Python+redis通过限流保护高并发系统
保护高并发系统的三大利器:缓存、降级和限流。那什么是限流呢?用我没读过太多书的话来讲,限流就是限制流量。我们都知道服务器的处理能力是有上限的,如果超过了上限继续放任请求进来的话,可能会发生不可控的后果。而通过限流,在请求数量超出阈值的时候就排队等待甚至拒绝服务,就可以使系统在扛不住过高并发的情况下做到有损服务而不是不服务。
举个例子,如各地都出现口罩紧缺的情况,广州政府为了缓解市民买不到口罩的状况,上线了预约服务,只有预约到的市民才能到指定的药店购买少量口罩。这就是生活中限流的情况,说这个也是希望大家这段时间保护好自己,注意防护 :)
接下来就跟大家分享下接口限流的常见玩法吧,部分算法用python+redis粗略实现了一下,关键是图解啊!你品,你细品~
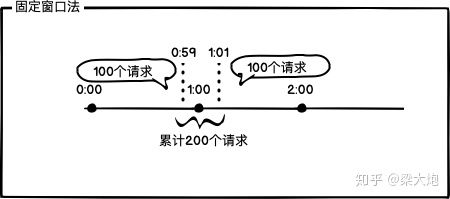
固定窗口法
固定窗口法是限流算法里面最简单的,比如我想限制1分钟以内请求为100个,从现在算起的一分钟内,请求就最多就是100个,这分钟过完的那一刻把计数器归零,重新计算,周而复始。
伪代码实现
def can_pass_fixed_window(user, action, time_zone=60, times=30):
"""
:param user: 用户唯一标识
:param action: 用户访问的接口标识(即用户在客户端进行的动作)
:param time_zone: 接口限制的时间段
:param time_zone: 限制的时间段内允许多少请求通过
"""
key = '{}:{}'.format(user, action)
# redis_conn 表示redis连接对象
count = redis_conn.get(key)
if not count:
count = 1
redis_conn.setex(key, time_zone, count)
if count < times:
redis_conn.incr(key)
return True
return False
这个方法虽然简单,但有个大问题是无法应对两个时间边界内的突发流量。如上图所示,如果在计数器清零的前1秒以及清零的后1秒都进来了100个请求,那么在短时间内服务器就接收到了两倍的(200个)请求,这样就有可能压垮系统。会导致上面的问题是因为我们的统计精度还不够,为了将临界问题的影响降低,我们可以使用滑动窗口法。
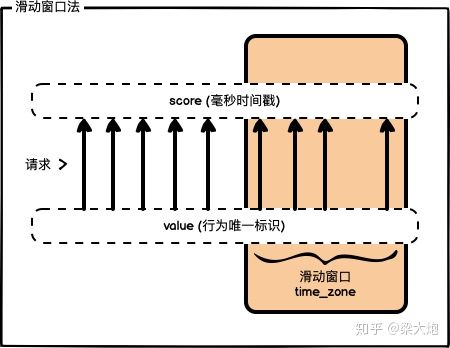
滑动窗口法
滑动窗口法,简单来说就是随着时间的推移,时间窗口也会持续移动,有一个计数器不断维护着窗口内的请求数量,这样就可以保证任意时间段内,都不会超过最大允许的请求数。例如当前时间窗口是0s~60s,请求数是40,10s后时间窗口就变成了10s~70s,请求数是60。
时间窗口的滑动和计数器可以使用redis的有序集合(sorted set)来实现。score的值用毫秒时间戳来表示,可以利用当前时间戳-时间窗口的大小来计算出窗口的边界,然后根据score的值做一个范围筛选就可以圈出一个窗口;value的值仅作为用户行为的唯一标识,也用毫秒时间戳就好。最后统计一下窗口内的请求数再做判断即可。
伪代码实现
def can_pass_slide_window(user, action, time_zone=60, times=30):
"""
:param user: 用户唯一标识
:param action: 用户访问的接口标识(即用户在客户端进行的动作)
:param time_zone: 接口限制的时间段
:param time_zone: 限制的时间段内允许多少请求通过
"""
key = '{}:{}'.format(user, action)
now_ts = time.time() * 1000
# value是什么在这里并不重要,只要保证value的唯一性即可,这里使用毫秒时间戳作为唯一值
value = now_ts
# 时间窗口左边界
old_ts = now_ts - (time_zone * 1000)
# 记录行为
redis_conn.zadd(key, value, now_ts)
# 删除时间窗口之前的数据
redis_conn.zremrangebyscore(key, 0, old_ts)
# 获取窗口内的行为数量
count = redis_conn.zcard(key)
# 设置一个过期时间免得占空间
redis_conn.expire(key, time_zone + 1)
