FedAvg联邦学习FedProx异质网络优化实验总结
目录
- 前言
- I. FedAvg
- II. FedProx
- III. 实验
- IV. 总结
前言

题目: Federated Optimization for Heterogeneous Networks
会议: Conference on Machine Learning and Systems 2020
论文地址:Federated Optimization for Heterogeneous Networks
FedAvg对设备异质性和数据异质性没有太好的解决办法,FedProx在FedAvg的基础上做出了一些改进来尝试缓解这两个问题。
在Online Learning中,为了防止模型根据新到来的数据进行更新后偏离原来的模型太远,也就是为了防止过调节,通常会加入一个余项来限制更新前后模型参数的差异。FedProx中同样引入了一个余项,作用类似。
I. FedAvg
Google的团队首次提出了联邦学习,并引入了联邦学习的基本算法FedAvg。问题的一般形式:


FedAvg:

简单来说,在FedAvg的框架下:每一轮通信中,服务器分发全局参数到各个客户端,各个客户端利用本地数据训练相同的epoch,然后再将梯度上传到服务器进行聚合形成更新后的参数。
FedAvg存在着两个缺陷:
- 设备异质性:不同的设备间的通信和计算能力是有差异的。在FedAvg中,被选中的客户端在本地都训练相同的epoch,虽然作者指出提升epoch可以有效减小通信成本,但较大的epoch下,可能会有很多设备无法按时完成训练。无论是直接drop掉这部分客户端的模型还是直接利用这部分未完成的模型来进行聚合,都将对最终模型的收敛造成不好的影响。
- 数据异质性:不同设备中数据可能是非独立同分布的。如果数据是独立同分布的,那么本地模型训练较多的epoch会加快全局模型的收敛;如果不是独立同分布的,不同设备在利用非IID的本地数据进行训练并且训练轮数较大时,本地模型将会偏离初始的全局模型。
II. FedProx
为了缓解上述两个问题,本文作者提出了一个新的联邦学习框架FedProx。FedProx能够很好地处理异质性。
定义一:
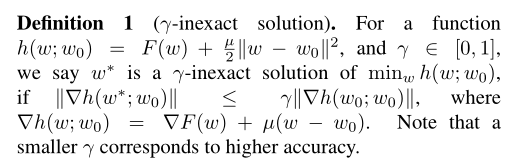

简单来说,每个客户端都是优化所有样本的损失和,这个是正常的思路,让全局模型在本地数据集上表现更好。
但如果设备间的数据是异质的,每个客户端优化之后得到的模型就与初始时服务器分配的全局模型相差过大,本地模型将会偏离初始的全局模型,这将减缓全局模型的收敛。
为了有效限制这种偏差,本文作者提出,设备 k k k在本地进行训练时,需要最小化以下目标函数:

作者在FedAvg损失函数的基础上,引入了一个proximal term,我们可以称之为近端项。引入近端项后,客户端在本地训练后得到的模型参数 w将不会与初始时的服务器参数 wt偏离太多。
观察上式可以发现,当 μ=0时,FedProx客户端的优化目标就与FedAvg一致。
这个思路其实还是很常见的,在机器学习中,为了防止过调节,亦或者为了限制参数变化,通常都会在原有损失函数的基础上加上这样一个类似的项。比如在在线学习中,我们就可以添加此项来限制更新前后模型参数的差异。
FedProx的算法伪代码:


通过观察这个步骤可以发现,FedProx在FedAvg上做了两点改进:
引入了近端项,限制了因为数据异质性导致的模型偏离。引入了不精确解,各个客户端不再需要训练相同的轮数,只需要得到一个不精确解,这有效缓解了某些设备的计算压力。
III. 实验
图1给出了数据异质性对模型收敛的影响:

上图给出了损失随着通信轮数增加的变化情况,数据的异质性从左到右依次增加,其中 μ = 0 表示FedAvg。可以发现,数据间异质性越强,收敛越慢,但如果我们让 μ>0,将有效缓解这一情况,也就是模型将更快收敛。
图2:

左图:E增加后对μ=0情况的影响。可以发现,太多的本地训练将导致本地模型偏离全局模型,全局模型收敛变缓。
中图:同一数据集,增加μ后,收敛将加快,因为这有效缓解了模型的偏移,从而使FedProx的性能较少依赖于 E。
作者给出了一个trick:在实践中,μ可以根据模型当前的性能自适应地选择。比较简单的做法是当损失增加时增加 μ,当损失减少时减少μ。
但是对于 γ,作者貌似没有具体说明怎么选择,只能去GitHub上研究一下源码再给出解释了。
IV. 总结
数据和设备的异质性对传统的FedAvg算法提出了挑战,本文作者在FedAvg的基础上提出了FedProx,FedProx相比于FedAvg主要有以下两点不同:
考虑了不同设备通信和计算能力的差异,并引入了不精确解,不同设备不需要训练相同的轮数,只需要得到一个不精确解即可。引入了近端项,在数据异质的情况下,限制了本地训练时模型对全局模型的偏离。
以上就是FedProx异质网络的联邦优化经验总结的详细内容,更多关于FedProx异质网络联邦优化的资料请关注我们其它相关文章!
相关推荐
-

Python强化练习之PyTorch opp算法实现月球登陆器
目录 概述 强化学习算法种类 PPO 算法 Actor-Critic 算法 Gym LunarLander-v2 启动登陆器 PPO 算法实现月球登录器 PPO main 输出结果 概述 从今天开始我们会开启一个新的篇章, 带领大家来一起学习 (卷进) 强化学习 (Reinforcement Learning). 强化学习基于环境, 分析数据采取行动, 从而最大化未来收益. 强化学习算法种类 On-policy vs Off-policy: On-policy: 训练数据由当前 agent 不断
-
PyTorch实现联邦学习的基本算法FedAvg
目录 I. 前言 II. 数据介绍 特征构造 III. 联邦学习 1. 整体框架 2. 服务器端 3. 客户端 IV. 代码实现 1. 初始化 2. 服务器端 3. 客户端 4. 测试 V. 实验及结果 VI. 源码及数据 I. 前言 在之前的一篇博客联邦学习基本算法FedAvg的代码实现中利用numpy手搭神经网络实现了FedAvg,手搭的神经网络效果已经很好了,不过这还是属于自己造轮子,建议优先使用PyTorch来实现. II. 数据介绍 联邦学习中存在多个客户端,每个客户端都有自己的数据集
-
pytorch 膨胀算法实现大眼效果
目录 算法思路: 应用场景: 代码实现: 实验效果: 论文:Interactive Image Warping(1993年Andreas Gustafsson) 算法思路: 以眼睛中心为中心点,对眼睛区域向外放大,就实现了大眼的效果.大眼的基本公式如下, 假设眼睛中心点为O(x,y),大眼区域半径为Radius,当前点位为A(x1,y1),对其进行改进,加入大眼程度控制变量Intensity,其中Intensity的取值范围为0-100. 其中,dis表示AO的欧式距离,k表示缩放比例因子,
-
pytorch 液态算法实现瘦脸效果
论文:Interactive Image Warping(1993年Andreas Gustafsson) 算法思路: 假设当前点为(x,y),手动指定变形区域的中心点为C(cx,cy),变形区域半径为r,手动调整变形终点(从中心点到某个位置M)为M(mx,my),变形程度为strength,当前点对应变形后的目标位置为U.变形规律如下, 圆内所有像素均沿着变形向量的方向发生偏移 距离圆心越近,变形程度越大 距离圆周越近,变形程度越小,当像素点位于圆周时,该像素不变形 圆外像素不发生偏移 其中,
-
PyTorch实现FedProx联邦学习算法
目录 I. 前言 III. FedProx 1. 模型定义 2. 服务器端 3. 客户端更新 IV. 完整代码 I. 前言 FedProx的原理请见:FedAvg联邦学习FedProx异质网络优化实验总结 联邦学习中存在多个客户端,每个客户端都有自己的数据集,这个数据集他们是不愿意共享的. 数据集为某城市十个地区的风电功率,我们假设这10个地区的电力部门不愿意共享自己的数据,但是他们又想得到一个由所有数据统一训练得到的全局模型. III. FedProx 算法伪代码: 1. 模型定义 客户端的模
-
FedAvg联邦学习FedProx异质网络优化实验总结
目录 前言 I. FedAvg II. FedProx III. 实验 IV. 总结 前言 题目: Federated Optimization for Heterogeneous Networks 会议: Conference on Machine Learning and Systems 2020 论文地址:Federated Optimization for Heterogeneous Networks FedAvg对设备异质性和数据异质性没有太好的解决办法,FedProx在FedAvg的
