如果写入量很多,pending list非常巨大,合并(autovacuum worker做的)速度跟不上时,会导致通过GIN索引查询时查询性能下降。
create extension pageinspect ;
SELECT * FROM gin_metapage_info(get_raw_page('idx_tbl_arr', 0));
-- 如果很多条记录在pending list中,查询性能会下降明显。
-- vacuum table,强制合并pending list
vacuum tbl;
第4部分引用https://github.com/digoal/blog/blob/master/201809/20180919_02.md
补充:PostgreSQL -- 性能优化的小方法
一、回收磁盘空间
在PostgreSQL中,使用delete和update语句删除或更新的数据行并没有被实际删除,而只是在旧版本数据行的物理地址上将该行的状态置为已删除或已过期。因此当数据表中的数据变化极为频繁时,那么在一段时间之后该表所占用的空间将会变得很大,然而数据量却可能变化不大。要解决该问题,需要定期对数据变化频繁的数据表执行VACUUM操作。现在新版PostgreSQL是自动执行VACUUM的
使用VACUUM和VACUUM FULL命令回收磁盘空间
postgres=# vacuum arr_test;
postgres=# vacuum full arr_test;
创建测试数据:
postgres=# create table arr (id serial, value int, age int) #创建测试表
postgres=# insert into arr (value, age) select generate_series(1, 1000000) as value, (random()*(10^2))::integer; #插入100W测试数据
postgres=# select pg_relation_size('arr'); #查看表大小
pg_relation_size
------------------
44285952
(1 row)
postgres=# delete from arr where id<300000; #删除299999条数据
DELETE 299999
postgres=# select pg_relation_size('arr'); #再次查看表大小,没有变化
pg_relation_size
------------------
44285952
(1 row)
postgres=# vacuum full arr; #vacuum表,再次查看表大小,明显变小了
VACUUM
postgres=# select pg_relation_size('arr');
pg_relation_size
------------------
30998528
(1 row)
postgres=# update arr set age=10000 where id>=300000 and id<600000; #更新30W条数据
UPDATE 300000
postgres=# select pg_relation_size('arr'); #查看表大小,明显再次增大
pg_relation_size
------------------
44285952
(1 row)
二、重建索引
在PostgreSQL中,为数据更新频繁的数据表定期重建索引(REINDEX INDEX)是非常有必要的。
对于B-Tree索引,只有那些已经完全清空的索引页才会得到重复使用,对于那些仅部分空间可用的索引页将不会得到重用,如果一个页面中大多数索引键值都被删除,只留下很少的一部分,那么该页将不会被释放并重用。
在这种极端的情况下,由于每个索引页面的利用率极低,一旦数据量显著增加,将会导致索引文件变得极为庞大,不仅降低了查询效率,而且还存在整个磁盘空间被完全填满的危险。
对于重建后的索引还存在另外一个性能上的优势,因为在新建立的索引上,逻辑上相互连接的页面在物理上往往也是连在一起的,这样可以提高磁盘页面被连续读取的几率,从而提高整个操作的IO效率
postgres=# REINDEX INDEX testtable_idx;
三、重新收集统计信息
