Go实现分布式唯一ID的生成之雪花算法
目录
- 背景:
- 特性:
- 雪花算法:
分布式唯一ID的生成
背景:
在分布式架构下,唯一序列号生成是我们在设计一个尤其是数据库使用分库分表的时候会常见的一个问题
特性:
全局唯一,这是基本要求,不能出现重复数字类型,趋势递增,后面的ID必须比前面的大长度短,能够提高查询效率,这也是从MySQL数据库规范出发的,尤其是ID作为主键时**信息安全,**如果ID连续生成,势必会泄露业务信息,所以需要无规则不规则高可用低延时,ID生成快,能够扛住高并发,延时足够低不至于成为业务瓶颈.
雪花算法:
snowflake是推特开源的分布式ID生成算法
结果: long 型的ID号(64位的ID号)
核心思想(生成的ID号是64位那么就对64位进行划分赋予特别的含义):
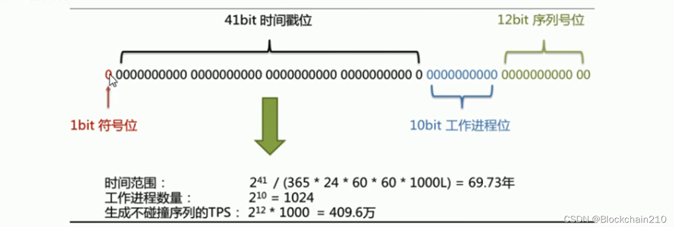
41bit-时间戳决定了该算法生成ID号的可用年限.
10bit-工作机器编号决定了该分布式系统的扩容性即机器数量.
12bit-序列号决定了每毫秒单机系统可以生成的序列号
拓展:什么是时间戳?
北京时间1970年01月01日08时00分00秒到此时时刻的总秒数
优势:
//实现方法:
package main
import (
"errors"
"fmt"
"sync"
"time"
)
/*
雪花算法(snowFlake)的具体实现方案:
*/
type SnowFlake struct{
mu sync.Mutex
//雪花算法开启时的起始时间戳
twepoch int64
//每一部分占用的位数
workerIdBits int64 //每个数据中心的工作机器的编号位数
datacenterIdBits int64 //数据中心的编号位数
sequenceBits int64 //每个工作机器每毫秒递增的位数
//每一部分最大的数值
maxWorkerId int64
maxDatacenterId int64
maxSequence int64
//每一部分向左移动的位数
workerIdShift int64
datacenterIdShift int64
timestampShift int64
//当前数据中心ID号
datacenterId int64
//当前机器的ID号
workerId int64
//序列号
sequence int64
//上一次生成ID号前41位的毫秒时间戳
lastTimestamp int64
}
/*
获取毫秒的时间戳
*/
func (s *SnowFlake)timeGen()int64{
return time.Now().UnixMilli()
}
/*
获取比lastTimestamp大的当前毫秒时间戳
*/
func (s *SnowFlake)tilNextMills()int64{
timeStampMill:=s.timeGen()
for timeStampMill<=s.lastTimestamp{
timeStampMill=s.timeGen()
}
return timeStampMill
}
func (s *SnowFlake)NextId()(int64,error){
s.mu.Lock()
defer s.mu.Unlock()
nowTimestamp:=s.timeGen()//获取当前的毫秒级别的时间戳
if nowTimestamp<s.lastTimestamp{
//系统时钟倒退,倒退了s.lastTimestamp-nowTimestamp
return -1,errors.New(fmt.Sprintf("clock moved backwards, Refusing to generate id for %d milliseconds",s.lastTimestamp-nowTimestamp))
}
if nowTimestamp==s.lastTimestamp{
s.sequence=(s.sequence+1)&s.maxSequence
if s.sequence==0{
//tilNextMills中有一个循环等候当前毫秒时间戳到达lastTimestamp的下一个毫秒时间戳
nowTimestamp=s.tilNextMills()
}
}else{
s.sequence=0
}
s.lastTimestamp=nowTimestamp
return (nowTimestamp-s.twepoch)<<s.timestampShift| //时间戳差值部分
s.datacenterId<<s.datacenterIdShift| //数据中心部分
