Python通过四大 AutoEDA 工具包快速产出完美数据报告
AutoEDA工具包对于刚刚学习数据分析的小伙伴可以带来非常大的帮助。
本篇文章我们介绍目前最流行的四大AutoEDA工具包。
- D-tale
- Pandas-Profiling
- Sweetviz
- AutoViz
这几个工具包可以以短短三五行代码帮新手节省将近一天时间去写代码分析,非常建议大家收藏学习,喜欢点赞支持,文末提供技术交流群,尽情畅聊。
介绍
01 D-Tale
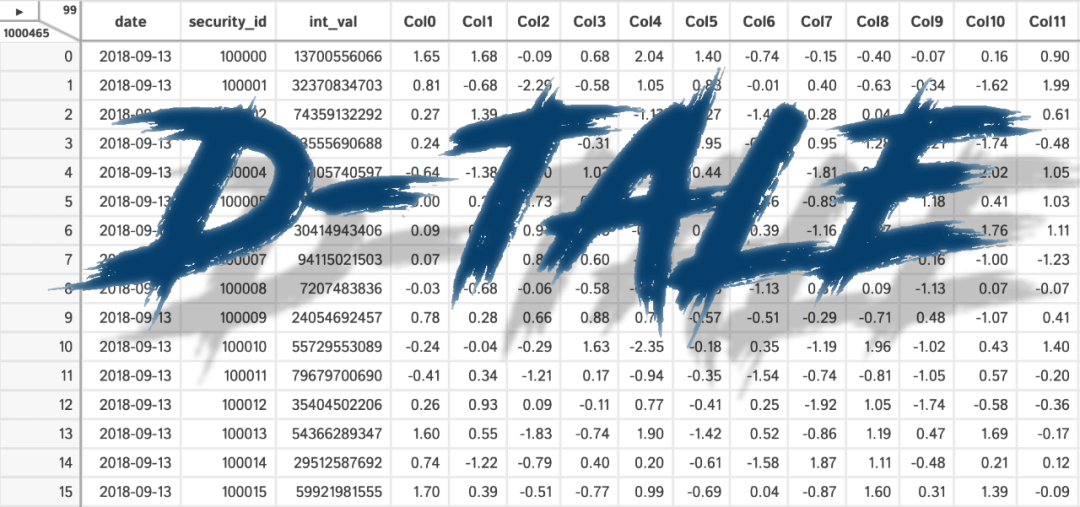
D-Tale是Flask后端和React前端组合的产物,也是一个开源的Python自动可视化库,可以为我们提供查看和分析Pandas DataFrame的方法,帮助我们获得非常数据的详细EDA。
目前D-Tale支持DataFrame、Series、MultiIndex、DatetimeIndex 和 RangeIndex 等 Pandas 对象。
Github 链接
https://github.com/man-group/dtale
# pip install dtale
import dtale
import pandas as pd
df = pd.read_csv('./data/titanic.csv')
d = dtale.show(df)
d.open_browser()
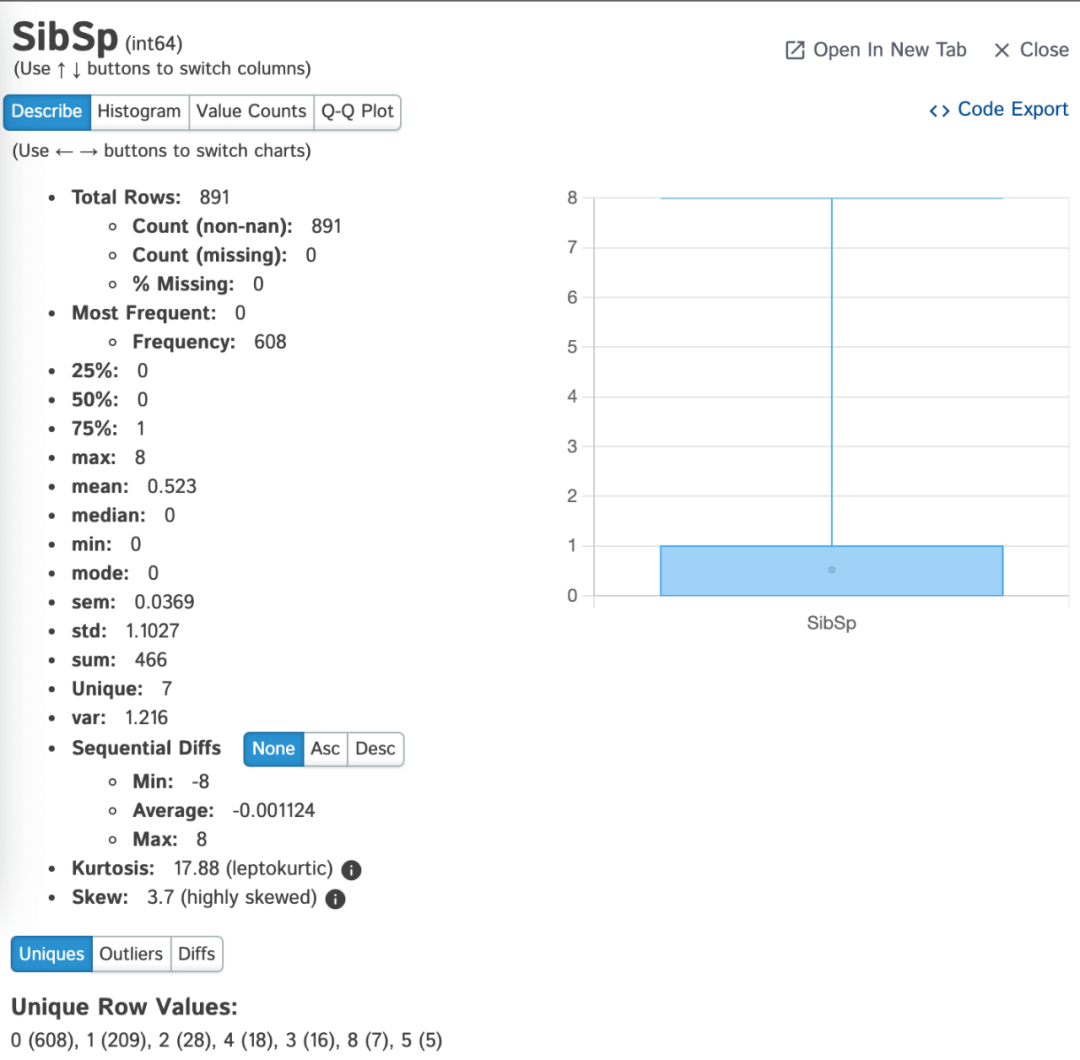
02 Pandas-Profiling

Pandas-Profiling可以对Pandas DataFrame生成report报告。其中:
- pandas_profiling的df.profile_report()扩展了pandas DataFrame以方便进行快速数据分析。
Pandas-Profiling对于每一列特征,特征的统计信息(如果与列类型相关)会显示在交互式 HTML的report中:
- Type:检测数据列类型;
- Essentials:类型、unique值、缺失值
- 分位数统计,如最小值、Q1、中位数、Q3、最大值、范围、四分位距
- 描述性统计数据,如均值、众数、标准差、总和、中值绝对偏差、变异系数、峰态、偏度
- 出现最多的值
- 直方图
- 高度相关变量、Spearman、Pearson 和 Kendall 矩阵的相关性突出显示
- 缺失值矩阵、计数、热图和缺失值树状图
- …
Github 链接
https://github.com/pandas-profiling/pandas-profiling/
from pandas_profiling import ProfileReport profile = ProfileReport(df, title="Pandas Profiling Report") profile
2021-10-30 22:50:43,584 - INFO - Pandas backend loaded 1.2.5
2021-10-30 22:50:43,597 - INFO - Numpy backend loaded 1.19.2
2021-10-30 22:50:43,599 - INFO - Pyspark backend NOT loaded