PostgreSQL查询规划器在选择最优路径时,需要参照相关数据表的统计信息用以为查询生成最合理的规划。这些统计是通过ANALYZE命令获得的,你可以直接调用该命令,或者把它当做VACUUM命令里的一个可选步骤来调用,如VACUUM ANAYLYZE table_name,该命令将会先执行VACUUM再执行ANALYZE。与回收空间(VACUUM)一样,对数据更新频繁的表保持一定频度的ANALYZE,从而使该表的统计信息始终处于相对较新的状态,这样对于基于该表的查询优化将是极为有利的。然而对于更新并不频繁的数据表,则不需要执行该操作。
我们可以为特定的表,甚至是表中特定的字段运行ANALYZE命令,这样我们就可以根据实际情况,只对更新比较频繁的部分信息执行ANALYZE操作,这样不仅可以节省统计信息所占用的空间,也可以提高本次ANALYZE操作的执行效率。
这里需要额外说明的是,ANALYZE是一项相当快的操作,即使是在数据量较大的表上也是如此,因为它使用了统计学上的随机采样的方法进行行采样,而不是把每一行数据都读取进来并进行分析。因此,可以考虑定期对整个数据库执行该命令。
事实上,我们甚至可以通过下面的命令来调整指定字段的抽样率
如:
ALTER TABLE testtable ALTER COLUMN test_col SET STATISTICS 200
注意:该值的取值范围是0--1000,其中值越低采样比例就越低,分析结果的准确性也就越低,但是ANALYZE命令执行的速度却更快。如果将该值设置为-1,那么该字段的采样比率将恢复到系统当前默认的采样值,我们可以通过下面的命令获取当前系统的缺省采样值。
postgres=# show default_statistics_target; default_statistics_target --------------------------- 100 (1 row)
从上面的结果可以看出,该数据库的缺省采样值为100(10%)。
postgresql 性能优化
一、排序:
1. 尽量避免
2. 排序的数据量尽量少,并保证在内存里完成排序。
(至于具体什么数据量能在内存中完成排序,不同数据库有不同的配置:
oracle是sort_area_size;
postgresql是work_mem (integer),单位是KB,默认值是4MB。
mysql是sort_buffer_size 注意:该参数对应的分配内存是每连接独占!
)
二、索引:
1. 过滤的数据量比较少,一般来说<20%,应该走索引。20%-40% 可能走索引也可能不走索引。> 40% ,基本不走索引(会全表扫描)
2. 保证值的数据类型和字段数据类型要一致。
3. 对索引的字段进行计算时,必须在运算符右侧进行计算。也就是 to_char(oc.create_date, ‘yyyyMMdd')是没用的
4. 表字段之间关联,尽量给相关字段上添加索引。
5. 复合索引,遵从最左前缀的原则,即最左优先。(单独右侧字段查询没有索引的)
三、连接查询方式:
1、hash join
放内存里进行关联。
适用于结果集比较大的情况。
比如都是200000数据
2、nest loop
从结果1 逐行取出,然后与结果集2进行匹配。
适用于两个结果集,其中一个数据量远大于另外一个时。
结果集一:1000
结果集二:1000000
四、多表联查时:
在多表联查时,需要考虑连接顺序问题。
1、当postgresql中进行查询时,如果多表是通过逗号,而不是join连接,那么连接顺序是多表的笛卡尔积中取最优的。如果有太多输入的表, PostgreSQL规划器将从穷举搜索切换为基因概率搜索,以减少可能性数目(样本空间)。基因搜索花的时间少, 但是并不一定能找到最好的规划。
2、对于JOIN,LEFT JOIN / RIGHT JOIN 会一定程度上指定连接顺序,但是还是会在某种程度上重新排列:FULL JOIN 完全强制连接顺序。如果要强制规划器遵循准确的JOIN连接顺序,我们可以把运行时参数join_collapse_limit设置为 1
五、PostgreSQL提供了一些性能调优的功能:
优化思路:
0、为每个表执行 ANALYZE
。然后分析 EXPLAIN (ANALYZE,BUFFERS) sql。
1、对于多表查询,查看每张表数据,然后改进连接顺序。