if not count or count < times:
return True
return False
虽然滑动窗口法避免了时间界限的问题,但是依然无法很好解决细时间粒度上面请求过于集中的问题,就例如限制了1分钟请求不能超过60次,请求都集中在59s时发送过来,这样滑动窗口的效果就大打折扣。 为了使流量更加平滑,我们可以使用更加高级的令牌桶算法和漏桶算法。
令牌桶法
令牌桶算法的思路不复杂,它先以固定的速率生成令牌,把令牌放到固定容量的桶里,超过桶容量的令牌则丢弃,每来一个请求则获取一次令牌,规定只有获得令牌的请求才能放行,没有获得令牌的请求则丢弃。

伪代码实现
def can_pass_token_bucket(user, action, time_zone=60, times=30):
"""
:param user: 用户唯一标识
:param action: 用户访问的接口标识(即用户在客户端进行的动作)
:param time_zone: 接口限制的时间段
:param time_zone: 限制的时间段内允许多少请求通过
"""
# 请求来了就倒水,倒水速率有限制
key = '{}:{}'.format(user, action)
rate = times / time_zone # 令牌生成速度
capacity = times # 桶容量
tokens = redis_conn.hget(key, 'tokens') # 看桶中有多少令牌
last_time = redis_conn.hget(key, 'last_time') # 上次令牌生成时间
now = time.time()
tokens = int(tokens) if tokens else capacity
last_time = int(last_time) if last_time else now
delta_tokens = (now - last_time) * rate # 经过一段时间后生成的令牌
if delta_tokens > 1:
tokens = tokens + tokens # 增加令牌
if tokens > tokens:
tokens = capacity
last_time = time.time() # 记录令牌生成时间
redis_conn.hset(key, 'last_time', last_time)
if tokens >= 1:
tokens -= 1 # 请求进来了,令牌就减少1
redis_conn.hset(key, 'tokens', tokens)
return True
return False
令牌桶法限制的是请求的平均流入速率,优点是能应对一定程度上的突发请求,也能在一定程度上保持流量的来源特征,实现难度不高,适用于大多数应用场景。
漏桶算法
漏桶算法的思路与令牌桶算法有点相反。大家可以将请求想象成是水流,水流可以任意速率流入漏桶中,同时漏桶以固定的速率将水流出。如果流入速度太大会导致水满溢出,溢出的请求被丢弃。
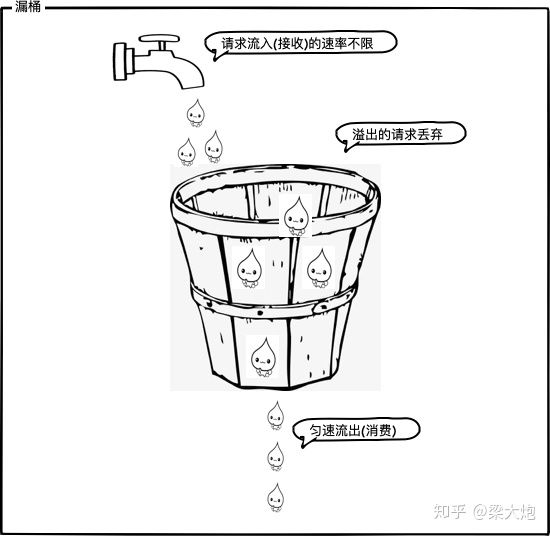
通过上图可以看出漏桶法的特点是:不限制请求流入的速率,但是限制了请求流出的速率。这样突发流量可以被整形成一个稳定的流量,不会发生超频。
关于漏桶算法的实现方式有一点值得注意,我在浏览相关内容时发现网上大多数对于漏桶算法的伪代码实现,都只是实现了
根据维基百科,漏桶算法的实现理论有两种,分别是基于 meter 的和基于 queue 的,他们实现的具体思路不同,我大概介绍一下。
基于meter的漏桶
基于 meter 的实现相对来说比较简单,其实它就有一个计数器,然后有消息要发送的时候,就看计数器够不够,如果计数器没有满的话,那么这个消息就可以被处理,如果计数器不足以发送消息的话,那么这个消息将会被丢弃。
那么这个计数器是怎么来的呢,基于 meter 的形式的计数器就是发送的频率,例如你设置得频率是不超过 5条/s ,那么计数器就是 5,在一秒内你每发送一条消息就减少一个,当你发第 6 条的时候计时器就不够了,那么这条消息就被丢弃了。
这种实现有点类似最开始介绍的固定窗口法,只不过时间粒度再小一些,伪代码就不上了。
基于queue的漏桶
基于 queue 的实现起来比较复杂,但是原理却比较简单,它也存在一个计数器,这个计数器却不表示速率限制,而是表示 queue 的大小,这里就是当有消息要发送的时候看 queue 中是否还有位置,如果有,那么就将消息放进 queue 中,这个 queue 以 FIFO 的形式提供服务;如果 queue 没有位置了,消息将被抛弃。
