详解用selenium来下载小姐姐图片并保存
下载小姐姐图片并保存
- 请求的地址
- 伪装
- 定位元素
- 下载图片
- 保存好了
下面开始我们的实战,这个是我们今天访问的url:
url = 'http://pic.netbian.com/4kmeinv/'
1,先把包给导进来:
import requests from selenium.webdriver import Chrome,ChromeOptions import os
不知道怎么导包的看我的第一篇,附上链接:
https://www.jb51.net/article/204774.htm
2, 接下来就开始发送请求
#请求的url
url = 'http://pic.netbian.com/4kmeinv/'
#进行伪装
headers = {
"User_Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
#发起请求
response = requests.get(url=url,headers=headers)
#手动设定响应数据的编码格式
response.encoding = 'utf-8'
page_text = response.text
#这个就是再后台上面运行那个浏览器,不在表面上占用你的
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
option.add_experimental_option('excludeSwitches',['enable-automation'])
#这里也要输入
browser = Chrome(options=option)
browser.get(url)
相信看过我上篇的都知道这些,那就废话不多说,定位元素:
3,定位:
先看下代码再说:
li = browser.find_elements_by_xpath('//*[@id="main"]/div[3]/ul/li')
老样子,分为三步,第一步选中所选的图片–>copy xpath–>ctrl+f -->粘贴进去可以看到是1of1,但明显我们要的是这个页面上所有的图片,所以呀,只需要改一下就可以啦,将tr[1],里面的包括括号删掉就可以。
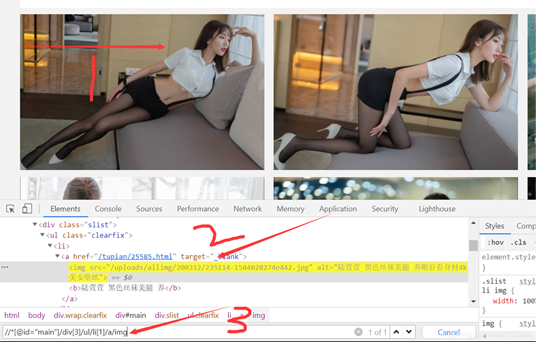
这样的话就是整个页面内所有的图片啦,

4,创建文件以保存我们所要的图片:
#创建一个文件夹
if not os.path.exists('./小美女图'):
os.mkdir('./小美女图')
然后再循环一下就好啦:
for i in li:
img_src = i.find_element_by_xpath('./a/img').get_attribute('src')
img_name = i.find_element_by_xpath('./a/img').get_attribute('alt')+'.jpg'
至于为什么要这么写,可以看一下我的上一篇博客:
https://www.jb51.net/article/204771.htm
5,保存
img_data = requests.get(url=img_src,headers=headers).content img_path = '小美女图/'+img_name with open(img_path,'wb') as fp: fp.write(img_data) print(img_name,'下载成功!!!')
最后的结果哈哈哈哈:这个也不存在什么图片尺寸过大啥的,如果错了,多半是你元素没有定位好。

到此这篇关于详解用selenium来下载小姐姐图片并保存的文章就介绍到这了,更多相关selenium 下载图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python使用selenium实现批量文件下载
背景 实现需求:批量下载联想某型号的全部驱动程序. 一般在做网络爬虫的时候,都是保存网页信息为主,或者下载单个文件.当涉及到多文件批量下载的时候,由于下载所需时间不定,下载的文件名不定,所以有一定的困难. 思路 参数配置 在涉及下载的时候,需要先对chromedriver进行参数配置,设定默认下载目录: global base_path profile = { 'download.default_directory': base_path } chrome_options = webdriver
-

