使用Python和scikit-learn创建混淆矩阵的示例详解
目录
- 一、混淆矩阵概述
- 1、示例1
- 2、示例2
- 二、使用Scikit-learn 创建混淆矩阵
- 1、相应软件包
- 2、生成示例数据集
- 3、训练一个SVM
- 4、生成混淆矩阵
- 5、可视化边界
一、混淆矩阵概述
在训练了有监督的机器学习模型(例如分类器)之后,您想知道它的工作情况。
这通常是通过将一小部分称为测试集的数据分开来完成的,该数据用作模型以前从未见过的数据。
如果它在此数据集上表现良好,那么该模型很可能在其他数据上也表现良好 - 当然,如果它是从与您的测试集相同的分布中采样的。
现在,当您测试您的模型时,您向其提供数据 - 并将预测与基本事实进行比较,测量真阳性、真阴性、假阳性和假阴性的数量。这些随后可以在视觉上吸引人的混淆矩阵中可视化。
在今天我们将学习如何使用 Scikit-learn 创建这样的混淆矩阵,Scikit-learn 是当今机器学习社区中使用最广泛的机器学习框架之一。通过使用 Python 创建的示例,展示如何生成一个矩阵,您可以使用该矩阵轻松直观地确定模型的性能。
1、示例1

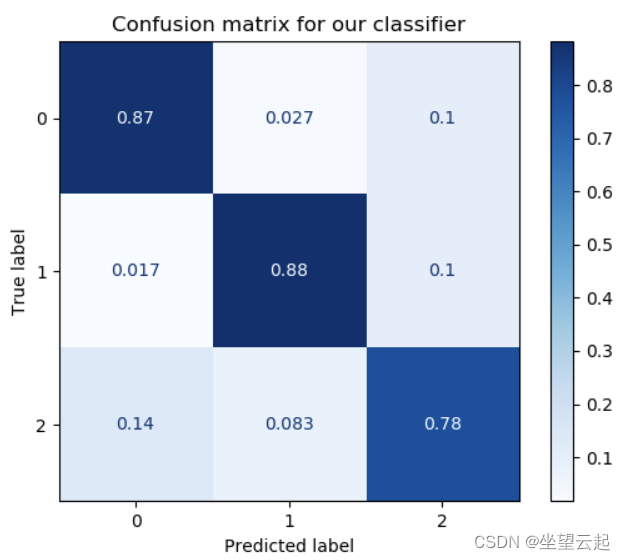
一个混淆矩阵的例子
它是一个归一化的混淆矩阵。它的描述了两个度量:
True label,这是您的测试集所代表的基本事实。
Predicted label,即机器学习模型对与真实标签对应的特征生成的预测。
例如,在上面的模型中,对于所有真实标签 1,预测标签为 1。这意味着来自第 1 类的所有样本都被正确分类。
对于其他类,性能也不错,但稍差一些。如您所见,对于第 2 类,一些样本被预测为第 0 类和第 1 类的一部分。
简而言之,它回答了“对于我的真实标签/基本事实,模型的预测效果如何?”这个问题。
2、示例2
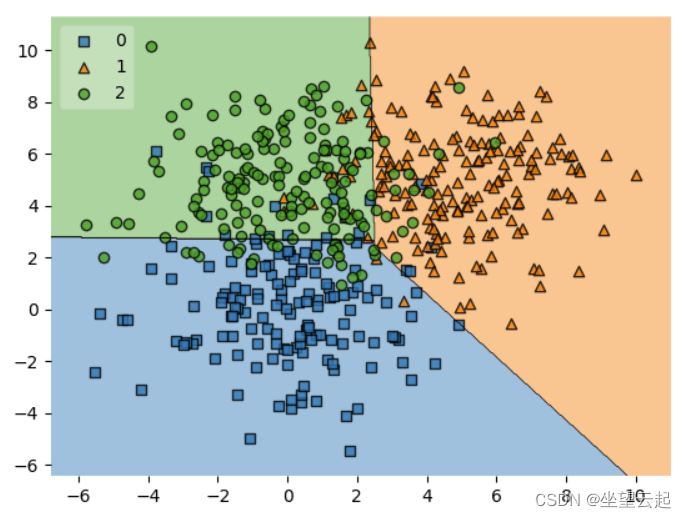
也可以从预测的角度看,问题将变为“对于我的预测标签,有多少预测实际上是预测类别的一部分?”。这是相反的观点,但在许多机器学习案例中可能是一个有意义的问题。
最优情况,是整个真实标签集等于预测标签集。在这些情况下,除了从左上角到右下角的线之外,您会在各处看到零。然而,在实践中,这种情况并不经常发生。很可能更加分散,例如下面这个 SVM 分类器,其中需要许多支持向量来绘制不能完美工作但足够充分的决策边界:

二、使用Scikit-learn 创建混淆矩阵
现在创建一个混淆矩阵。将使用 Python 和 Scikit-learn。
创建混淆矩阵涉及多个步骤:
1、生成示例数据集。需要数据来训练我们的模型。因此,我们将首先生成数据,以便我们接下来可以为 ML 模型类做出适当的选择。
2、选择机器学习模型类。显然,如果我们要评估一个模型,我们需要训练一个模型。我们将首先选择适合我们数据特征的特定类型的模型。
3、构建和训练 ML 模型。前两个步骤的结果是我们最终得到了一个训练有素的模型。
4、生成混淆矩阵。最后,基于训练好的模型,我们可以创建我们的混淆矩阵。
1、相应软件包
需要以下包,假定已经安装好了Python环境、Scikit-learn、Numpy、Matplotlib、Mlxtend
2、生成示例数据集
第一步是生成示例数据集。我们也将为此目的使用 Scikit-learn。首先,创建一个名为 的文件confusion-matrix.py。
(1)导入相关的包
