Python网络爬虫四大选择器用法原理总结
前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式、BeautifulSoup、Xpath、CSS选择器分别抓取京东网的商品信息。今天小编来给大家总结一下这四个选择器,让大家更加深刻的理解和熟悉Python选择器。
一、正则表达式
正则表达式为我们提供了抓取数据的快捷方式。虽然该正则表达式更容易适应未来变化,但又存在难以构造、可读性差的问题。当在爬京东网的时候,正则表达式如下图所示:

利用正则表达式实现对目标信息的精准采集
此外 ,我们都知道,网页时常会产生变更,导致网页中会发生一些微小的布局变化时,此时也会使得之前写好的正则表达式无法满足需求,而且还不太好调试。当需要匹配的内容有很多的时候,使用正则表达式提取目标信息会导致程序运行的速度减慢,需要消耗更多内存。
二、BeautifulSoup
BeautifulSoup是一个非常流行的 Pyhon 模块。该模块可以解析网页,并提供定位内容的便捷接口。通过'pip install beautifulsoup4'就可以实现该模块的安装了。
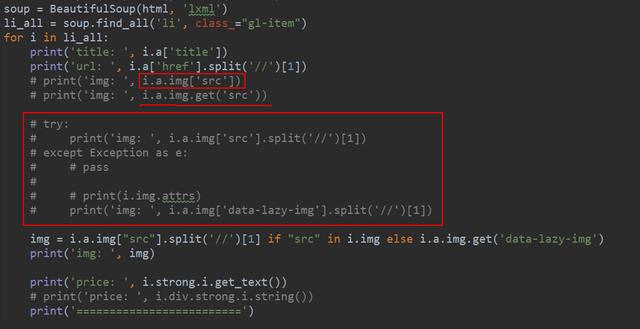
利用美丽的汤去提取目标信息
使用 BeautifulSoup的第一步是将己下载的 HTML 内容解析为 soup文档。由 于大多 数网 页都不具备良好的HTML 格式,因此BeautifulSoup需要对实际格式进行确定。BeautifulSoup能够正确解析缺失的引号并闭合标签,此外还会添加<html >和<body>标签使其成为完整的HTML文档。通常使用find() 和find_all()方法来定位我们需要的元素。如果你想了解BeautifulSoup全部方法和参数,可以查阅BeautifulSoup的官方文档。虽然BeautifulSoup在代码的理解上比正则表达式要复杂一些,但是其更加容易构造和理解。
三、Lxml
Lxml模块使用 C语言编写,其解析速度比 BeautiflSoup更快,而且其安装过程也更为复杂,在此小编就不赘述啦。XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。

Xpath
使用 lxml 模块的第一步和BeautifulSoup一样,也是将有可能不合法的HTML 解析为 统一格式。 虽然Lxml可以正确解析属性两侧缺失的引号,并闭合标签,不过该模块没有额外添加<html >和<body>标签 。
在线复制Xpath表达式可以很方便的复制Xpath表达式。但是通过该方法得到的Xpath表达式放在程序中一般不能用,而且长的没法看。所以Xpath表达式一般还是要自己亲自上手。
四、CSS
CSS选择器表示选择元素所使用 的模式。BeautifulSoup整合了CSS选择器的语法和自身方便使用API。在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人,使用CSS选择器是个非常方便的方法。

CSS选择器
下面是一些常用的选择器示例。
- 选择所有标签: *
- 选择<a>标 签: a
- 选择所有class=”link” 的元素: .l in k
- 选择 class=”link” 的<a>标签: a.link
- 选择 id= " home ” 的<a>标签: a Jhome
- 选择父元素为<a>标签的所有< span>子标签: a > span
- 选择<a>标签内部的所有<span>标签: a span
- 选择title属性为” Home ” 的所有<a>标签: a [title=Home]
五、性能对比
lxml 和正则表达式模块都是C语言编写的,而BeautifulSoup则是纯Python 编写的。下表总结了每种抓取方法的优缺点。
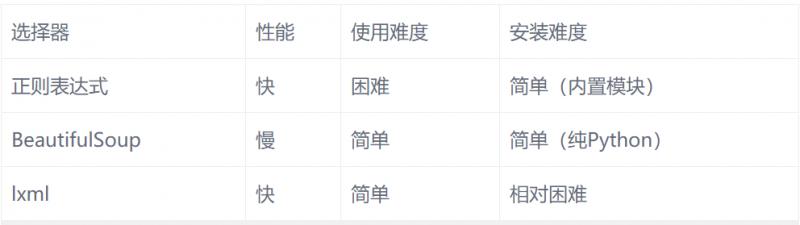
相对困难需要注意的是。lxml在内部实现中,实际上是将CSS选择器转换为等价的Xpath选择器。
六、总结