在消息被放进 queue 之后,还需要维护一个定时器,这个定时器的周期就是我们设置的频率周期,例如我们设置得频率是 5条/s,那么定时器的周期就是 200ms,定时器每 200ms 去 queue 里获取一次消息,如果有消息,那么就发送出去,如果没有就轮空。
注意,网上很多关于漏桶法的伪代码实现只实现了水流入桶的部分,没有实现关键的水从桶中漏出的部分。如果只实现了前半部分,其实跟令牌桶没有大的区别噢😯
如果觉得上面的都太难,不好实现,那么我墙裂建议你尝试一下redis-cell这个模块!
redis-cell
Redis 4.0 提供了一个限流 Redis 模块,它叫 redis-cell。该模块也使用了漏斗算法,并提供了原子的限流指令。有了这个模块,限流问题就非常简单了。 这个模块需要单独安装,安装教程网上很多,它只有一个指令:
CL.THROTTLE
CL.THROTTLE user123 15 30 60 1
▲ ▲ ▲ ▲ ▲
| | | | └───── apply 1 operation (default if omitted) 每次请求消耗的水滴
| | └──┴─────── 30 operations / 60 seconds 漏水的速率
| └───────────── 15 max_burst 漏桶的容量
└─────────────────── key “user123” 用户行为
执行以上命令之后,redis会返回如下信息:
> cl.throttle laoqian:reply 15 30 60
1) (integer) 0 # 0 表示允许,1表示拒绝
2) (integer) 16 # 漏桶容量
3) (integer) 15 # 漏桶剩余空间left_quota
4) (integer) -1 # 如果拒绝了,需要多长时间后再试(漏桶有空间了,单位秒)
5) (integer) 2 # 多长时间后,漏桶完全空出来(单位秒)
有了上面的redis模块,就可以轻松对付大多数的限流场景了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python 通过SSHTunnelForwarder隧道连接redis的方法
背景:我司Redis服务器使用的亚马逊服务,本地需要通过跳板机,然后才有权限访问Redis服务. 连接原理:使用SSHTunnelForwarder模块,通过本地22端口ssh到跳板机,然后本地开启一个转发端口给跳板机远程Redis服务使用. 两种思路: 1.通过SSHTunnelForwarder,paramiko模块,先ssh到跳板机,然后在跳板机上(或者内部服务器上),获取到权限,然后远程Redis. 2.使用SSHTunnelForwarder模块,通过本地22端口ssh到跳板机,然后本
-
Python操作redis实例小结【String、Hash、List、Set等】
本文实例总结了Python操作redis方法.分享给大家供大家参考,具体如下: 这里介绍详细使用 1.String 操作 redis中的String在在内存中按照一个name对应一个value来存储 set() #在Redis中设置值,默认不存在则创建,存在则修改 r.set('name', 'zhangsan') '''参数: set(name, value, ex=None, px=None, nx=False, xx=False) ex,过期时间(秒) px,过期时间(毫秒) nx,如果设
-
python redis 批量设置过期key过程解析
这篇文章主要介绍了python redis 批量设置过期key过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在使用 Redis.Codis 时,我们经常需要做一些批量操作,通过连接数据库批量对 key 进行操作: 关于未过期: 1.常有大批量的key未设置过期,导致内存一直暴增 2.rd需求 扫描出这些key,rd自己处理过期(一般dba不介入数据的修改) 3.dba 批量设置过期时间,(一般测试可以直接批量设置,线上谨慎操作) 通过
-
python如何基于redis实现ip代理池