Python selenium如何打包静态网页并下载
需求:单纯的将page.source写入文件的方式,会导致一些图片无法显示,对于google浏览器,直接将页面打包下载成一个mhtml格式的文件,则可以进行离线下载.对应python selenium 微信公众号历史文章随手一点就返回首页?郁闷之下只好将他们都下载下来.:https://www.jb51.net/article/193111.htm 遇到的问题: 1.单纯使用webdriver.ActionChains无法完成下载动作,未能操作windows窗口. 2.没有找到相关能直接下载.m
-
Python selenium文件上传下载功能代码实例
上传 html文件内容如下:操作步骤 <html> <head> <meta http-equiv="content-type" content="text/html;charset=utf-8" /> <title>upload_file</title> <script type="text/javascript" async="" src="htt
-
详解python环境安装selenium和手动下载安装selenium的方法
方法1:cmd环境下,用pip install selenium 可能会很慢 方法2:下载selenium安装包手动安装 下载地址:https://pypi.org/project/selenium/ 选择扩展名为gz的源码包进行下载 下载后解压,cmd环境进入到setup.py文件所在目录 运行 python setup.py install命令进行安装 安装完后用pip list可看到selenium的信息 此时就可以用import selenium引入selenium包了 到此这篇关于详解
-
python Selenium实现付费音乐批量下载的实现方法
必备环境 废话 每年回家都要帮我爸下些音乐,这对我来说都是轻车熟路!可当我打开网易云点击下载按钮的时候,可惜已物是人非啦! 开个 VIP 其实也不贵,临时用用也就¥15!但 IT 男的尊严必须要有,于是开始徜徉于搜索引擎中 最后在知乎中,搜索到一个网址VIP付费音乐解析 P.S.再次感谢提供该服务的作者!如果你下载的音乐数量不多,直接这里搜索下载,下载后修改文件名即可!并且在这个网址中点击播放列表-点击同步,可以同步网易云的歌单!之后批量下载即是下载这些网易云的歌单!但是下载某个歌单中的几百首歌
-
详解用selenium来下载小姐姐图片并保存
下载小姐姐图片并保存 请求的地址 伪装 定位元素 下载图片 保存好了 下面开始我们的实战,这个是我们今天访问的url: url = 'http://pic.netbian.com/4kmeinv/' 1,先把包给导进来: import requests from selenium.webdriver import Chrome,ChromeOptions import os 不知道怎么导包的看我的第一篇,附上链接: https://www.jb51.net/article/204774.htm
-
详解性能更优越的小程序图片懒加载方式
意义 懒加载或者可以说是延迟加载,针对非首屏或者用户"看不到"的地方延迟加载,有利于页面首屏加载速度快.节约了流量,用户体验好 实现方式 传统H5的懒加载方式都是通过监听页面的scroll事件来实现的,结合viewport的高度来判断. 小程序也类似,通过监听页面onPageScroll事件获取当前滚动的数据,结合getSystemInfo获取设备信息来判断.由于scroll事件密集发生,计算量很大,经常会造成FPS降低.页面卡顿等问题. 这里说的是通过另外一种方式来实现 create
-
Android中图片压缩方案详解及源码下载
Android中图片压缩方案详解及源码下载 图片的展示可以说在我们任何一个应用中都避免不了,可是大量的图片就会出现很多的问题,比如加载大图片或者多图时的OOM问题,可以移步到Android高效加载大图及多图避免程序OOM.还有一个问题就是图片的上传下载问题,往往我们都喜欢图片既清楚又占的内存小,也就是尽可能少的耗费我们的流量,这就是我今天所要讲述的问题:图片的压缩方案的详解. 1.质量压缩法 设置bitmap options属性,降低图片的质量,像素不会减少 第一个参数为需要压缩的bitmap图
-
详解使用Selenium爬取豆瓣电影前100的爱情片相关信息
什么是Selenium Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome.Firefox.Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器. 1.准备工作 由于Selenium的环境配置过程比较繁琐,我会尽可能详细的对其进行讲解. 1.1 安装Selenium 由于Selenium的环境配置过程比较繁琐,我会多花一些篇幅对其进行讲解.可以在cmd命令框输入以下内容安装Selenium库. pip install Selenium 1.2 浏
-
详解Python Selenium如何获取鼠标指向的元素
有一个同学在Gne的群里面咨询如何通过Selenium获取当前鼠标指向的元素,在我讲了方法以后,他过了两天又来问: 那么,我今天就来写一篇文章,具体说说应该怎么操作. 这个方法的核心,是借助JavaScript的事件(event)来获取鼠标所在的元素.然后再把这个元素传递给Selenium.我们先来第一步,不考虑Selenium,只使用JavaScript,如何获取当前鼠标指向的元素呢? 我们首先需要知道在JavaScript中的一个事件句柄,叫做window.onmousemove.默认情况下
-
详解Linux 下开发微信小程序安装开发工具
详解Linux 下开发微信小程序安装开发工具 1. git clone https://github.com/yuan1994/wechat_web_devtools 然后创建一个文件夹 mkdir /opt/tencent/ 移动文件 mv ./wechat_web_devtools /opt/tencent 修改用户组 chown -R root:root /opt/tencent/wechat_web_devtools 启动测试工具 /opt/tencent/wechat_web_devt
-
详解ES6 CLASS在微信小程序中的应用实例
ES6 CLASS基本用法 class Point { constructor(x, y) { this.x = x; this.y = y; } toString() { return '(' + this.x + ', ' + this.y + ')'; } } 1.1 constructor方法 constructor方法是类的默认方法,通过new命令生成对象实例时,自动调用该方法.一个类必须有constructor方法,如果没有显式定义,一个空的constructor方法会被默认添加.
-
详解如何在Flutter中用小部件创建响应式布局
目录 前提条件 使用容器的问题 展开式小组件的介绍 灵活小组件的介绍 设置一个示例应用程序 代码执行 扩展的小部件例子 灵活部件的例子 扩大的和灵活的部件之间的区别 总结 构建响应式屏幕布局意味着编写一段代码,以响应设备布局的各种变化,因此应用程序会根据设备的屏幕尺寸和形状显示其UI. 在这篇文章中,我们将探讨Flutter中用于屏幕响应的扩展和灵活部件. 由于Flutter的跨平台.单一代码库的能力,了解屏幕管理以防止像柔性溢出错误或糟糕的用户界面设计这样的问题是至关重要的. 我们还将设计一个
-
详解Java Selenium中的键盘控制操作
目录 简介 键盘控制 补充知识 简介 本文主要简介如何使用java代码利用Selenium 控制浏览器中需要用到的键盘操作. 键盘控制 webdriver 中 Keys 类几乎提供了键盘上的所有按键方法,我们可以使用 send_keys + Keys 实现输出键盘上的组合按键如 “Ctrl + C”.“Ctrl + V” 等. import org.openqa.selenium.By; import org.openqa.selenium.Keys; import org.openqa.sel
-
详解Java Selenium中的鼠标控制操作
目录 简介 鼠标控制 单击左键 单击右键 双击左键 按压左键 鼠标箭头移动 鼠标释放 鼠标拖拽 鼠标等待 简介 本文主要讲解如何用java Selenium 控制鼠标在浏览器上的操作方法.主要列举的代码示例,无图显示.可以自己上代码执行操作看效果. 鼠标控制 单击左键 模拟完成单击鼠标左键的操作,一般点击进入子页面等会用到. 第一种通过WebElement对象的click()方法实现单击左键 import org.openqa.selenium.By; import org.openqa.sel