python爬虫scrapy基本使用超详细教程
一、介绍
官方文档:中文2.3版本
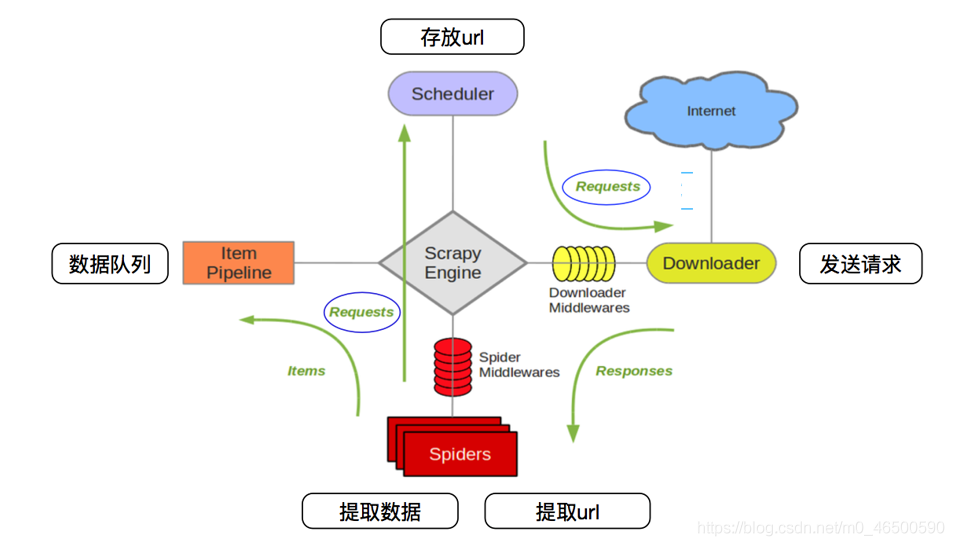
下面这张图大家应该很熟悉,很多有关scrapy框架的介绍中都会出现这张图,感兴趣的再去查询相关资料,当然学会使用scrapy才是最主要的。
二、基本使用
2.1 环境安装
1.linux和mac操作系统:
pip install scrapy
2.windows系统:
- 先安装wheel:
pip install wheel - 下载twisted:下载地址
- 安装twisted:
pip install Twisted‑17.1.0‑cp36‑cp36m‑win_amd64.whl(记得带后缀) pip install pywin32pip install scrapy
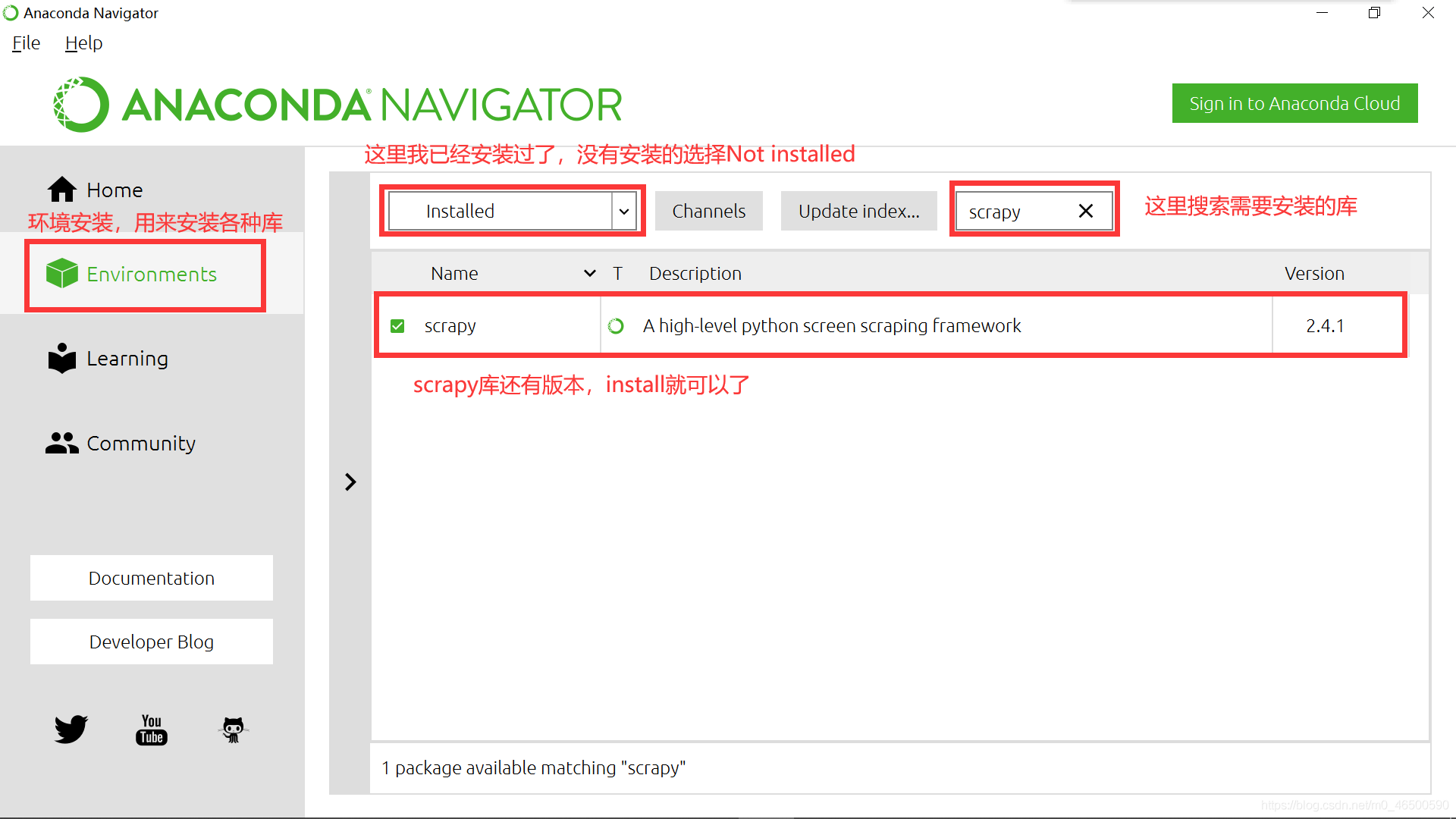
3.Anaconda(推荐)
在我一开始学python使用的就是python3.8,在安装各种库的时候,总会有各种报错,真的有点让人奔溃。Anaconda在安装过程中就会安装一些常用的库,其次,当我们想要安装其他库时也很方便。当然大家也可以选择安装其他的一些软件,
2.2 scrapy使用流程
这里默认大家已经安装好scrapy库,大家要记得要在命令行里输入以下命令啊。(我使用的anaconda的命令行)
创建工程
scrapy startproject projectName


