Pandas实现聚合运算agg()的示例代码
目录
- 前言
- 1. 创建DataFrame对象
- 2. 单列聚合
- 3. 多列聚合
- 4. 多种聚合运算
- 5. 多种聚合运算并更改列名
- 6. 不同的列运用不同的聚合函数
- 7. 使用自定义的聚合函数
- 8. 方便的descibe
前言
在数据分析中,分组聚合二者缺一不可。对数据聚合(求和、平均值等)通常是不可避免的。pd.agg()很方便进行聚合操作。
1. 创建DataFrame对象
import pandas as pd
df1 = pd.DataFrame({'sex':list('FFMFMMF'),'smoker':list('YNYYNYY'),'age':[21,30,17,37,40,18,26],'weight':[120,100,132,140,94,89,123]})
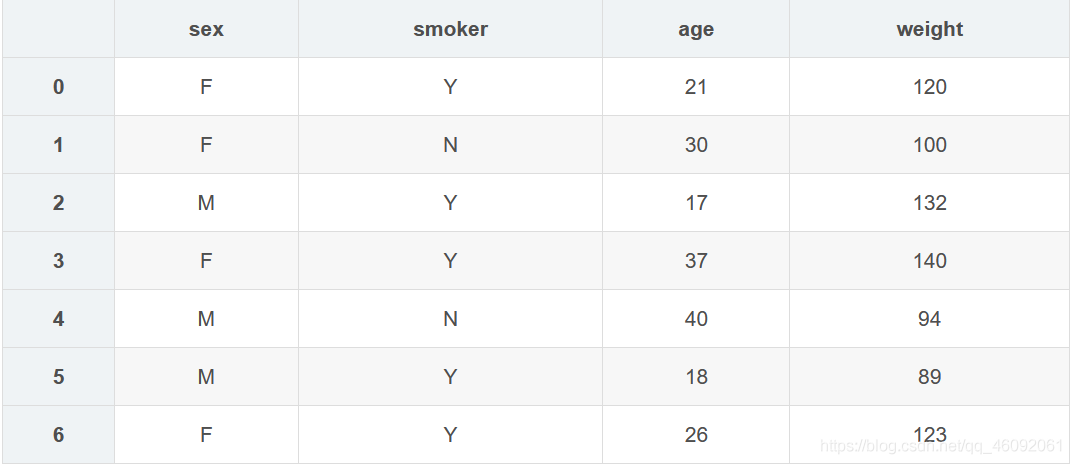
grouped = df1.groupby(['sex','smoker']) # sex有 F M 二值,smoker有 Y N 二值,故分成四组。
2. 单列聚合
grouped['age'].agg('mean')
sex smoker
F N 30.0
Y 28.0
M N 40.0
Y 17.5
Name: age, dtype: float64
3. 多列聚合
grouped.agg('mean')

4. 多种聚合运算
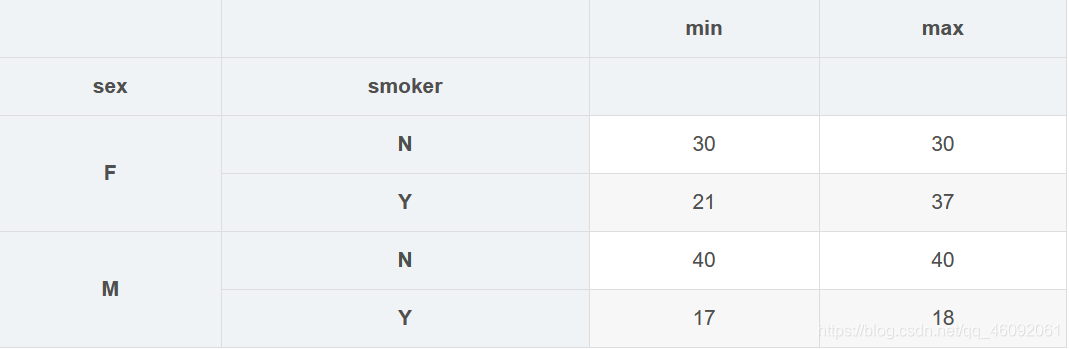
grouped['age'].agg(['min','max'])
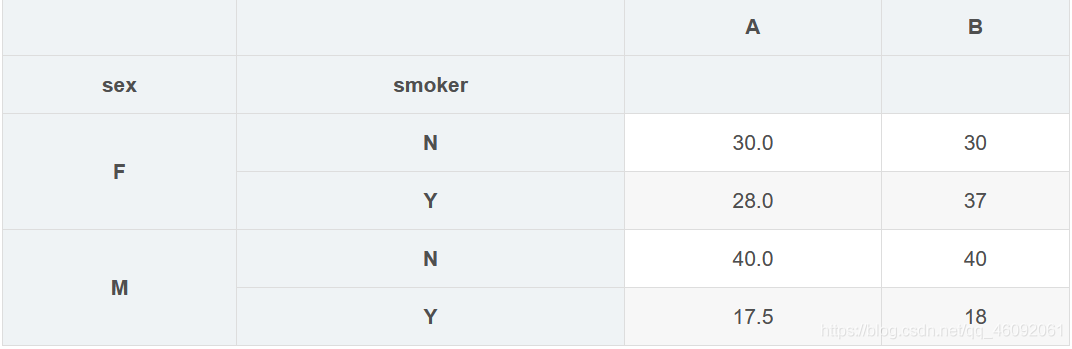
5. 多种聚合运算并更改列名
grouped['age'].agg([('A','mean'),('B','max')])
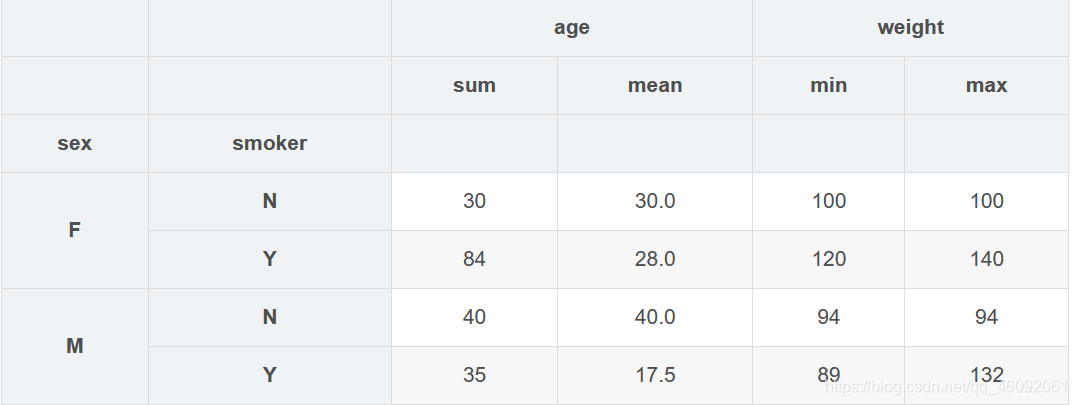
6. 不同的列运用不同的聚合函数
grouped.agg({'age':['sum','mean'], 'weight':['min','max']})
7. 使用自定义的聚合函数
def Max_cut_Min(group):
return group.max()-group.min()
grouped.agg(Max_cut_Min)

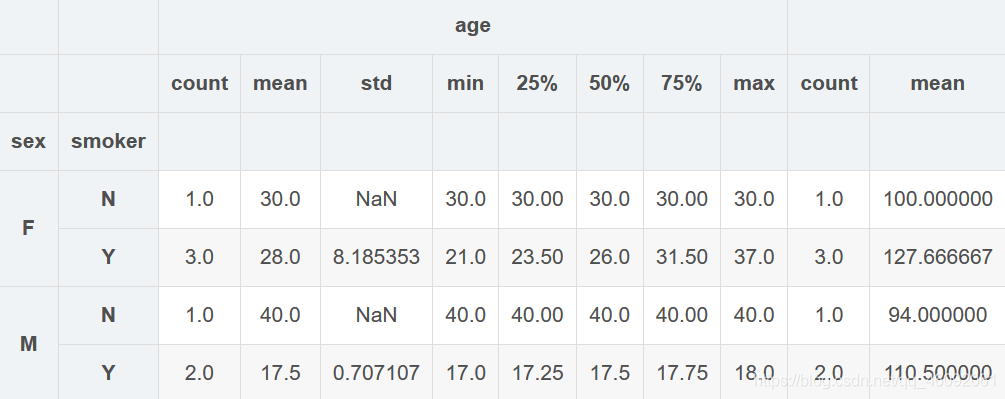
8. 方便的descibe
grouped.describe()
参考博客:link
到此这篇关于Pandas实现聚合运算agg()的示例代码的文章就介绍到这了,更多相关Pandas 聚合运算agg()内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas聚合运算和分组运算的实现示例