# Imports from sklearn.datasets import make_blobs from sklearn.model_selection import train_test_split import numpy as np import matplotlib.pyplot as plt
Scikit-learn的make_blobs功能可以生成样本的“blob”或集群。这些斑点以某个点为中心,并且样本基于某个标准偏差分散在该点周围。这使您可以灵活地确定生成的数据集的位置和结构,从而使您可以试验各种 ML 模型。
在评估模型时,我们需要确保数据集在训练数据和测试数据之间进行分割。Scikit-learn使用train_test_split函数实现分割。
(2)相关配置
# Configuration options blobs_random_seed = 42 centers = [(0,0), (5,5), (0,5), (2,3)] cluster_std = 1.3 frac_test_split = 0.33 num_features_for_samples = 4 num_samples_total = 5000
随机种子描述了用于生成数据块的伪随机数生成器的初始化。您可能知道,没有随机数生成器是真正随机的。更重要的是,它们的初始化方式也不同。配置固定种子可确保每次运行脚本时,随机数生成器都以相同的方式初始化。如果出现奇怪的行为,您就知道它可能不是随机数生成器。
中心描述了我们数据块的二维空间中的中心。如您所见,我们今天有 4 个 blob。
聚类标准差描述了从随机点生成器使用的抽样分布中抽取样本的标准差。我们将其设置为 1.3;较低的数字会产生更好分离的集群,反之亦然。
训练/测试拆分的比例决定了为了测试目的拆分了多少数据。在我们的例子中,这是 33% 的数据。
我们样本的特征数量是 4,并且确实描述了我们有多少目标:4,因为我们有 4 个数据块。
最后,生成的样本数量。我们将其设置为 5000 个样本。
(3)生成数据
# Generate data inputs, targets = make_blobs(n_samples = num_samples_total, centers = centers, n_features = num_features_for_samples, cluster_std = cluster_std) X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=frac_test_split, random_state=blobs_random_seed)
(4)保存数据(可选)
# Save and load temporarily
np.save('./data_cf.npy', (X_train, X_test, y_train, y_test))
X_train, X_test, y_train, y_test = np.load('./data_cf.npy', allow_pickle=True)
(5)可视化数据
# Generate scatter plot for training data
plt.scatter(X_train[:,0], X_train[:,1])
plt.title('Linearly separable data')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()

3、训练一个SVM
(1)导入相关包
from sklearn import svm from sklearn.metrics import plot_confusion_matrix from mlxtend.plotting import plot_decision_regions
(2)训练分类器
# Initialize SVM classifier clf = svm.SVC(kernel='linear') # 拟合数据 clf = clf.fit(X_train, y_train)
4、生成混淆矩阵