进入工程目录:这里一定要进入到刚才创建好的目录中
cd projectName

创建爬虫文件:创建的爬虫文件会出现在之前创建好的spiders文件夹下
scrapy genspider spiderName www.xxx.com


编写相关代码
执行爬虫文件
scrapy crawl spiderName

2.3 文件解析
import scrapy
class HelloSpider(scrapy.Spider):
name = 'hello' # 爬虫名称
# 允许的域名:限定start_urls列表当中哪些url可以进行请求的发送
# 通常情况下我们不会使用
# allowed_domains = ['www.baidu.com']
# 起始的url列表:scrapy会自动对start_urls列表中的每一个url发起请求
# 我们可以手动添加我们需要访问的url
start_urls = ['https://www.baidu.com/','https://www.csdn.net/']
def parse(self, response): # 当scrapy自动向start_urls中的每一个url发起请求后,会将响应对象保存在response对象中
# 代码一般是在parse方法中写
print("response:",response)

2.4 settings.py一些常见的设置
相当于requests中的headers参数中的User-Agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.68'
可以忽略或者不遵守robots协议
ROBOTSTXT_OBEY = False
只有程序出现错误的情况下,才显示日志文件,程序正常执行时只会输出我们想要的结果
LOG_LEVEL='ERROR' == scrapy crawl spiderName --nolog //二者是等价的,当然还是推荐使用前者
未加LOG_LEVEL='ERROR'
加LOG_LEVEL='ERROR'之后

scrapy 爬取文件保存为CSV文件中文乱码的解决办法
//下面的设置可能会导致繁体出现,可以逐个试一下 FEED_EXPORT_ENCODING = "gb18030" FEED_EXPORT_ENCODING = "utf-8" FEED_EXPORT_ENCODING = "gbk"