s.workerId<<s.workerIdShift| //工作机器编号部分
s.sequence, //序列号部分
nil
}
func NewSnowFlake(workerId int64,datacenterId int64)(*SnowFlake,error){
mySnow:=new(SnowFlake)
mySnow.twepoch=time.Now().Unix() //返回当前时间的时间戳(时间戳是指北京时间1970年01月01日8时0分0秒到此时时刻的总秒数)
if workerId<0||datacenterId<0{
return nil,errors.New("workerId or datacenterId must not lower than 0 ")
}
/*
标准的雪花算法
*/
mySnow.workerIdBits =5
mySnow.datacenterIdBits=5
mySnow.sequenceBits=12
mySnow.maxWorkerId=-1^(-1<<mySnow.workerIdBits) //64位末尾workerIdBits位均设为1,其余设为0
mySnow.maxDatacenterId=-1^(-1<<mySnow.datacenterIdBits) //64位末尾datacenterIdBits位均设为1,其余设为0
mySnow.maxSequence=-1^(-1<<mySnow.sequenceBits) //64位末尾sequenceBits位均设为1,其余设为0
if workerId>=mySnow.maxWorkerId||datacenterId>=mySnow.maxDatacenterId{
return nil,errors.New("workerId or datacenterId must not higher than max value ")
}
mySnow.workerIdShift=mySnow.sequenceBits
mySnow.datacenterIdShift=mySnow.sequenceBits+mySnow.workerIdBits
mySnow.timestampShift=mySnow.sequenceBits+mySnow.workerIdBits+mySnow.datacenterIdBits
mySnow.lastTimestamp=-1
mySnow.workerId=workerId
mySnow.datacenterId=datacenterId
return mySnow,nil
}
func main(){
//模拟实验是生成并发400W个ID,所需要的时间
mySnow,_:=NewSnowFlake(0,0)//生成雪花算法
group:=sync.WaitGroup{}
startTime:=time.Now()
generateId:=func (s SnowFlake,requestNumber int){
for i:=0;i<requestNumber;i++{
s.NextId()
group.Done()
}
}
group.Add(4000000)
//生成并发的数为4000000
currentThreadNum:=400
for i:=0;i<currentThreadNum;i++{
generateId(*mySnow,10000)
}
group.Wait()
fmt.Printf("time: %v\n",time.Now().Sub(startTime))
}

以上分析生成400WID号只需要803.1006ms(所以单机上可以每秒生成的ID数在400W以上)
优点:
毫秒数在高位,自增序列在低位,整个ID都是趋势递增不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成的ID性能也是非常高的可以根据自身业务特性分配bit位,非常灵活
缺陷:
1. 依赖机器时钟,如果**机器时钟回拨**,会导致重复ID生成.
2. 在单机上是递增的,但是由于设计到分布式环境下,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况.
如何解决单机系统中时钟回拨问题:
可以分为两种情况:
1. 如果**时间回拨时间较短,比如配置5ms以内**,那么可以直接等候一定的时间,让机器时间追上来
2. 如果**时间回拨时间较长**,我们不能接收这么长的阻塞等候,那么就有两个策略,直接拒绝,抛出异常;或者通过RD时钟回滚
布式环境下,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况.