2、先查找那部分是重点语句,比如上面SQL,外面的嵌套层对于优化来说没有意义,可以去掉。
3、查看语句中,where等条件子句,每个字段能过滤的效率。找出可优化处。
比如oc.order_id = oo.order_id是关联条件,需要加索引
oc.op_type = 3 能过滤出1/20的数据,
oo.event_type IN (…) 能过滤出1/10的数据,
这两个是优化的重点,也就是实现确保op_type与event_type已经加了索引,其次确保索引用到了。
优化方案:
a) 整体优化:
1、使用EXPLAIN
EXPLAIN命令可以查看执行计划,这个方法是我们最主要的调试工具。
2、及时更新执行计划中使用的统计信息
由于统计信息不是每次操作数据库都进行更新的,一般是在 VACUUM 、 ANALYZE 、 CREATE INDEX等DDL执行的时候会更新统计信息,
因此执行计划所用的统计信息很有可能比较旧。 这样执行计划的分析结果可能误差会变大。
以下是表tenk1的相关的一部分统计信息。
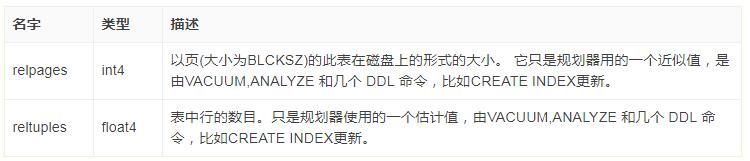
SELECT relname, relkind, reltuples, relpages FROM pg_class WHERE relname LIKE 'tenk1%'; relname | relkind | reltuples | relpages ----------------------+---------+-----------+---------- tenk1 | r | 10000 | 358 tenk1_hundred | i | 10000 | 30 tenk1_thous_tenthous | i | 10000 | 30 tenk1_unique1 | i | 10000 | 30 tenk1_unique2 | i | 10000 | 30 (5 rows)
其中 relkind是类型,r是自身表,i是索引index;reltuples是项目数;relpages是所占硬盘的块数。
估计成本通过 (磁盘页面读取【relpages】*seq_page_cost)+(行扫描【reltuples】*cpu_tuple_cost)计算。
默认情况下, seq_page_cost是1.0,cpu_tuple_cost是0.01。
3、使用临时表(with)
对于数据量大,且无法有效优化时,可以使用临时表来过滤数据,降低数据数量级。
4、对于会影响结果的分析,可以使用 begin;…rollback;来回滚。

b) 查询优化:
1、明确用join来关联表,确保连接顺序
一般写法:SELECT * FROM a, b, c WHERE a.id = b.id AND b.ref = c.id;
如果明确用join的话,执行时候执行计划相对容易控制一些。
例子:
SELECT * FROM a CROSS JOIN b CROSS JOIN c WHERE a.id = b.id AND b.ref = c.id;
SELECT * FROM a JOIN (b JOIN c ON (b.ref = c.id)) ON (a.id = b.id);
c) 插入更新优化
1、关闭自动提交(autocommit=false)
如果有多条数据库插入或更新等,最好关闭自动提交,这样能提高效率
2、多次插入数据用copy命令更高效
我们有的处理中要对同一张表执行很多次insert操作。这个时候我们用copy命令更有效率。因为insert一次,其相关的index都要做一次,比较花费时间。
3、临时删除index【具体可以查看Navicat表数据生成sql的语句,就是先删再建的】
有时候我们在备份和重新导入数据的时候,如果数据量很大的话,要好几个小时才能完成。这个时候可以先把index删除掉。导入后再建index。
4、外键关联的删除
如果表的有外键的话,每次操作都没去check外键整合性。因此比较慢。数据导入后再建立外键也是一种选择。
d) 修改参数:
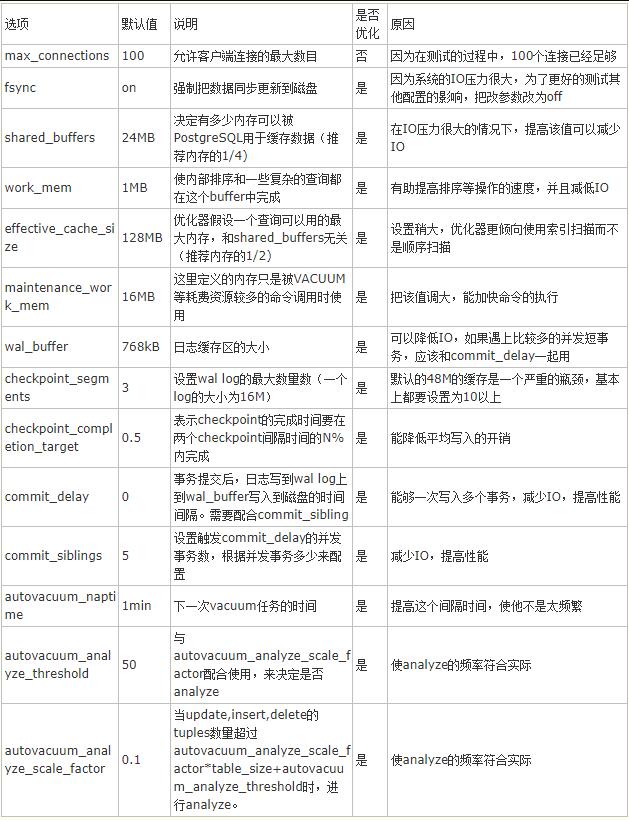
介绍几个重要的
1、增加maintenance_work_mem参数大小
增加这个参数可以提升CREATE INDEX和ALTER TABLE ADD FOREIGN KEY的执行效率。