这篇文章主要介绍了python如何基于redis实现ip代理池,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 使用apscheduler库定时爬取ip,定时检测ip删除ip,做了2层检测,第一层爬取后放入redis--db0进行检测,成功的放入redis--db1再次进行检测,确保获取的代理ip的可用性 import requests, redis import pandas import random from apscheduler.sch
-
python如何使用Redis构建分布式锁
这篇文章主要介绍了python如何使用Redis构建分布式锁,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在实际应用场景中,我们可能有多个worker,可能在一台机器,也可能分布在不同的机器,但只有一个worker可以同时持有一把锁,这个时候我们就需要用到分布式锁了. 这里推荐python的实现库,Redlock-py(Python 实现). 正常情况下,worker获得锁后,处理自己的任务,完成后自动释放持有的锁,是不是感觉有点熟悉,很容易
-
Python获取Redis所有Key以及内容的方法
一.获取所有Key # -*- encoding: UTF-8 -*- __author__ = "Sky" import redis pool=redis.ConnectionPool(host='127.0.0.1',port=6379,db=0) r = redis.StrictRedis(connection_pool=pool) keys = r.keys() print type(keys) print keys 运行结果: <type 'list'> ['fa
-
Python操作redis和mongoDB的方法
一.操作redis redis是一个key-value存储系统,value的类型包括string(字符串),list(链表),set(集合),zset(有序集合),hash(哈希类型).为了保证效率,数据都是缓冲在内存中,在处理大规模数据读写的场景下运用比较多. 备注:默认redis有16个数据库,即db0~db15, 一般存取数据如果不指定库的话,默认都是存在db0中. resid提供2种连接方式:直接连接.连接池连接 1.直接连接示例: import redis # pip3 install
-
Python+Redis实现布隆过滤器
布隆过滤器是什么 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难. 布隆过滤器的基本思想 通过一种叫作散列表(又叫哈希表,Hash table)的数据结构.它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点.这样一来,我们只要看看这个点是不是1就可以知道集合中有没
-
Python+redis通过限流保护高并发系统
保护高并发系统的三大利器:缓存.降级和限流.那什么是限流呢?用我没读过太多书的话来讲,限流就是限制流量.我们都知道服务器的处理能力是有上限的,如果超过了上限继续放任请求进来的话,可能会发生不可控的后果.而通过限流,在请求数量超出阈值的时候就排队等待甚至拒绝服务,就可以使系统在扛不住过高并发的情况下做到有损服务而不是不服务. 举个例子,如各地都出现口罩紧缺的情况,广州政府为了缓解市民买不到口罩的状况,上线了预约服务,只有预约到的市民才能到指定的药店购买少量口罩.这就是生活中限流的情况,说这个也是希
-
高并发系统的限流详解及实现
在开发高并发系统时有三把利器用来保护系统:缓存.降级和限流.本文结合作者的一些经验介绍限流的相关概念.算法和常规的实现方式. 缓存 缓存比较好理解,在大型高并发系统中,如果没有缓存数据库将分分钟被爆,系统也会瞬间瘫痪.使用缓存不单单能够提升系统访问速度.提高并发访问量,也是保护数据库.保护系统的有效方式.大型网站一般主要是"读",缓存的使用很容易被想到.在大型"写"系统中,缓存也常常扮演者非常重要的角色.比如累积一些数据批量写入,内存里面的缓存队列(生产消费),以及
-

Java高并发系统限流算法的实现
目录 1 概述 2 计数器限流 2.1 概述 2.2 实现 2.3 结果分析 2.4 优缺点 2.5 应用 3 漏桶算法 3.1 概述 3.2 实现 3.3 结果分析 3.4 优缺点 4 令牌桶算法 4.1 概述 4.2 实现 4.3 结果分析 4.4 应用 5 滑动窗口 5.1 概述 5.2 实现 5.3 结果分析 5.4 应用 1 概述 在开发高并发系统时有三把利器用来保护系统:缓存.降级和限流.限流可以认为服务降级的一种,限流是对系统的一种保护措施.即限制流量请求的频率(每秒处理多少个请求