2021-10-30 22:50:43,600 - INFO - Python backend loaded
一个特征的案例
03 Sweetviz

Sweetviz也是一个开源Python库,Sweetviz可以用简短几行代码生成美观、高密度的可视化文件,只需两行代码即可开启探索性数据分析并输出一个完全独立的 HTML 应用程序。Sweetviz主要包含下面的分析:
- 数据集概述
- 变量属性
- 类别的关联性
- 数值关联性
- 数值特征最频繁值、最小、最大值
Github 链接
https://github.com/fbdesignpro/sweetviz
# pip install sweetviz import sweetviz as sv sweetviz_report = sv.analyze(df) sweetviz_report.show_html()
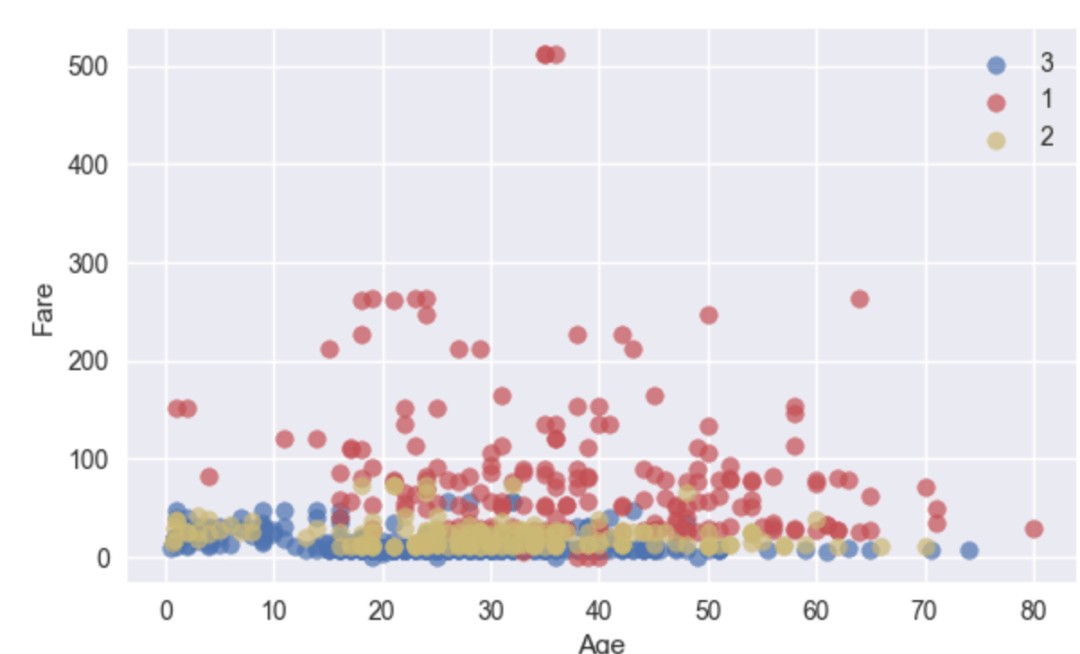
04 AutoViz

AutoViz可以使用一行自动显示任何数据集。给出任何输入文件(CSV、txt或json),AutoViz都可以对其进行可视化。AutoViz的结果会以非常多的图片都形式存在文件夹下方。
Github 链接
https://github.com/AutoViML/AutoViz
# pip install autoviz
from autoviz.AutoViz_Class import AutoViz_Class
AV = AutoViz_Class()
sep = ';'
dft = AV.AutoViz(filename="",sep=sep, depVar='Pclass', dfte=df, header=0, verbose=2,
lowess=False, chart_format='png', max_rows_analyzed=150000, max_cols_analyzed=30)
诸多文件全都在当前文件夹下方

我们打开其中一个效果如下:
适用问题
适用于所有的数据分析问题。
到此这篇关于Python通过四大 AutoEDA 工具包快速产出完美数据报告的文章就介绍到这了,更多相关Python AutoEDA工具包内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python教程pandas数据分析去重复值
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs
-
python数据分析必会的Pandas技巧汇总
目录 一.Pandas两大数据结构的创建 二.DataFrame常见方法 三.数据索引 四.DataFrame选取和重新组合数据的方法 五.排序 六.相关分析和统计分析 七.分组的方法 八.读写文本格式数据的方法 九.处理缺失数据 十.数据转换 一.Pandas两大数据结构的创建 序号 方法 说明 1 pd.Series(对象,index=[ ]) 创建Series.对象可以是列表\ndarray.字典以及DataFrame中的某一行或某一列 2 pd.DataFrame(data,column