2、增加checkpoint_segments参数的大小
增加这个参数可以提升大量数据导入时候的速度。
3、设置archive_mode无效
这个参数设置为无效的时候,能够提升以下的操作的速度
?CREATE TABLE AS SELECT
?CREATE INDEX
?ALTER TABLE SET TABLESPACE
?CLUSTER等。
4、autovacuum相关参数
autovacuum:默认为on,表示是否开起autovacuum。默认开起。特别的,当需要冻结xid时,尽管此值为off,PG也会进行vacuum。
autovacuum_naptime:下一次vacuum的时间,默认1min。 这个naptime会被vacuum launcher分配到每个DB上。autovacuum_naptime/num of db。
log_autovacuum_min_duration:记录autovacuum动作到日志文件,当vacuum动作超过此值时。 “-1”表示不记录。“0”表示每次都记录。
autovacuum_max_workers:最大同时运行的worker数量,不包含launcher本身。
autovacuum_work_mem :每个worker可使用的最大内存数。
autovacuum_vacuum_threshold :默认50。与autovacuum_vacuum_scale_factor配合使用, autovacuum_vacuum_scale_factor默认值为20%。当update,delete的tuples数量超过autovacuum_vacuum_scale_factor *table_size+autovacuum_vacuum_threshold时,进行vacuum。如果要使vacuum工作勤奋点,则将此值改小。
autovacuum_analyze_threshold :默认50。与autovacuum_analyze_scale_factor配合使用。
autovacuum_analyze_scale_factor :默认10%。当update,insert,delete的tuples数量超过autovacuum_analyze_scale_factor *table_size+autovacuum_analyze_threshold时,进行analyze。
autovacuum_freeze_max_age:200 million。离下一次进行xid冻结的最大事务数。
autovacuum_multixact_freeze_max_age:400 million。离下一次进行xid冻结的最大事务数。
autovacuum_vacuum_cost_delay :如果为-1,取vacuum_cost_delay值。
autovacuum_vacuum_cost_limit :如果为-1,到vacuum_cost_limit的值,这个值是所有worker的累加值。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
postgresql 获取两个时间类型小时差值案例
我就废话不多说了,看代码吧~ select extract(day from t) * 24 + extract(hour from t) from (select (timestamp '2013-12-14 12:00:00' - timestamp '2013-12-11 4:00:00') as t) as a; 例如a表中有start,end俩字段 select extract(day from (end-start)) * 24 + extract(hour from (end-st
-
详解PostgreSql数据库对象信息及应用
PostgreSql数据库对象主要有数据库.表.视图.索引.schema.函数.触发器等.PostgreSql提供了information_schema schema,其中包括返回数据库对象的视图.如用户有访问权限,可以也在pg_catalog schema中查询表.视图等对象. 1. 查询数据库对象 下面通过示例分别展示如何查询各种数据库对象. 1.1 表查询 PostgreSql 表信息可以从information_schema.tables 或 pg_catalog.pg_tables 视