-
联邦学习神经网络FedAvg算法实现
目录 I. 前言 II. 数据介绍 1. 特征构造 III. 联邦学习 1. 整体框架 2. 服务器端 3. 客户端 4. 代码实现 4.1 初始化 4.2 服务器端 4.3 客户端 4.4 测试 IV. 实验及结果 V. 源码及数据 I. 前言 联邦学习(Federated Learning) 是人工智能的一个新的分支,这项技术是谷歌2016年于论文 Communication-Efficient Learning of Deep Networks from Decentralized Dat
-
联邦学习FedAvg中模型聚合过程的理解分析
目录 问题 聚合 1. 聚合所有客户端 2. 仅聚合被选中的客户端 3. 选择 问题 联邦学习原始论文中给出的FedAvg的算法框架为: 参数介绍: K 表示客户端的个数, B表示每一次本地更新时的数据量, E 表示本地更新的次数, η表示学习率. 首先是服务器执行以下步骤: 对每一个本地客户端来说,要做的就是更新本地参数,具体来讲: 把自己的数据集按照参数B分成若干个块,每一块大小都为B. 对每一块数据,需要进行E轮更新:算出该块数据损失的梯度,然后进行梯度下降更新,得到新的本地 w . 更新
-
联邦学习论文解读分散数据的深层网络通信
目录 前言 Abstract Introduction Federated Learning Privacy Federated Optimization The FederatedAveraging Algorithm Experimental Results Increasing parallelism Increasing computation per client Can we over-optimize on the client datasets? Conclusions and
-
知识蒸馏联邦学习的个性化技术综述
目录 前言 摘要 I. 引言 II. 个性化需求 III. 方法 A. 添加用户上下文 B. 迁移学习 C. 多任务学习 D. 元学习 E. 知识蒸馏 F. 基础+个性化层 G. 全局模型和本地模型混合 IV. 总结 前言 题目: Survey of Personalization Techniques for FederatedLearning 会议: 2020 Fourth World Conference on Smart Trends in Systems, Security and S
-
深度学习环境搭建anaconda+pycharm+pytorch的方法步骤
目录 显卡 驱动 cuda anaconda 1. 下载安装 2. 安装pytorch虚拟环境 3. conda常用指令 pycahrm / jupyter 下载安装 如何建好的虚拟环境的解释器找出来指派给代码? 本文将详细介绍一下如何搭建深度学习所需要的实验环境. 这个框架分为以下六个模块 显卡 简单理解这个就是我们常说的GPU,显卡的功能是一个专门做矩阵运算的部件,用于显示方面的运算,现在神经网络中绝大操作都是对矩阵的运算,所以我们当然可以将显卡的矩阵运算功能应用起来,来提高计算速度. 驱动
-
教你利用python如何读取txt中的数据
目录 前言 方法一:运用open()函数 方法二:使用numpy包的loadtxt方法 方法三:使用pandas的read_table方法进行读取 总结 前言 当我们在用python时可能会遇到想要把txt文档里的数据读取出来然后进行绘图,那么我们要怎么才能够将txt里的数据读取出来呢? 假设有txt文本如下: 想要把上述文本数据读取出来,可以用以下方法: 方法一:运用open()函数 该方法使用最基本的open函数进行读取,此处将会把数据读取到一个列表中,这个方法一般就是open打开文件.re
-
Matplotlib直方图绘制中的参数bins和rwidth的实现
目录 情景引入 bins 参数 stacked参数 rwidth 参数 引用 情景引入 我们在做机器学习相关项目时,常常会分析数据集的样本分布,而这就需要用到直方图的绘制. 在Python中可以很容易地调用matplotlib.pyplot的hist函数来绘制直方图.不过,该函数参数不少,有几个绘图的小细节也需要注意. 首先,我们假定现在有个联邦学习的项目情景.我们有一个样本个数为15的图片数据集,样本标签有4个,分别为cat, dog, car, ship.这个数据集已经被不均衡地划分到4个任