-
简单且有用的Python数据分析和机器学习代码
为什么选择Python进行数据分析? Python是一门动态的.面向对象的脚本语言,同时也是一门简约,通俗易懂的编程语言.Python入门简单,代码可读性强,一段好的Python代码,阅读起来像是在读一篇外语文章.Python这种特性称为"伪代码",它可以使你只关心完成什么样的工作任务,而不是纠结于Python的语法. 另外,Python是开源的,它拥有非常多优秀的库,可以用于数据分析及其他领域.更重要的是,Python与最受欢迎的开源大数据平台Hadoop具有很好的兼容性.因此,学习
-
Python数据分析JupyterNotebook3魔法命令详解及示例
目录 1.魔法命令介绍 %lsmagic:列出所有magics命令 %quickref:输出所有魔法指令的简单版帮助文档 %Magics_Name?:输出某个魔法命令详细帮助文档 2.Line magics:Line魔法指令 3.Cell magics:Cell魔法指令 写bash程序 写perl程序 1.魔法命令介绍 %lsmagic:列出所有magics命令 Available line magics:[对当前行使用共计93个] %alias %alias_magic %autoawait
-
python数据分析之DataFrame内存优化
目录 1. pandas查看数据占用大小 2. 对数据进行压缩 3. 参考资料
-
利用python数据分析处理进行炒股实战行情
作为一个新手,你需要以下3个步骤: 1.用户注册 > 2.获取token > 3.调取数据 数据内容: 包含股票.基金.期货.债券.外汇.行业大数据, 同时包括了数字货币行情等区块链数据的全数据品类的金融大数据平台, 为各类金融投资和研究人员提供适用的数据和工具. 1.数据采集 我们进行本地化计算,首先要做的,就是将所需的基础数据采集到本地数据库里 本篇的示例源码采用的数据库是MySQL5.5,数据源是xxx pro接口. 我们现在要取一批特定股票的日线行情 部分代码如下: # 设置xxxxx
-
Python 数据分析之Beautiful Soup 提取页面信息
概述 数据分析 (Data Analyze) 可以在工作中的各个方面帮助我们. 本专栏为量化交易专栏下的子专栏, 主要讲解一些数据分析的基础知识. Beautiful Soup Beautiful 是一个可以从 HTML 或 XML 文件中提取数据的 Pyhton 库. 简单来说, 它能将 HTML 的标签文件解析成树形结构, 然后方便的获取到指定标签的对应属性. 安装: pip install beautifulsoup4 例子: from bs4 import BeautifulSoup #
-
手把手带你了解Python数据分析--matplotlib
目录 柱形图 条形图 折线图 饼图和圆环图 分离饼图块 圆环图 总结 柱形图 bar()函数绘制柱形图 import matplotlib.pyplot as pl x = [1,2,3,4,5,6,7] y = [15,69,85,12,36,95,11] pl.bar(x,y) pl.show() bar()函数的参数width和color设置每根柱子的宽度和颜色 有中文时要添加 pl.rcParams['font.sans-serif'] = ['FangSong'] 有负号时要添加 pl