-
postgreSQL 非count方法算记录数操作
一般方法 select count(1) from table_name; 全量扫描一遍表,记录越多,查询速度越慢 新法 PostgreSQL 还真提供了一个这样的途径,那就是系统表 pg_class,这个系统表里头,存储着每个表的统计信息,其中 reltuples 就是对应的表的统计行,统计行的数据是pg有个独立进程,定期扫描不同的表,收集这些表的统计信息,保存在系统表里头. 方法如下: select reltuples::int as total from pg_class where re
-
postgresql的now()与Oracle的sysdate区别说明
postgresql的now()为当前事务开始时间, 而Oracle的sysdate是当前时间. 区别在于事务. postgresql中的now(): postgres=# begin ; BEGIN postgres=# select now(); now ------------------------------- 2017-03-31 14:28:32.403869+08 (1 row) postgres=# select now(); now ---------------------
-

postgresql通过索引优化查询速度操作
当数据量比较大的时候,提升查询效率就是需要去考虑的事情了.一个百万级别的表格,如果不做任何优化的话,即使是最简单的查询语句执行起来也是慢的让人难以接受:当然"优化"本身是一个比较复杂的工程,从设计表.字段到查询语句的写法都有很多讲究,这里只考虑索引的方式,且是最普通的索引: 下面的操作中对应数据库表w008_execrise_info(8000数据量), w008_wf02_info(4000数据量) 1 任务表数据 SELECT w.* FROM w008_wf02_info w W
-
Postgresql 通过出生日期获取年龄的操作
三个基础的时间表示函数 CURRENT_DATE/CURRENT_TIME/NOW() SELECT CURRENT_DATE ; 返回当前日期以 年-月-日(yyyy-MM-dd)的形式: 2019-01-10 SELECT CURRENT_TIME; 返回当日时间以 时:分:秒+时区(HH:mm:ss )的形式: 17:49:11.585308+08 SELECT NOW(); 返回当前时间 以 年-月-日 时:分:秒(yyyy-MM-dd HH:mm:ss)的形式: 2019-01-10
-
Postgresql排序与limit组合场景性能极限优化详解
1 构造测试数据 create table tbl(id int, num int, arr int[]); create index idx_tbl_arr on tbl using gin (arr); create or replace function gen_rand_arr() returns int[] as $$ select array(select (1000*random())::int from generate_series(1,64)); $$ language sq
-
iOS 下的图片处理与性能优化详解
图片在计算机世界中怎样被存储和表示? 图片和其他所有资源一样,在内存中本质上都是0和1的二进制数据,计算机需要将这些原始内容渲染成人眼能观察的图片,反过来,也需要将图片以合适的形式保存在存储器或者在网络上传送. 这种将图片以某种规则进行二进制编码的方式,就是图片的格式. 常见的图片格式 图片的格式有很多种,除了我们熟知的 JPG.PNG.GIF,还有Webp,BMP,TIFF,CDR 等等几十种,用于不同的场景或平台. 这些格式可以分为两大类:有损压缩和无损压缩. 有损压缩:相较于颜色,人眼对光
-
Android性能优化之弱网优化详解
目录 弱网优化 1.Serializable原理 1.1 分析过程 1.2 Serializable接口 1.3 ObjectOutputStream 1.4 序列化后二进制文件的一点解读 1.5 常见的集合类的序列化问题 1.5.1 HashMap 1.5.2 ArrayList 2.Parcelable 2.1 Parcel的简介 2.2 Parcelable的三大过程介绍(序列化.反序列化.描述) 2.2.1 描述 2.2.2 序列化 2.2.3 反序列化 2.3 Parcelable的实
