Python爬取12306车次信息代码详解
详情查看下面的代码:
如果被识别就要添加一个cookie如果没有被识别的话就要一个user—agent就好了。如果出现乱码就设置编码格式为utf-8
#静态的数据一般在elements中(复制文字到sources按ctrl+f搜索。找到的为静态),而动态去network中去寻找相关的信息
import requests
import re
def send_request():
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
,'Cookie':'_uab_collina=159618052151589201474313; JSESSIONID=D33C89D8BEC6A692C79CFA69FC0B0D29; BIGipServerotn=233832970.24610.0000; BIGipServerpool_passport=216859146.50215.0000; RAIL_EXPIRATION=1596443951465; RAIL_DEVICEID=nMo94O2Z21cXLblW7otLoxUZ_LP9Q01PYj_I89OqU6MqjxyX9814Jc3CH5TNwgBVJqnBaBG8OGiBWo2QtNcu5wVu-asNk6YLa49g0fMwVp03XFJQ-GkhHYHcqIgUd-nqQB_VEdWH1Om_D2yAgIu8QcEavt02pmH5; route=c5c62a339e7744272a54643b3be5bf64; _jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_toStation=%u5929%u6D25%2CTJP; _jc_save_fromDate=2020-07-31; _jc_save_toDate=2020-07-31; _jc_save_wfdc_flag=dc'}#创建头部信息
url='https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2020-07-31&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=TJP&purpose_codes=ADULT'
#设置编码格式。防止乱码
resp=requests.get(url,headers=headers)
resp.encoding='utf-8'
return resp
#解析数据
#{}是字典。根据key获取值。
def parse_json(resp,city):
json_ticket=resp.json()#将相应的数据转换为json
data_list=json_ticket['data']['result']#得到车次的列表
lst=[]#列表
for item in data_list:
#遍历车次信息进行分割
d=item.split('|')
lst.append([d[3],city[d[6]],city[d[7]],d[31],d[30],d[13]])
return lst
'''
d[3]从列表中获取索引为3的表示车次
d[6]查询起始站
d[7]查询到达站
d[31]一等座
d[30]表示二等座
d[13]表示出行时间'''
#获得station_name的信息
def get_city():
url='https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9151'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
resp=requests.get(url,headers=headers)
resp.encoding='utf-8'
#进行数据的提取(只要一部分)
stations=re.findall('([\u4e00-\u9fa5]+)\|([A-Z]+)',resp.text)
#将列表进行转换为字典
stations_data=dict(stations)
#key与value进行互换
station_d={}#空字典。用于完成上述操作
for item in stations_data:
station_d[stations_data[item]]=item
#print(station_d)
return station_d
def start():
lst=parse_json(send_request(),get_city())
#进行数据的筛选(得到有效的数据)
for i in lst:
if i[3]!='无' and i[3]!='':
print(i)
if __name__=='__main__':
start() #开始
运行的截图:
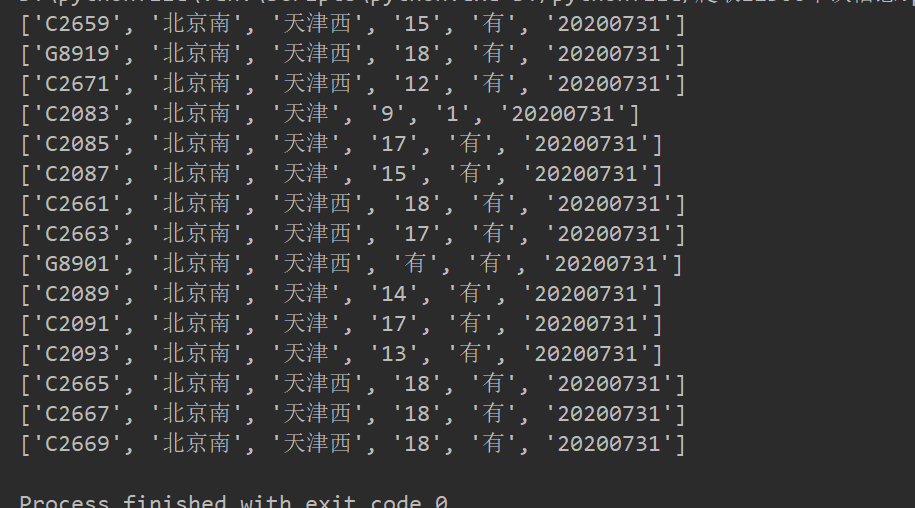
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python自动12306抢票软件实现代码