-
Python通过四大 AutoEDA 工具包快速产出完美数据报告
AutoEDA工具包对于刚刚学习数据分析的小伙伴可以带来非常大的帮助. 本篇文章我们介绍目前最流行的四大AutoEDA工具包. D-tale Pandas-Profiling Sweetviz AutoViz 这几个工具包可以以短短三五行代码帮新手节省将近一天时间去写代码分析,非常建议大家收藏学习,喜欢点赞支持,文末提供技术交流群,尽情畅聊. 介绍 01 D-Tale D-Tale是Flask后端和React前端组合的产物,也是一个开源的Python自动可视化库,可以为我们提供查看和分析Pand
-
Python+ChatGPT实现5分钟快速上手编程
目录 1.chatGPT是个啥 2.chatGPT怎么注册 3.chatGPT怎么用 4.小结 最近一段时间chatGPT火爆出圈!无论是在互联网行业,还是其他各行业都赚足了话题. 俗话说:“外行看笑话,内行看门道”,今天从chatGPT个人体验感受以及如何用的角度来分享一下. 1.chatGPT是个啥 chatGPT是最近新出来的玩意?并不是!在国内,chatGPT最早是在2022年11月就由OpenAI于推出的.只是去年底火了一把,后力不足又遇春节,热度草草就结束了. 先讲一下,OpenAI
-
python跳过第一行快速读取文件内容的实例
Python编程时,经常需要跳过第一行读取文件内容.简单的做法是为每行设置一个line_num,然后判断line_num是否为1,如果不等于1,则进行读取操作. 相应的Python代码如下: input_file = open("C:\\Python34\\test.csv") line_num = 0 for line in input_file: line_num += 1 if (line_num != 1): do_readline() 然而这样每次迭代都需要判断一次,增加了时
-
python使用隐式循环快速求和的实现示例
如何快速的求出1到x的和呢?代码如下: NB(注意): # 后面的部分表示输出结果. class Debug: def calculateSum(self, size): return sum(range(size)) if __name__ == "__main__": main = Debug() result = main.calculateSum(101) print(result) # 5050 这里我们想要求出1-100的和,因为range(101)最后的值是100,所以r
-
在Python中利用Into包整洁地进行数据迁移的教程
动机 我们花费大量的时间将数据从普通的交换格式(比如CSV),迁移到像数组.数据库或者二进制存储等高效的计算格式.更糟糕的是,许多人没有将数据迁移到高效的格式,因为他们不知道怎么(或者不能)为他们的工具管理特定的迁移方法. 你所选择的数据格式很重要,它会强烈地影响程序性能(经验规律表明会有10倍的差距),以及那些轻易使用和理解你数据的人. 当提倡Blaze项目时,我经常说:"Blaze能帮助你查询各种格式的数据."这实际上是假设你能够将数据转换成指定的格式. 进入into项目 into
