详解Python爬虫爬取博客园问题列表所有的问题
一.准备工作
- 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下。
- 我们的需求是将博客园问题列表中的所有问题的题目爬取下来。
二.分析:
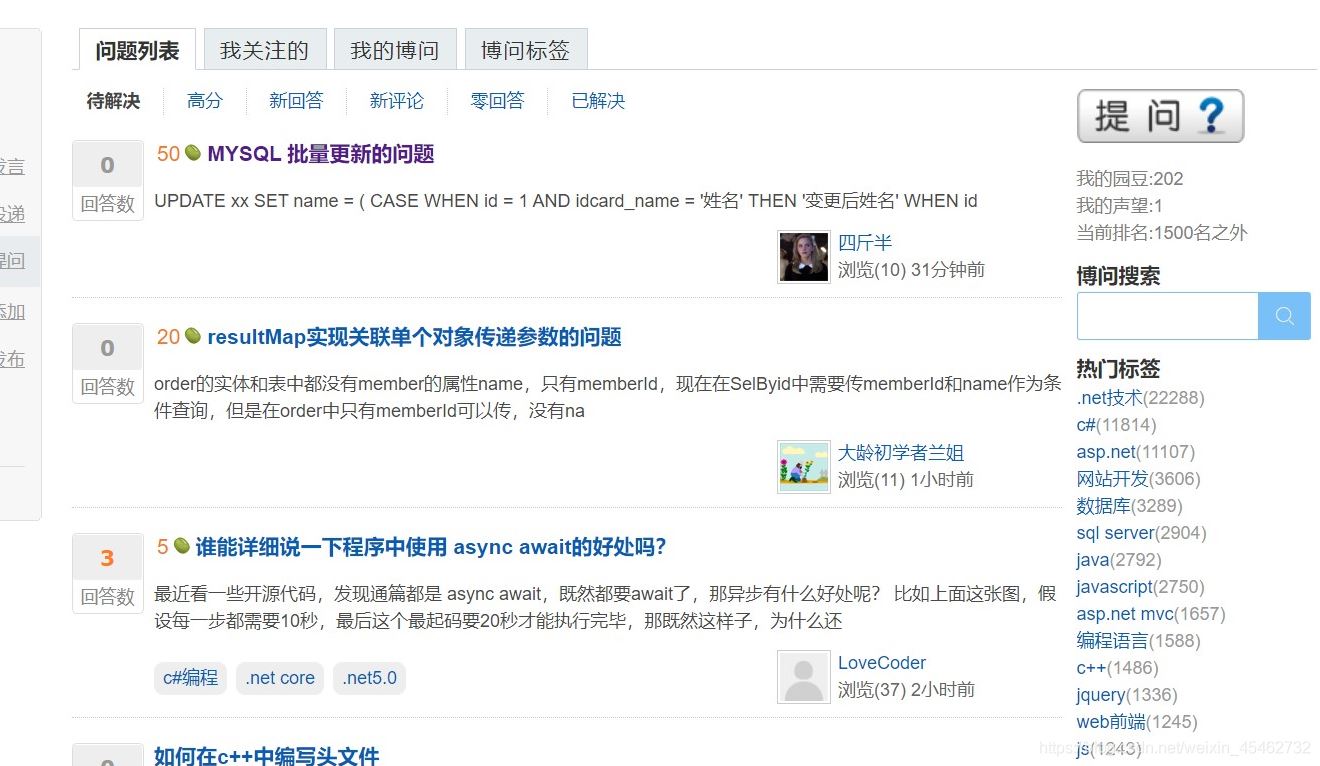
- 首先博客园问题列表页面右键点击检查
- 通过Element查找问题所对应的属性或标签
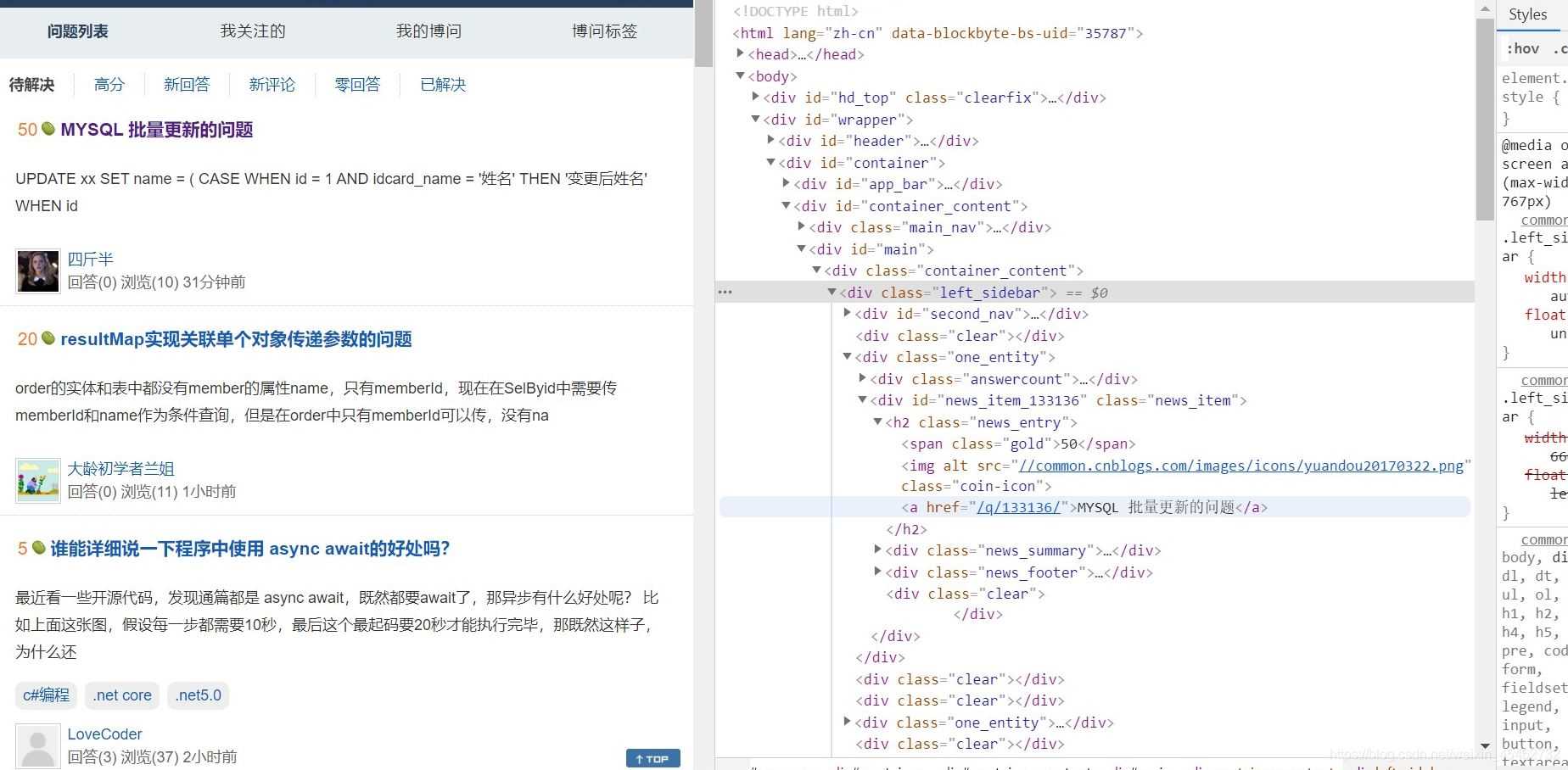
可以发现在div class ="one_entity"中存在页面中分别对应每一个问题
接着div class ="news_item"中h2标签下是我们想要拿到的数据
三.代码实现
首先导入requests和BeautifulSoup
import requests from bs4 import BeautifulSoup
由于很多网站定义了反爬策略,所以进行伪装一下
headers = {
'User-Agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 87.0.4280.141Safari / 537.36'
}
在这里User-Agent只是其中的一种方式,而且大家的User-Agent可能不同。
爬取数据main代码
url = 'https://q.cnblogs.com/list/unsolved?'
fp = open('blog', 'w', encoding='utf-8')
for page in range(1,26):
page = str(page)
param = {
'page':page
}
page_text = requests.get(url=url,params=param,headers=headers).text
page_soup = BeautifulSoup(page_text,'lxml')
text_list = page_soup.select('.one_entity > .news_item > h2')
for h2 in text_list:
text = h2.a.string
fp.write(text+'\n')
print('第'+page+'页爬取成功!')