如何解决单机系统中时钟回拨问题:
可以分为两种情况:
1. 如果**时间回拨时间较短,比如配置5ms以内**,那么可以直接等候一定的时间,让机器时间追上来
2. 如果**时间回拨时间较长**,我们不能接收这么长的阻塞等候,那么就有两个策略,直接拒绝,抛出异常;或者通过RD时钟回滚
参考博客高并发情况下,雪花ID一秒400W个,以及分布式ID算法(详析)
到此这篇关于Go实现分布式唯一ID的生成之雪花算法的文章就介绍到这了,更多相关Go分布式唯一ID 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

SpringBoot 使用Mongo的GridFs实现分布式文件存储操作
目录 前言 GridFs介绍 什么时候使用GridFs GridFs的原理 环境 引入依赖和项目配置 使用GridFsTemplate操作GridFs 前言 这段时间在公司实习,安排给我一个任务,让在系统里实现一个知识库的模块,产品说,就像百度网盘那样...我tm-,这不就是应了那句话,"这个需求很简单,怎么实现我不管". 可是我google小能手怎么会认输呢,本来还说研究一下FastDFS啥的,但是因为我们项目用的Mongo作为数据库,了解到Mongo自带分布式文件系统GridFs,
-
详解如何使用MongoDB+Springboot实现分布式ID的方法
一.背景 如何实现分布式id,搜索相关的资料,一般会给出这几种方案: 使用数据库自增Id 使用reids的incr命令 使用UUID Twitter的snowflake算法 利用zookeeper生成唯一ID MongoDB的ObjectId 另外,在我通过爬取知乎用户id发现,知乎的用户id是32位的,初步断定知乎采用的是md5加密,然后全部转换成小写.至于如何爬取知乎用户信息,见我之前分享的文章.本文采取的技术方案采取的是mogoodb的objectId. 二.mongodb如何实现分布式I
-
Go实现分布式唯一ID的生成之雪花算法
目录 背景: 特性: 雪花算法: 分布式唯一ID的生成 背景: 在分布式架构下,唯一序列号生成是我们在设计一个尤其是数据库使用分库分表的时候会常见的一个问题 特性: 全局唯一,这是基本要求,不能出现重复数字类型,趋势递增,后面的ID必须比前面的大长度短,能够提高查询效率,这也是从MySQL数据库规范出发的,尤其是ID作为主键时**信息安全,**如果ID连续生成,势必会泄露业务信息,所以需要无规则不规则高可用低延时,ID生成快,能够扛住高并发,延时足够低不至于成为业务瓶颈. 雪花算法: sno
-
PHP实现Snowflake生成分布式唯一ID的方法示例
前言 Twitter 的 snowflake 在分布式生成唯一 UUID 应用还是蛮广泛的,基于 snowflake 的一些变种的算法网上也有不少.使用 snowflake 生成 UUID 很多都是在分布式场景下使用,我看了下网上有其中有几篇 PHP 实现的都没有考虑到线程安全.现在 PHP 有了 Swoole 的锁和协程的加持,对于我们开发线程安全和高并发模拟还是很方便的,这里用 PHP 结合 Swoole 来学习下实现最简单的 snowflake. 先来看以下 snowflake 的结构:
-
Go开源项目分布式唯一ID生成系统
目录 前言 项目背景 项目使用 HTTP 方式 gRPC 方式 本地开发 项目架构 前言 今天跟大家介绍一个开源项目:id-maker,主要功能是用来在分布式环境下生成唯一 ID.上周停更了一周,也是用来开发和测试这个项目的相关代码. 美团有一个开源项目叫 Leaf,使用 Java 开发.本项目就是在此思路的基础上,使用 Go 开发实现的. 项目整体代码量并不多,不管是想要在实际生产环境中使用,还是想找个项目练手,我觉得都是一个不错的选择. 项目背景 在大部分系统中,全局唯一 ID 都是一个强需
-
Java几种分布式全局唯一ID生成方案