三、实例
3.1 实例要求
目的:爬取百度网页的百度热榜

3.2 实例代码
实例代码

3.3 输出结果
结果

到此这篇关于python爬虫scrapy基本使用超详细教程的文章就介绍到这了,更多相关python爬虫scrapy使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便.使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发. 首先先要回答一个问题. 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):新建一个新的爬虫项目 明确目标(Item
-
Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python实现,完全开源,代码托管在Github上,可运行在Linux,Windows,Mac和BSD平台上,基于Twisted的异步网络库来处理网络通讯,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片. 二.Scrapy安装指南 我们的安装步骤假设你已经安装一下内容:<1>
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
Python爬虫scrapy框架Cookie池(微博Cookie池)的使用
下载代码Cookie池(这里主要是微博登录,也可以自己配置置其他的站点网址) 下载代码GitHub:https://github.com/Python3WebSpider/CookiesPool 下载安装过后注意看网页下面的相关基础配置和操作!!!!!!!!!!!!! 自己的设置主要有下面几步: 1.配置其他设置 2.设置使用的浏览器 3.设置模拟登陆 源码cookies.py的修改(以下两处不修改可能会产生bug): 4.获取cookie 随机获取Cookies: http://localho
-
Python之Scrapy爬虫框架安装及使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. 本文档将
-
Python之Scrapy爬虫框架安装及简单使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫. 本文档将通过介绍Sc
-
使用Python的Scrapy框架编写web爬虫的简单示例
在这个教材中,我们假定你已经安装了Scrapy.假如你没有安装,你可以参考这个安装指南. 我们将会用开放目录项目(dmoz)作为我们例子去抓取. 这个教材将会带你走过下面这几个方面: 创造一个新的Scrapy项目 定义您将提取的Item 编写一个蜘蛛去抓取网站并提取Items. 编写一个Item Pipeline用来存储提出出来的Items Scrapy由Python写成.假如你刚刚接触Python这门语言,你可能想要了解这门语言起,怎么最好的利用这门语言.假如你已经熟悉其它类似的语言,想要快速
-
讲解Python的Scrapy爬虫框架使用代理进行采集的方法
1.在Scrapy工程下新建"middlewares.py" # Importing base64 library because we'll need it ONLY in case if the proxy we are going to use requires authentication import base64 # Start your middleware class class ProxyMiddleware(object): # overwrite process
-
python爬虫scrapy基本使用超详细教程
一.介绍 官方文档:中文2.3版本 下面这张图大家应该很熟悉,很多有关scrapy框架的介绍中都会出现这张图,感兴趣的再去查询相关资料,当然学会使用scrapy才是最主要的. 二.基本使用 2.1 环境安装 1.linux和mac操作系统: pip install scrapy 2.windows系统: 先安装wheel:pip install wheel 下载twisted:下载地址 安装twisted:pip install Twisted‑17.1.0‑cp36‑cp36m‑win_amd
-
python中spy++的使用超详细教程
1.spy++的基本操作 我们下载spy++: Microsoft Spy++ V15.0.26724.1 简体中文绿色版 64位 1.1 窗口属性查找 拖住中间的"寻找工具"放到想要定位的软件上,然后松开 以微信为例,我们会得到"微信"这个窗口的句柄,为"00031510",注意这个句柄是"十六进制",即"0x31510". 点击ok我们会看到更详细的属性信息 1.2 窗口spy++定位 同理拖放到&qu
-
Python编辑器Pycharm安装配置超详细教程