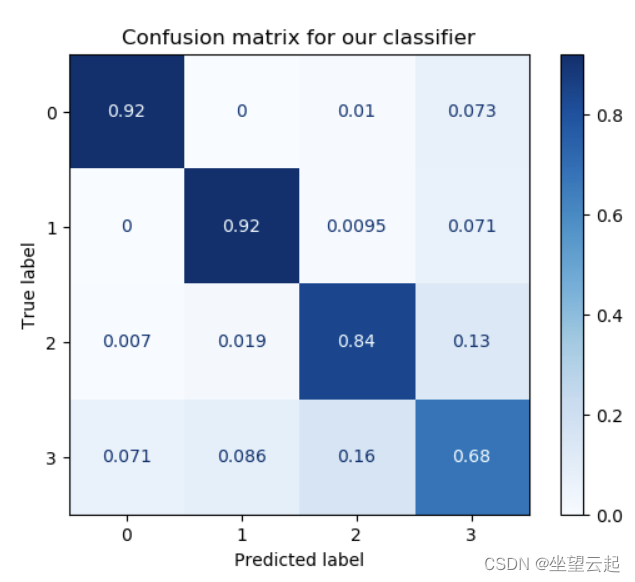
它是评估步骤的一部分,我们用它来可视化它在测试集上的预测和泛化能力。
使用plot_confusion_matrix调用为我们解决了这个问题,我们只需向它提供分类器 (clf)、测试集 (X_test和y_test)、颜色图以及是否对数据进行归一化。
# Generate confusion matrix
matrix = plot_confusion_matrix(clf, X_test, y_test,
cmap=plt.cm.Blues,
normalize='true')
plt.title('Confusion matrix for our classifier')
plt.show(matrix)
plt.show()
5、可视化边界
如果要生成边界图,需要安装 Mlxtend
# Get support vectors
support_vectors = clf.support_vectors_
# Visualize support vectors
plt.scatter(X_train[:,0], X_train[:,1])
plt.scatter(support_vectors[:,0], support_vectors[:,1], color='red')
plt.title('Linearly separable data with support vectors')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
# Plot decision boundary
plot_decision_regions(X_test, y_test, clf=clf, legend=2)
plt.show()
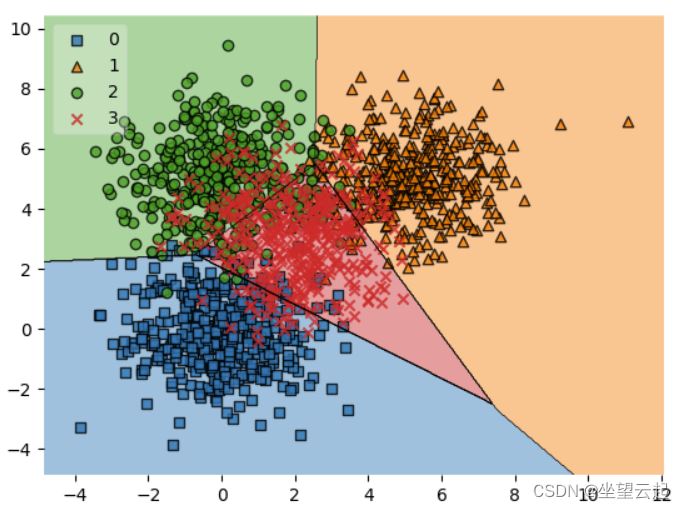
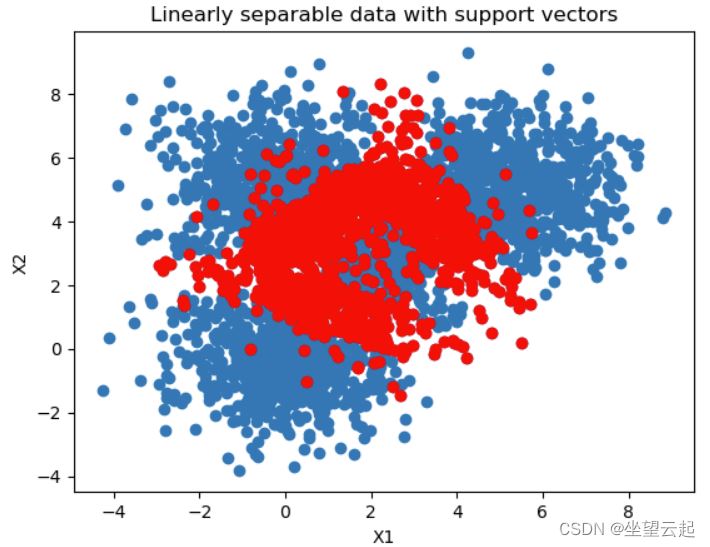
唯一表现不佳的班级是第 3 类,得分为 0.68。这可以通过查看决策边界图中的类来解释。在这里,由于这些样本被其他样本包围,很明显模型在生成决策边界时遇到了很大的困难。例如,我们可以通过使用考虑到这一点的不同内核函数来解决这个问题,从而确保更好的可分离性。
以上就是我们使用 Python 和 Scikit-learn 创建了一个混淆矩阵。在研究了混淆矩阵是什么,以及它如何显示真阳性、真阴性、假阳性和假阴性之后,我们给出了一个自己创建示例。
该示例包括生成数据集、为数据集选择合适的机器学习模型、构建、配置和训练它,最后解释结果,即混淆矩阵。
到此这篇关于使用Python和scikit-learn创建混淆矩阵的文章就介绍到这了,更多相关Python和scikit-learn混淆矩阵内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
利用python中的matplotlib打印混淆矩阵实例
前面说过混淆矩阵是我们在处理分类问题时,很重要的指标,那么如何更好的把混淆矩阵给打印出来呢,直接做表或者是前端可视化,小编曾经就尝试过用前端(D5)做出来,然后截图,显得不那么好看.. 代码: import itertools import matplotlib.pyplot as plt import numpy as np def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cma
-
python sklearn包——混淆矩阵、分类报告等自动生成方式