-
golang高并发系统限流策略漏桶和令牌桶算法源码剖析
目录 前言 漏桶算法 样例 源码实现 令牌桶算法 样例 源码剖析 Limit类型 Limiter结构体 Reservation结构体 Limiter消费token limiter归还Token 总结 前言 今天与大家聊一聊高并发系统中的限流技术,限流又称为流量控制,是指限制到达系统的并发请求数,当达到限制条件则可以拒绝请求,可以起到保护下游服务,防止服务过载等作用.常用的限流策略有漏桶算法.令牌桶算法.滑动窗口:下文主要与大家一起分析一下漏桶算法和令牌桶算法,滑动窗口就不在这里这介绍了.好啦,废
-
详解Redis实现限流的三种方式
面对越来越多的高并发场景,限流显示的尤为重要. 当然,限流有许多种实现的方式,Redis具有很强大的功能,我用Redis实践了三种的实现方式,可以较为简单的实现其方式.Redis不仅仅是可以做限流,还可以做数据统计,附近的人等功能,这些可能会后续写到. 第一种:基于Redis的setnx的操作 我们在使用Redis的分布式锁的时候,大家都知道是依靠了setnx的指令,在CAS(Compare and swap)的操作的时候,同时给指定的key设置了过期实践(expire),我们在限流的主要目的就
-
Redis常见限流算法原理及实现
目录 前言 简介 固定时间窗口 原理 示例说明 优缺点 相关实现 限流脚本 具体实现 测试 滑动时间窗口 实现原理 示例说明 具体实现 漏桶算法 原理 具体实现 令牌桶算法 原理 具体实现 小结 总结 前言 在高并发系统中,我们通常需要通过各种手段来提供系统的可以用性,例如缓存.降级和限流等,本文将针对应用中常用的限流算法进行详细的讲解. 简介 限流简称流量限速(Rate Limit)是指只允许指定的事件进入系统,超过的部分将被拒绝服务.排队或等待.降级等处理. 常见的限流方案如下: 固定时间窗
-
Redis分布式限流组件设计与使用实例
目录 1.背景 2.Redis计数器限流设计 2.1Lua脚本 2.2自定义注解 2.3限流组件 2.4限流切面实现 3.测试一下 3.1方法限流示例 3.2动态入参限流示例 4.其它扩展 5.源码地址 本文主要讲解基于 自定义注解+Aop+反射+Redis+Lua表达式 实现的限流设计方案.实现的限流设计与实际使用. 1.背景 在互联网开发中经常遇到需要限流的场景一般分为两种 业务场景需要(比如:5分钟内发送验证码不超过xxx次); 对流量大的功能流量削峰; 一般我们衡量系统处理能力的指标是每
-
redis lua限流算法实现示例
目录 限流算法 计数器算法 场景分析 算法实现 漏铜算法 令牌桶算法: 算法实现 限流算法 常见的限流算法 计数器算法 漏桶算法 令牌桶算法 计数器算法 顾名思义,计数器算法是指在一定的时间窗口内允许的固定数量的请求.比如,2s内允许10个请求,30s内允许100个请求等等.如果设置的时间粒度越细,那么相对而言限流就会越平滑,控制的粒度就会更细. 场景分析 试想,如果设置的粒度比较粗会出现什么样的问题呢?如下图设置一个 1000/3s 的限流计数统计. 图中的限流策略为3s内允许的最大请求量
-
高并发系统数据幂等的解决方案
前言 在系统开发过程中,经常遇到数据重复插入.重复更新.消息重发发送等等问题,因为应用系统的复杂逻辑以及网络交互存在的不确定性,会导致这一重复现象,但是有些逻辑是需要有幂等特性的,否则造成的后果会比较严重,例如订单重复创建,这时候带来的问题可是非同一般啊. 什么是系统的幂等性 幂等是数据中得一个概念,表示N次变换和1次变换的结果相同. 高并发的系统如何保证幂等性? 1.查询 查询的API,可以说是天然的幂等性,因为你查询一次和查询两次,对于系统来讲,没有任何数据的变更,所以,查询一次和查询多次一
-
php使用lua+redis实现限流,计数器模式,令牌桶模式
lua 优点 减少网络开销: 不使用 Lua 的代码需要向 Redis 发送多次请求, 而脚本只需一次即可, 减少网络传输; 原子操作: Redis 将整个脚本作为一个原子执行, 无需担心并发, 也就无需事务; 复用: 脚本会永久保存 Redis 中, 其他客户端可继续使用. 计数器模式: 利用lua脚本一次性完成处理达到原子性,通过INCR自增计数,判断是否达到限定值,达到限定值则返回限流,添加key过期时间应该范围过度 $lua = ' local i = redis.call("INCR&