昨天我发的是抓取的12306数据包,然后分析了一下,今天按照昨天的分析 用代码实现了,如果有需要的同学们可以看一下,实现的功能有,登录,验证码识别,自动查票,有余票点击预定, 差了最后一步提交订单.同学们可以自己研究一下. import requests import time import dmpt import re import random from copyheaders import headers_raw_to_dict DEFAULT_HEADERS={ 'Host':'kyfw
-

Python 识别12306图片验证码物品的实现示例
1.PIL介绍以及图片分割 Python 3 安装: pip3 install Pillow 1.1 image 模块 Image模块是在Python PIL图像处理中常见的模块,主要是用于对这个图像的基本处理,它配合open.save.convert.show-等功能使用. from PIL import Image #打开文件代表打开pycharm中的文件 im = Image.open('1.jpg') #展示图片 im.show() 1.Crop类 拷贝这个图像.如果用户想粘贴一些数据
-
python实现12306登录并保存cookie的方法示例
经过倒腾12306的登录,还是实现了,请求头很重要...各位感兴趣的可以继续写下去..... import sys import time import requests from PIL import Image import json import os import Headers import SessionUtil import UrlUtils class Ticket(object): def __init__(self): self.answer = { "1": &q
-
Python + selenium + requests实现12306全自动抢票及验证码破解加自动点击功能
测试结果: 整个买票流程可以再快一点,不过为了稳定起见,有些地方等待了一些时间 完整程序,拿去可用 整个程序分了三个模块:购票模块(主体).验证码识别模块.余票查询模块 购票模块: from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.commo
-
Python实现12306火车票抢票系统
Python实现12306火车票抢票系统效果图如下所示: 具体代码如下所示: import urllib.request as request import http.cookiejar as cookiejar import re import os import smtplib from email.mime.text import MIMEText import time user = '' #登陆邮箱 pwd = ''#邮箱密码 to = [''] #发送的邮箱 with open('D
-
Python爬虫实战之12306抢票开源
今天就和大家一起来讨论一下python实现12306余票查询(pycharm+python3.7),一起来感受一下python爬虫的简单实践 我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包 余票查询界面 可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看 https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-2
-
Python爬虫 12306抢票开源代码过程详解
今天就和大家一起来讨论一下python实现12306余票查询(pycharm+python3.7),一起来感受一下python爬虫的简单实践 我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包 可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看 https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-21&leftT
-
python自动登录12306并自动点击验证码完成登录的实现源代码
以下代码可自动登录12306 - 包括输入用户名密码以及自动识别验证码并点击验证码登陆.该源码需要稍作修改: 把 username.send_keys('xxxxxxx') 中的 xxxxxx 改为 你自己的12306账号. 把 password.send_keys('yyyyyy') 中的 yyyyy 改为自己的 12306 密码. 即可运行. 该源码把自动抢票的核心功能:识别验证码并点击验证码登陆实现了. 把代码稍作加工,即可变为自己的自动抢票代码. 运行环境 - 需要安装p
-
使用Python+Splinter自动刷新抢12306火车票
一年一度的春运又来了,今年我自己写了个抢票脚本.使用Python+Splinter自动刷新抢票,可以成功抢到.(依赖自己的网络环境太厉害,还有机器的好坏) Splinter是一个使用Python开发的开源Web应用测试工具,它可以帮你实现自动浏览站点和与其进行交互,Splinter执行的时候会自动打开你指定的浏览器,访问指定的URL.然后你所开发的模拟的任何行为,都会自动完成,你只需要坐在电脑面前,像看电影一样看着屏幕上各种动作自动完成然后收集结果即可. 12306抢票Python代码片段 1.