preface:做着最近的任务,对数据处理,做些简单的提特征,用机器学习算法跑下程序得出结果,看看哪些特征的组合较好,这一系列流程必然要用到很多函数,故将自己常用函数记录上.应该说这些函数基本上都会用到,像是数据预处理,处理完了后特征提取.降维.训练预测.通过混淆矩阵看分类效果,得出报告. 1.输入 从数据集开始,提取特征转化为有标签的数据集,转为向量.拆分成训练集和测试集,这里不多讲,在上一篇博客中谈到用StratifiedKFold()函数即可.在训练集中有data和target开始. 2.
-

详解使用python绘制混淆矩阵(confusion_matrix)
Summary 涉及到分类问题,我们经常需要通过可视化混淆矩阵来分析实验结果进而得出调参思路,本文介绍如何利用python绘制混淆矩阵(confusion_matrix),本文只提供代码,给出必要注释. Code # -*-coding:utf-8-*- from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt import numpy as np #labels表示你不同类别的代号,比如这里的de
-
使用Python和scikit-learn创建混淆矩阵的示例详解
目录 一.混淆矩阵概述 1.示例1 2.示例2 二.使用Scikit-learn 创建混淆矩阵 1.相应软件包 2.生成示例数据集 3.训练一个SVM 4.生成混淆矩阵 5.可视化边界 一.混淆矩阵概述 在训练了有监督的机器学习模型(例如分类器)之后,您想知道它的工作情况. 这通常是通过将一小部分称为测试集的数据分开来完成的,该数据用作模型以前从未见过的数据. 如果它在此数据集上表现良好,那么该模型很可能在其他数据上也表现良好 - 当然,如果它是从与您的测试集相同的分布中采样的. 现在,当您测试
-
利用Python创建位置生成器的示例详解
目录 介绍 开始 步骤 创建训练数据集 创建测试数据集 将合成图像转换回坐标 放在一起 结论 介绍 在这篇文章中,我们将探索如何在美国各地城市的地图数据和公共电动自行车订阅源上训练一个快速生成的对抗网络(GAN)模型. 然后,我们可以通过为包括东京在内的世界各地城市创建合成数据集来测试该模型的学习和概括能力. git clone https://github.com/gretelai/GAN-location-generator.git 在之前的一篇博客中,我们根据电子自行车订阅源中的精确位置数
-
Python程序包的构建和发布过程示例详解
关于我 编程界的一名小程序猿,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. 联系:hylinux1024@gmail.com 当我们开发了一个开源项目时,就希望把这个项目打包然后发布到 pypi.org 上,别人就可以通过 pip install 的命令进行安装.本文的教程来自于 Python 官方文档 , 如有不正确的地方欢迎评论拍砖. 0x00 创建项目 本文使用到的项目目录为 ➜ packaging-tuto
-
Python数学建模StatsModels统计回归之线性回归示例详解
目录 1.背景知识 1.1 插值.拟合.回归和预测 1.2 线性回归 2.Statsmodels 进行线性回归 2.1 导入工具包 2.2 导入样本数据 2.3 建模与拟合 2.4 拟合和统计结果的输出 3.一元线性回归 3.1 一元线性回归 Python 程序: 3.2 一元线性回归 程序运行结果: 4.多元线性回归 4.1 多元线性回归 Python 程序: 4.2 多元线性回归 程序运行结果: 5.附录:回归结果详细说明 1.背景知识 1.1 插值.拟合.回归和预测 插值.拟合.回归和预测
-