注意一下这里,由于我们需要的是多张页面的数据,所以在发送请求的url中我们就要针对不同的页面发送请求,https://q.cnblogs.com/list/unsolved?page=我们要做的是在发送请求的url时候,根据参数来填充页数page,
代码实现:
url = 'https://q.cnblogs.com/list/unsolved?'
for page in range(1,26):
page = str(page)
param = {
'page':page
}
page_text = requests.get(url=url,params=param,headers=headers).text
将所有的h2数组拿到,进行遍历,通过取出h2中a标签中的文本,并将每取出来的文本写入到文件中,由于要遍历多次,所以保存文件在上面的代码中。
text_list = page_soup.select('.one_entity > .news_item > h2')
for h2 in text_list:
text = h2.a.string
fp.write(text+'\n')
完整代码如下:
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla / 5.0(WindowsNT10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 87.0.4280.141Safari / 537.36'
}
url = 'https://q.cnblogs.com/list/unsolved?'
fp = open('blog', 'w', encoding='utf-8')
for page in range(1,26):
page = str(page)
param = {
'page':page
}
page_text = requests.get(url=url,params=param,headers=headers).text
page_soup = BeautifulSoup(page_text,'lxml')
text_list = page_soup.select('.one_entity > .news_item > h2')
for h2 in text_list:
text = h2.a.string
fp.write(text+'\n')
print('第'+page+'页爬取成功!')
四.运行结果
运行代码:

到此这篇关于详解Python爬虫爬取博客园问题列表所有的问题的文章就介绍到这了,更多相关Python爬虫爬取列表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python3爬虫爬取百姓网列表并保存为json功能示例【基于request、lxml和json模块】
本文实例讲述了Python3爬虫爬取百姓网列表并保存为json功能.分享给大家供大家参考,具体如下: python3爬虫之爬取百姓网列表并保存为json文件.这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手. 首先需要安装python3.如果还没有安装,可参考本站python3安装与配置相关文章. 首先需要安装requests和lxml和json三个模块 需要手动创建d.json文件 代码 import requests from lxml import etree
-
Python3实现爬虫爬取赶集网列表功能【基于request和BeautifulSoup模块】
本文实例讲述了Python3实现爬虫爬取赶集网列表功能.分享给大家供大家参考,具体如下: python3爬虫之爬取赶集网列表.这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手. 首先需要安装python3.如果还没有安装,可参考本站前面关于python3安装与配置相关文章. 首先需要安装request和BeautifulSoup两个模块 request是Python的HTTP网络请求模块,使用Requests可以轻而易举的完成浏览器可有的任何操作 pip insta
-
详解Python爬虫爬取博客园问题列表所有的问题
一.准备工作 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下. 我们的需求是将博客园问题列表中的所有问题的题目爬取下来. 二.分析: 首先博客园问题列表页面右键点击检查 通过Element查找问题所对应的属性或标签 可以发现在div class ="one_entity"中存在页面中分别对应每一个问题 接着div class ="news_item"中h2标签下是我们想要拿到的数据 三.代码实现 首先导入requests和
-
Python爬虫爬取博客实现可视化过程解析
源码: from pyecharts import Bar import re import requests num=0 b=[] for i in range(1,11): link='https://www.cnblogs.com/echoDetected/default.html?page='+str(i) headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
-
详解python selenium 爬取网易云音乐歌单名
目标网站: 首先获取第一页的数据,这里关键要切换到iframe里 打印一下 获取剩下的页数,这里在点击下一页之前需要设置一个延迟,不然会报错. 结果: 一共37页,爬取完毕后关闭浏览器 完整代码: url = 'https://music.163.com/#/discover/playlist/' from selenium import webdriver import time # 创建浏览器对象 window = webdriver.Chrome('./chromedriver') win
-
python爬虫爬取监控教务系统的思路详解
这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本. 设计思路: 设计思路很简单,首先对已有的成绩进行处理,变为list集合,然后定时爬取教务系统查成绩的页面,对爬取的成绩也处理成list集合,如果newList的长度增加了,就找出增加的部分,并通过邮件通知我. 脚本运行效果: 服务器: 发送邮件通知: 代码如下: import datetime import time from email.header import Header impor
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
python实战scrapy操作cookie爬取博客涉及browsercookie
browsercookie 知识铺垫 第一个要了解的知识点是使用 browsercookie 获取浏览器 cookie ,该库使用命令 pip install browsercookie 安装即可. 接下来获取 firefox 浏览器的 cookie,不使用 chrome 谷歌浏览器的原因是在 80 版本之后,其 cookie 的加密方式进行了修改,所以使用 browsercookie 模块会出现如下错误 win32crypt must be available to decrypt Chrom
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()