-
MySQL 快速删除大量数据(千万级别)的几种实践方案详解
笔者最近工作中遇见一个性能瓶颈问题,MySQL表,每天大概新增776万条记录,存储周期为7天,超过7天的数据需要在新增记录前老化.连续运行9天以后,删除一天的数据大概需要3个半小时(环境:128G, 32核,4T硬盘),而这是不能接受的.当然如果要整个表删除,毋庸置疑用 TRUNCATE TABLE就好. 最初的方案(因为未预料到删除会如此慢),代码如下(最简单和朴素的方法): delete from table_name where cnt_date <= target_date 后经过研究,
-
python爬虫之Appium爬取手机App数据及模拟用户手势
目录 Appium 模拟操作 屏幕滑动 屏幕点击 屏幕拖动 屏幕拖拽 文本输入 动作链 实战:爬取微博首页信息 Appium 在前文的讲解中,我们学会了如何安装Appium,以及一些基础获取App元素内容的方式.但认真看过前文的读者,肯定在博主获取元素的时候观察到了一个现象. 那就是手机App的内容并不是一次性加载出来的,比如大多数Android手机列表ListView,都是异步加载,也就是你滑动到那个位置,它才会显示出它的内容. 也就是说,我们前面爬取微博首页全部信息的时候,如果你不滑动先加载
-
Python实现自动化处理每月考勤缺卡数据
目录 一.效果展示 1.实现效果 2.原始数据模板 二.代码详解 1.导入库 2.定义时间处理函数 3.读取数据调整日期格式 4.计算工作日天数 5.获取缺卡名单 不管是上学还是上班都会统计考勤,有些学校或公司会对每月缺卡次数过多(比如三次以上)的人员进行处罚. 有些公司还规定对于基层员工要在工作日提交日志.管理人员要提交周报或月报,对于少提交的人员要进行处罚. 如果公司HR逐个对人员的日志或缺卡数据进行处理,将是一项耗时且无聊的工作. 本文提供了自动处理考勤和日志缺失的方法. 不用安装Pyth
-
python使用clear方法清除字典内全部数据实例
本文实例讲述了python使用clear方法清除字典内全部数据.分享给大家供大家参考.具体实现方法如下: d = {} d['name'] = 'Gumby' d['age'] = 42 print d returned_value = d.clear() print d print returned_value 希望本文所述对大家的Python程序设计有所帮助.
-
Python实现读写sqlite3数据库并将统计数据写入Excel的方法示例
本文实例讲述了Python实现读写sqlite3数据库并将统计数据写入Excel的方法.分享给大家供大家参考,具体如下: src = 'F:\\log\\mha-041log\\rnd-log-dl.huawei.com\\test' # dst = sys.argv[2] dst = 'F:\\log\\mha-041log\\rnd-log-dl.huawei.com\\test\\mha-041log.db' # dst_anylyzed = sys.argv[3] dst_anylyze