1.聚合运算 (1)使用内置的聚合运算函数进行计算 1>内置的聚合运算函数 sum(),mean(),max(),min(),size(),describe()...等等 2>应用聚合运算函数进行计算 import numpy as np import pandas as pd #创建df对象 dict_data = { 'key1':['a','b','c','d','a','b','c','d'], 'key2':['one','two','three','one','two','thre
-

Pandas实现聚合运算agg()的示例代码
目录 前言 1. 创建DataFrame对象 2. 单列聚合 3. 多列聚合 4. 多种聚合运算 5. 多种聚合运算并更改列名 6. 不同的列运用不同的聚合函数 7. 使用自定义的聚合函数 8. 方便的descibe 前言 在数据分析中,分组聚合二者缺一不可.对数据聚合(求和.平均值等)通常是不可避免的.pd.agg()很方便进行聚合操作. 1. 创建DataFrame对象 import pandas as pd df1 = pd.DataFrame({'sex':list('FFMFMMF')
-
pandas中聚合函数agg的具体用法
今天看到pandas的聚合函数agg,比较陌生,平时的工作中处理数据的时候使用的也比较少,为了加深印象,总结一下使用的方法,其实还是挺好用的. DataFrame.agg(func,axis = 0,* args,** kwargs ) func : 函数,函数名称,函数列表,字典{‘行名/列名’,‘函数名’} 使用指定轴上的一个或多个操作进行聚合. agg是一个聚合函数,聚合函数操作始终是在轴(默认是列轴,也可设置行轴)上执行,不同于 numpy聚合函数 (np.sum() //求和:np.p
-
pandas实现按行选择的示例代码
目录 1.自定义行索引 2. 按普通索引选择数据 2.1 按普通索引选择单行数据 2.2 按行索引选择多行数据 3.按位置索引选择数据 3.2 按位置索引选择多行数据 4.选择连续多行数据 5.选择满足条件的行 5.1单个条件选择 5.2 多个条件选择 5.2.1 多个条件是且的关系 5.2.2 多个条件是或的关系 本文所用到的Excel表格内容如下: 1.自定义行索引 dataframe读取Excel表格时是由自定义行索引的.这里为了展示效果,先进行自定义行索引的操作 import panda
-
Pandas读取并修改excel的示例代码
一.前言 最近总是和excel打交道,由于数据量较大,人工来修改某些数据可能会有点浪费时间,这时候就使用到了Python数据处理的神器-–Pandas库,话不多说,直接上Pandas. 二.安装 这次使用的python版本是python2.7,安装python可以去python的官网进行下载,这里不多说了. 安装完成后使用Python自带的包管理工具pip可以很快的安装pandas. pip install pandas 如果使用的是Anaconda安装的Python,会自带pandas. 三.
-
Python使用pandas导入csv文件内容的示例代码