-
基于Tomcat安全配置与性能优化详解
Tomcat 是 Apache软件基金会下的一个免费.开源的WEB应用服务器,它可以运行在 Linux 和 Windows 等多个平台上,由于其性能稳定.扩展性好.免费等特点深受广大用户喜爱.目前,很多互联网应用和企业应用都部署在 Tomcat 服务器上,比如我们公司,哈. 之前我们 tomcat 都采用的是默认的配置,因此在安全方面还是有所隐患的.上周对测试环境的所有服务器的tomcat都做了安全优化,其间也粗略做了一些性能优化,这里就简单记录分享下! 一.版本安全 升级当前的tomcat版本
-
postgresql高级应用之合并单元格的思路详解
1.写在前面✍ 继上一篇postgresql高级应用之行转列&汇总求和之后想更进一步做点儿复杂的(圖表暫且不論哈
-
MongoDB 中Limit与Skip的使用方法详解
MongoDB 中Limit与Skip的使用方法详解 一 MongoDB Limit() 方法 如果你需要在MongoDB中读取指定数量的数据记录,可以使用MongoDB的Limit方法,limit()方法接受一个数字参数,该参数指定从MongoDB中读取的记录条数. 语法 limit()方法基本语法如下所示: >db.COLLECTION_NAME.find().limit(NUMBER) 实例 > db.col.find({},{"title":1,_id:0}).li
-
Keras官方中文文档:性能评估Metrices详解
能评估 使用方法 性能评估模块提供了一系列用于模型性能评估的函数,这些函数在模型编译时由metrics关键字设置 性能评估函数类似与目标函数, 只不过该性能的评估结果讲不会用于训练. 可以通过字符串来使用域定义的性能评估函数 model.compile(loss='mean_squared_error', optimizer='sgd', metrics=['mae', 'acc']) 也可以自定义一个Theano/TensorFlow函数并使用之 from keras import metri
-
java 较大数据量取差集,list.removeAll性能优化详解
今天在优化项目中的考勤同步功能时遇到将考勤机中的数据同步到数据库, 两边都是几万条数据的样子,老代码的做法差不多半个小时,优化后我本机差不多40秒,服务器速度会更加理想. 两个数据集取差集首先想到的方法便是List.removeAll方法,但是实验发现jdk自带的List.removeAll效率很低 List.removeAll效率低原因: List.removeAll效率低和list集合本身的特点有关 : List底层数据结构是数组,查询快,增删慢 1.List.contains()效率没有h
-
Python实现特定场景去除高光算法详解
目录 算法思路 应用场景 代码实现 实验效果 补充 算法思路 1.求取源图I的平均灰度,并记录rows和cols: 2.按照一定大小,分为N*M个方块,求出每块的平均值,得到子块的亮度矩阵D: 3.用矩阵D的每个元素减去源图的平均灰度,得到子块的亮度差值矩阵E: 4.通过插值算法,将矩阵E差值成与源图一样大小的亮度分布矩阵R: 5.得到矫正后的图像result=I-R: 应用场景 光照不均匀的整体色泽一样的物体,比如工业零件,ocr场景. 代码实现 import cv2 import numpy
-
java性能分析jconsole详解
目录 jconsole简介 jconsole远程 前言: 本章节继续学习java性能优化的相关知识.重点学习什么是jconsole,以及如何使用?它能帮助我们做什么? jconsole简介 提供JVM图形化视图,包括内存.线程.类.cpu等信息.用户可以通过jconsole工具去连接指定的jvm,监控jvm的变化. 我们可以在jdk的安装文件bin当中找到它: 双击运行会打开如下界面,上面是本地的java进程,下面是通过远程的方式连接服务器上面的java进程. 我们随便点击一个本地进程得到如下的