今天给大家推荐一款很好用的Python编辑器,全世界90%Python开发者都会用的开发工具------Pycharm,完全免费哦 1. 百度搜索pycharm,进入pycharm官网,带有’PyCharm: the Python IDE for Professional’字样的就是官网 2. 在官网首页点击如下图所示任意’Download’进入下载页面 3. 在下载页面有如下图两个下载接口,一个专业版,一个社区版,推荐使用社区版,免费,然后点击右边红框里面的’Download’进行下载,这里下
-
python封装成exe的超详细教程
目录 第一种:.py文件直接封装成exe 第二种:整个项目封装成exe 补充说明: 总结 第一种:.py文件直接封装成exe 1.cmd进入py文件所在的目录 备注:在py文件所在的目录下,按住shift+鼠标右击,然后找到“在此处打开PowerShell窗口”,即可进入当前目录 2.输入以下代码: 备注:使用-D制作出来的exe比使用-F的快很多,因为-F把所有dll文件都打包到一个exe中了(-F这时候exe会很大,加载变慢,推荐-D) #-w:不显示后台 -i添加图标 pyinstalle
-
Python操作Redis数据库的超详细教程
目录 介绍 常用数据结构 安装 连接 String 字符串(键值对) List 列表 Hash 哈希 Set 集合 Zset 有序集合 Bitmap 位图 全局函数 总结 介绍 Redis是一个开源的基于内存也可持久化的Key-Value数据库,采用ANSI C语言编写.它拥有丰富的数据结构,拥有事务功能,保证命令的原子性.由于是内存数据库,读写非常高速,可达10w/s的评率,所以一般应用于数据变化快.实时通讯.缓存等.但内存数据库通常要考虑机器的内存大小. Redis有16个逻辑数据库(db0
-
scrapy+scrapyd+gerapy 爬虫调度框架超详细教程
目录 一.scrapy 1.1 概述 1.2 构成 1.3 安装和使用 二.scrapyd 2.1 简介 2.2 安装和使用 三.gerapy 3.1 简介 3.2 安装使用 四.scrapy+scrapyd+gerapy的结合使用 4.1 创建scrapy项目 4.2 部署打包scrapy项目 4.3 运行 五.填坑 5.1 运行scrapy爬虫报错 5.2 scrapyd 运行 scrapy 报错 一.scrapy 1.1 概述 Scrapy,Python开发的一个快速.高层次的屏幕抓取和w
-
python UIAutomator2使用超详细教程
一.环境要求 python 3.6+ android 4.4+ 二.介绍 uiautomator2 是一个可以使用Python对Android设备进行UI自动化的库.其底层基于Google uiautomator,Google提供的uiautomator库可以获取屏幕上任意一个APP的任意一个控件属性,并对其进行任意操作. 三.库地址 GitHub地址: https://github.com/openatx/uiautomator2 https://github.com/openatx/uiau
-
Python matplotlib超详细教程实现图形绘制
目录 前言 1. matplotlib.patches概述 2. 绘制图形方法 3. 绘制图形步骤 4. 绘制图形属性 设置透明度 设置颜色 5. 小试牛刀 前言 我们前面对matplotlib模块底层结构学习,对其pyplot类(脚本层)类提供的绘制折线图.柱状图.饼图.直方图等统计图表的相关方法,列举往期文章如下. Python利用 matplotlib 绘制直方图 Python用 matplotlib 绘制柱状图 python 用matplotlib绘制折线图详情 Python利用matp
-
Windows下PyCharm配置Anaconda环境(超详细教程)
首先来明确一下Python.PyCharm和Anaconda的关系 1.Python是一种解释型.面向对象.动态数据类型的高级程序设计语言. 虽然Python3.5自带了一个解释器IDLE用来执行.py脚本,但是却不利于我们书写调试大量的代码.常见的是用Notepade++写完脚本,再用idle来执行,但却不便于调试.这时候就出现了PyCharm等IDE,来帮助我们调试开发. 2.PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调
-
PyCharm2020.3.2安装超详细教程
PyCharm是目前 Python 语言最好用的集成开发工具,可以帮助用户提高开发效率. 1.下载 Pycharm 在 Pycharm 的官网即可下载,链接如下 PyCharm for Windows :https://www.jetbrains.com/pycharm/download/#section=windows PyCharm for Mac :https://www.jetbrains.com/pycharm/download/#section=mac PyCharm for Lin