-
Python爬取12306车次信息代码详解
详情查看下面的代码: 如果被识别就要添加一个cookie如果没有被识别的话就要一个user-agent就好了.如果出现乱码就设置编码格式为utf-8 #静态的数据一般在elements中(复制文字到sources按ctrl+f搜索.找到的为静态),而动态去network中去寻找相关的信息 import requests import re def send_request(): headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win6
-
Python爬取附近餐馆信息代码示例
本代码主要实现抓取大众点评网中关村附近的餐馆有哪些,具体如下: import urllib.request import re def fetchFood(url): # 模拟使用浏览器浏览大众点评的方式浏览大众点评 headers = {'User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'} ope
-
Python爬取豆瓣视频信息代码实例
这篇文章主要介绍了Python爬取豆瓣视频信息代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quotefrom pyquery import PyQuery as pqimport requestsimport pandas as pddef get_text_page (movie_name)
-
python爬取天气数据的实例详解
就在前几天还是二十多度的舒适温度,今天一下子就变成了个位数,小编已经感受到冬天寒风的无情了.之前对获取天气都是数据上的搜集,做成了一个数据表后,对温度变化的感知并不直观.那么,我们能不能用python中的方法做一个天气数据分析的图形,帮助我们更直接的看出天气变化呢? 使用pygal绘图,使用该模块前需先安装pip install pygal,然后导入import pygal bar = pygal.Line() # 创建折线图 bar.add('最低气温', lows) #添加两线的数据序列 b
-
python爬取各省降水量及可视化详解
在具体数据的选取上,我爬取的是各省份降水量实时数据 话不多说,开始实操 正文 1.爬取数据 使用python爬虫,爬取中国天气网各省份24时整点气象数据 由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据-ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(<class = split>时,却空空如也.在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知此为动态数据,无法用该方法进行爬取
-
详解python 爬取12306验证码
一个简单的验证码爬取程序 本文介绍了在Python2.7环境下爬取网站验证码: 思路就是获取验证码对应的url,然后发起requst请求,读取该URL对应的内容,然后写入到一个本地文件,实现一个验证码的保存.大量下载可以把以上程序写入一个死循环 代码实现部分: import ssl import urllib2 i=1 import time while(1): #不加的话,无法访问12306 ssl._create_default_https_context = ssl._create_unv
-
python登录并爬取淘宝信息代码示例
本文主要分享关于python登录并爬取淘宝信息的相关代码,还是挺不错的,大家可以了解下. #!/usr/bin/env python # -*- coding:utf-8 -*- from selenium import webdriver import time import datetime import traceback import logging import os from selenium.webdriver.common.action_chains import ActionC
-
PyQt5爬取12306车票信息程序的实现
1.搭载QT环境 按win+R输入 pip install pyqt5 下载QT5 当然也可以去Qt的官网的下载 ,使用命令行更快捷方便 所以建议使用命令行 ,去官网下载安装有它的好处就是不用自己安装 toosl 作者使用的是pyCharm 完成后期的后台程序设置,使用pyCharm 外部工具链接把Designer,pyUIC,qrcTopy程序加进去 2.主窗体设置 打Qt5主程序设置主窗体,设计完成保存为windows 添加到创建好的python项目中,然后选中单击右键->External
-
python爬虫系列Selenium定向爬取虎扑篮球图片详解
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员还是写个程序来进行吧! 所以我通过Python+Selenium+正则表达式+urllib2进行海量图片爬取. 运行效果: http://photo.hupu.com/nba/tag/马刺 http://photo.hupu.com/nba/tag/陈露 源代码: # -*- coding: utf
-
python爬取哈尔滨天气信息
本文实例为大家分享了python爬取哈尔滨天气信息的具体代码,供大家参考,具体内容如下 环境: windows7 python3.4(pip install requests:pip install BeautifulSoup4) 代码: (亲测可以正确执行) # coding:utf-8 """ 总结一下,从网页上抓取内容大致分3步: 1.模拟浏览器访问,获取html源代码 2.通过正则匹配,获取指定标签中的内容 3.将获取到的内容写到文件中 ""&qu