目录 使用pandas导入csv文件内容 1. 默认导入 2. 指定分隔符 3. 指定读取行数 4. 指定编码格式 5. 列标题与数据对齐 使用pandas导入csv文件内容 1. 默认导入 在Python中导入.csv文件用的方法是read_csv(). 使用read_csv()进行导入时,指定文件名即可 import pandas as pd df = pd.read_csv(r'G:\test.csv') print(df) 2. 指定分隔符 read_csv()默认文件中的数据都是以逗号
-
java图形化界面实现简单混合运算计算器的示例代码
写了好几天了终于写完了这个四则运算计算器,总代码放在后面 截图如下: 首先是布局都比较简单,最上面的一个框是总的输出框, 第二个框是每次输入的数字显示在框内, 对于每一个按钮都增加监听器, 对于数字按钮:当长度大于8的 或者等号已经出现之后就不再处理按钮事件 if(e.getSource().equals(button1)) { s=numberText.getText(); //数字长度大于8或者等号已出现 if(s.length()>8 || equalbook == 1) { } else
-
pandas实现数据合并的示例代码
目录 一. concat--数据合并 1.1 概述 1.2 指定合并的轴方向--axis 1.3 指定合并轴另外一个轴标签是否合并--join 1.4 指定合并轴原标签是否需要变化--ignore_index 1.5 指定合并轴方向新的index,便于区分数据--keys 1.6 指定合并轴方向新的index 的含义名称,一般和keys一起使用,让合并后的数据更直观--names 1.7 指定合并时是否允许合并轴上有重复标签--verify_integrity 二. merge--数据连接 2.
-
pandas实现数据可视化的示例代码
目录 一.概述 1.1 plot函数参数 1.2 本文用到的数据源说明 二.折线图--kind='line' 三.柱状图--kind='bar' 3.1 各组数据(列)分开展示 3.2 各组(列)数据合并展示--stacked 3.3 横向柱状图--kind='barh' 四.直方图--kind='hist' 4.1 概述 4.2 自定义直方图横向区间数量 4.3 多子图展示多序列数据 4.4 一维数据密度图--kind='kde' 4.5 累积直方图--cumulative = True 五
-
Python数据分析之如何利用pandas查询数据示例代码
前言 在数据分析领域,最热门的莫过于Python和R语言,本文将详细给大家介绍关于Python利用pandas查询数据的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 示例代码 这里的查询数据相当于R语言里的subset功能,可以通过布尔索引有针对的选取原数据的子集.指定行.指定列等.我们先导入一个student数据集: student = pd.io.parsers.read_csv('C:\\Users\\admin\\Desktop\\student.csv')