如果你的爬虫瓶颈是下载网页,而不是抽取数据的话,那么使用较慢的方法(如BeautifulSoup) 也不成问题。如果只需抓取少量数据,并且想要避免额外依赖的话,那么正则表达式可能更加适合。不过,通常情况下,l xml是抓取数据的最好选择,这是因为该方法既快速又健壮,而正则表达式和BeautifulSoup只在某些特定场景下有用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python大数据之网络爬虫的post请求、get请求区别实例分析
本文实例讲述了Python大数据之网络爬虫的post请求.get请求区别.分享给大家供大家参考,具体如下: 在JetBrains PyCharm 2016.3软件中编写代码前,需要指定python和编码方式: #!user/bin/python 编码方式 :#coding=utf-8 或者 #-*-coding:utf-8-*- post请求: #导入工具,内置的库 import urllib import urllib2 #加一个\可以换行 #response = \ #urllib2.url
-
Python网络爬虫之爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url= https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6 1.分析网页的源代码:右键--查看网页源代码. 从网页代码中可以获取到信息 (1)热搜的名字都在<td class="td-02">的子节点<a>里 (2)热搜的排名都在<td class=td-01 ranktop>的里(注意置顶微博是
-
Python3网络爬虫中的requests高级用法详解
本节我们再来了解下 Requests 的一些高级用法,如文件上传,代理设置,Cookies 设置等等. 1. 文件上传 我们知道 Reqeuests 可以模拟提交一些数据,假如有的网站需要我们上传文件,我们同样可以利用它来上传,实现非常简单,实例如下: import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post('http://httpbin.org/post', files=files) print
-
Python实现爬虫从网络上下载文档的实例代码
最近在学习Python,自然接触到了爬虫,写了一个小型爬虫软件,从初始Url解析网页,使用正则获取待爬取链接,使用beautifulsoup解析获取文本,使用自己写的输出器可以将文本输出保存,具体代码如下: Spider_main.py # coding:utf8 from baike_spider import url_manager, html_downloader, html_parser, html_outputer class SpiderMain(object): def __ini
-

Python网络爬虫中的同步与异步示例详解
一.同步与异步 #同步编程(同一时间只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后) <-a_url-> <-b_url-> <-c_url-> <-d_url-> <-e_url-> <-f_url-> <-g_url-> <-h_url-> <--i_ur
-
Python网络爬虫神器PyQuery的基本使用教程
前言 pyquery库是jQuery的Python实现,能够以jQuery的语法来操作解析 HTML 文档,易用性和解析速度都很好,和它差不多的还有BeautifulSoup,都是用来解析的.相比BeautifulSoup完美翔实的文档,虽然PyQuery库的文档弱爆了, 但是使用起来还是可以的,有些地方用起来很方便简洁. 安装 关于PyQuery的安装可以参考这篇文章:http://www.jb51.net/article/82955.htm PyQuery库官方文档 初始化为PyQuery对
-
选择Python写网络爬虫的优势和理由
什么是网络爬虫? 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件 爬虫有什么用? 做为通用搜索引擎网页收集器.(google,baidu) 做垂直搜索引擎. 科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器.