目录 缘起 常见方案 UUID 数据库自增键 TDDL Sequence Leaf-segment 类雪花算法 时间回拨问题 Leaf-snowflake Seata UUID 总结 缘起 在分布式微服务系统架构下,有非常多的情况我们需要生成一个全局唯一的 ID 来做标识,比如: 需要分库分表的情况下,分库或分表会导致表本事的自增键不具备唯一性. 较长的业务链路涉及到多个微服务之间的调用,需要一个唯一 ID 来标识比如订单 ID.消息 ID.优惠券 ID.分布式事务全局事务 ID. 对于全局唯一
-
一种简单的ID生成策略: Mysql表生成全局唯一ID的实现
生成全局ID的方法很多, 这里记录下一种简单的方案: 利用mysql的自增id生成全局唯一ID. 1. 创建一张只需要两个字段的表: CREATE TABLE `guid` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `stub` char(1) NOT NULL DEFAULT '' COMMENT '桩字段,占坑的', PRIMARY KEY (`id`), UNIQUE KEY `uk_stub` (`stub`) -- 将 st
-
详解如何利用Redis实现生成唯一ID
目录 一.摘要 二.方案实践 2.1.引入 redis 组件 2.2.添加 redis 环境配置 2.3.编写服务验证逻辑,通过 aop 代理方式实现 2.4.在相关的业务接口上,增加SubmitLimit注解即可 三.小结 一.摘要 在上一篇文章中,我们详细的介绍了随着下单流量逐渐上升,为了降低数据库的访问压力,通过请求唯一ID+redis分布式锁来防止接口重复提交,流程图如下! 每次提交的时候,需要先调用后端服务获取请求唯一ID,然后才能提交. 对于这样的流程,不少的同学可能会感觉到非常鸡肋
-
基于Java代码实现游戏服务器生成全局唯一ID的方法汇总
在服务器系统开发时,为了适应数据大并发的请求,我们往往需要对数据进行异步存储,特别是在做分布式系统时,这个时候就不能等待插入数据库返回了取自动id了,而是需要在插入数据库之前生成一个全局的唯一id,使用全局的唯一id,在游戏服务器中,全局唯一的id可以用于将来合服方便,不会出现键冲突.也可以将来在业务增长的情况下,实现分库分表,比如某一个用户的物品要放在同一个分片内,而这个分片段可能是根据用户id的范围值来确定的,比如用户id大于1000小于100000的用户在一个分片内.目前常用的有以下几种:
-
Java 基于雪花算法生成分布式id
SnowFlake算法原理介绍 在分布式系统中会将一个业务的系统部署到多台服务器上,用户随机访问其中一台,而之所以引入分布式系统就是为了让整个系统能够承载更大的访问量.诸如订单号这些我们需要它是全局唯一的,同时我们基本上都会将它作为查询条件:出于系统安全考虑不应当让其它人轻易的就猜出我们的订单号,同时也要防止公司的竞争对手直接通过订单号猜测出公司业务体量:为了保证系统的快速响应那么生成算法不能太耗时.而雪花算法正好解决了这些问题. SnowFlake 算法(雪花算法), 是Twitter开源的分
-
Redis生成分布式系统全局唯一ID的实现
目录 分布式系统全局唯一ID 基于Redis INCR 命令生成分布式全局唯一ID 采用Redis生成商品全局唯一ID 分布式系统全局唯一ID 在互联网系统中,并发越大的系统,数据就越大,数据越大就越需要分布式,而大量的分布式数据就越需要唯一标识来识别它们. 例如淘宝的商品系统有千亿级别商品,订单系统有万亿级别的订单数据,这些数据都是日渐增长,传统的单库单表是无法支撑这种级别的数据,必须对其进行分库分表:一旦分库分表,表的自增ID就失去了意义:故需要一个全局唯一的ID来标识每一条数据(商品.订单
-
PHP利用雪花(SnowFlake)算法生成唯一ID
目录 一.雪花算法原理解析 1. 分布式ID常见生成策略 2. 雪花算法的结构 二.PHP源码实现案例 1.demo1 2.demo2 这个算法的好处很简单可以在每秒产生约400W个不同的16位数字ID(10进制) 一.雪花算法原理解析 1. 分布式ID常见生成策略 分布式ID生成策略常见的有如下几种: 数据库自增ID. UUID生成. Redis的原子自增方式. 数据库水平拆分,设置初始值和相同的自增步长. 批量申请自增ID. 雪花算法. 百度UidGenerator算法(基于雪花算法实现自定