利用Python打造一个多人聊天室的示例详解
一.实验名称 建立聊天工具 二.实验目的 掌握Socket编程中流套接字的技术,实现多台电脑之间的聊天. 三.实验内容和要求 vii.掌握利用Socket进行编程的技术 viii.必须掌握多线程技术,保证双方可以同时发送 ix.建立聊天工具 x.可以和多个人同时进行聊天 xi.必须使用图形界面,显示双方的语录 四.实验环境 PC多台,操作系统Win7,win10(32位.64位) 具备软件python3.6 . 五.操作方法与实验步骤 服务端 1.调入多线程.与scoket包,用于实现多线程连接
-
Python基于keras训练实现微笑识别的示例详解
目录 一.数据预处理 二.训练模型 创建模型 训练模型 训练结果 三.预测 效果 四.源代码 pretreatment.py train.py predict.py 一.数据预处理 实验数据来自genki4k 提取含有完整人脸的图片 def init_file(): num = 0 bar = tqdm(os.listdir(read_path)) for file_name in bar: bar.desc = "预处理图片: "
-
Blender Python编程实现程序化建模生成超形示例详解
目录 正文 什么是超形(Supershapes, Superformula) 二维超形 n1 = n2 = n3 = 1 n1 = n2 = n3 = 0.3 其他特别情况 例子 1 例子 2 例子 3 例子 4 例子 5 奇异的形状 三维超形 Blender 生成超形 详细代码和注释如下 正文 Blender 并不是唯一一款允许你为场景编程和自动化任务的3D软件; 随着每一个新版本的推出,Blender 正逐渐成为一个可靠的 CG 制作一体化解决方案,从使用油脂铅笔的故事板到基于节点的合成.
-
Python使用Crypto库实现加密解密的示例详解
目录 一:crypto库安装 二:python使用crypto 1:crypto的加密解密组件des.py 2:crypto组件使用 知识补充 一:crypto库安装 pycrypto,pycryptodome是crypto第三方库,pycrypto已经停止更新三年了,所以不建议安装这个库:pycryptodome是pycrypto的延伸版本,用法和pycrypto 是一模一样的:所以只需要安装pycryptodome就可以了 pip install pycryptodome 二:python使
-
对python实现二维函数高次拟合的示例详解
在参加"数据挖掘"比赛中遇到了关于函数高次拟合的问题,然后就整理了一下源码,以便后期的学习与改进. 在本次"数据挖掘"比赛中感觉收获最大的还是对于神经网络的认识,在接近一周的时间里,研究了进40种神经网络模型,虽然在持续一周的挖掘比赛把自己折磨的惨不忍睹,但是收获颇丰.现在想想也挺欣慰自己在这段时间里接受新知识的能力.关于神经网络方面的理解会在后续博文中补充(刚提交完论文,还没来得及整理),先分享一下高次拟合方面的知识. # coding=utf-8 import
-
关于Python可视化Dash工具之plotly基本图形示例详解
Plotly Express是对 Plotly.py 的高级封装,内置了大量实用.现代的绘图模板,用户只需调用简单的API函数,即可快速生成漂亮的互动图表,可满足90%以上的应用场景. 本文借助Plotly Express提供的几个样例库进行散点图.折线图.饼图.柱状图.气泡图.桑基图.玫瑰环图.堆积图.二维面积图.甘特图等基本图形的实现. 代码示例 import plotly.express as px df = px.data.iris() #Index(['sepal_length', '