-
python网络爬虫 CrawlSpider使用详解
CrawlSpider 作用:用于进行全站数据爬取 CrawlSpider就是Spider的一个子类 如何新建一个基于CrawlSpider的爬虫文件 scrapy genspider -t crawl xxx www.xxx.com 例:choutiPro LinkExtractor连接提取器:根据指定规则(正则)进行连接的提取 Rule规则解析器:将连接提取器提取到的连接进行请求发送,然后对获取的页面进行指定规则[callback]的解析 一个链接提取器对应唯一一个规则解析器 例:crawl
-
Python网络爬虫四大选择器用法原理总结
前几天小编连续写了四篇关于Python选择器的文章,分别用正则表达式.BeautifulSoup.Xpath.CSS选择器分别抓取京东网的商品信息.今天小编来给大家总结一下这四个选择器,让大家更加深刻的理解和熟悉Python选择器. 一.正则表达式 正则表达式为我们提供了抓取数据的快捷方式.虽然该正则表达式更容易适应未来变化,但又存在难以构造.可读性差的问题.当在爬京东网的时候,正则表达式如下图所示: 利用正则表达式实现对目标信息的精准采集 此外 ,我们都知道,网页时常会产生变更,导致网页中会发
-
python教程网络爬虫及数据可视化原理解析
目录 1 项目背景 1.1Python的优势 1.2网络爬虫 1.3数据可视化 1.4Python环境介绍 1.4.1简介 1.4.2特点 1.5扩展库介绍 1.5.1安装模块 1.5.2主要模块介绍 2需求分析 2.1 网络爬虫需求 2.2 数据可视化需求 3总体设计 3.1 网页分析 3.2 数据可视化设计 4方案实施 4.1网络爬虫代码 4.2 数据可视化代码 5 效果展示 5.1 网络爬虫 5.1.1 爬取近五年主要城市数据 5.1.2 爬取2019年各省GDP 5.1.3 爬取豆瓣电影
-
详解Python网络爬虫功能的基本写法
网络爬虫,即Web Spider,是一个很形象的名字.把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛. 1. 网络爬虫的定义 网络蜘蛛是通过网页的链接地址来寻找网页的.从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止.如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来.这样看来,网络爬虫就是一个爬行程序,一个抓取网页的
-
Python网络爬虫与信息提取(实例讲解)
课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解析HTML页面 4.Re框架:正则框架,提取页面关键信息 5.Scrapy框架:网络爬虫原理介绍,专业爬虫框架介绍 理念:The Website is the API ... Python语言常用的IDE工具 文本工具类IDE: IDLE.Notepad++.Sublime Text.Vim & Emacs.Atom.Komodo E
-
python网络爬虫学习笔记(1)
本文实例为大家分享了python网络爬虫的笔记,供大家参考,具体内容如下 (一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2.Beautiful Soup 模块使用Python编写,速度慢. 安装: pip install beautifulsoup4 3. Lxml 模块使用C语言编写,即快速又健壮,通常应该是最好的选择. (二) Lxml安装 pip install lxml 如果使用lxml的css选择器,还要安装下面的
-
python网络爬虫实战
目录 一.概述 二.原理 三.爬虫分类 1.传统爬虫 2.聚焦爬虫 3.通用网络爬虫(全网爬虫) 四.网页抓取策略 1.宽度优先搜索: 2.深度优先搜索: 3.最佳优先搜索: 4.反向链接数策略: 5.Partial PageRank策略: 五.网页抓取的方法 1.分布式爬虫 现在比较流行的分布式爬虫: 2.Java爬虫 3.非Java爬虫 六.项目实战 1.抓取指定网页 抓取某网首页 2.抓取包含关键词网页 3.下载贴吧中图片 4.股票数据抓取 六.结语 一.概述 网络爬虫(Web crawl
-
python网络爬虫精解之pyquery的使用说明
目录 一.pyquery的介绍 二.pyquery的使用 1.初始化工作 字符串 URL 文件初始化 2.查找节点 (1)查找子节点 (2)匹配父节点 (3)匹配兄弟节点 3.遍历 4.获取信息 (1)获取属性 (2)获取文本 5.节点操作 (1)为某个节点添加或删除一个class (2)attr.text.html (3)remove 6.伪类选择器 pyquery的使用 一.pyquery的介绍 使用pyquery需要在Web和了解jQuery的基础上,使用该CSS选择器. 二.pyquer
-
python网络爬虫精解之正则表达式的使用说明
目录 一.常见的匹配规则 二.常见的匹配方法 1.match() 2.search() 3.findall() 4.sub() 5.compile() 一.常见的匹配规则 二.常见的匹配方法 1.match() match()方法从字符串的起始位置开始匹配,该方法有两个参数,第一个是正则表达式,第二个是需要匹配的字符串: re.match(正则表达式,字符串) 如果该方法匹配成功,返回的是SRE_Match对象,如果未匹配到,则返回None. 返回成功后有两个方法,group()方法用来查看匹配
-
python网络爬虫精解之Beautiful Soup的使用说明
目录 一.Beautiful Soup的介绍 二.Beautiful Soup的使用 1.节点选择器 2.提取信息 3.关联选择 4.方法选择器 5.CSS选择器 一.Beautiful Soup的介绍 Beautiful Soup是一个强大的解析工具,它借助网页结构和属性等特性来解析网页. 它提供一些函数来处理导航.搜索.修改分析树等功能,Beautiful Soup不需要考虑文档的编码格式.Beautiful Soup在解析时实际上需要依赖解析器,常用的解析器是lxml. 二.Beautif
-
Python网络爬虫实例讲解
聊一聊Python与网络爬虫. 1.爬虫的定义 爬虫:自动抓取互联网数据的程序. 2.爬虫的主要框架 爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器中,将有价值的数据输出. 3.爬虫的时序图 4.URL管理器 URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取.URL管理器的主要职能如下图