C语言中的自定义类型之结构体与枚举和联合详解
目录
- 1.结构体
- 1.1结构的基础知识
- 1.2结构的声明
- 1.3特殊的声明
- 1.4结构的自引用
- 1.5结构体变量的定义和初始化
- 1.6结构体内存对齐
- 1.7修改默认对齐数
- 1.8结构体传参
- 2.位段
- 2.1什么是位段
- 2.2位段的内存分配
- 2.3位段的跨平台问题
- 2.4位段的应用
- 3.枚举
- 3.1枚举类型的定义
- 3.2枚举的优点
- 3.3枚举的使用
- 4.联合
- 4.1联合类型的定义
- 4.2联合的特点
- 4.3联合大小的计算
1.结构体
1.1结构的基础知识
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
1.2结构的声明
struct tag
{
member-list;
}variable-list;
例如:
struct Stu
{
char name[20];//姓名
int age;//年龄
char sex[5];//性别
char id[20];//学号
};//分号不能丢
注意:声明结构体的时候,它的成员是不能被初始化的,只有当创建变量的时候才可以对结构体变量中的成员进行初始化。
1.3特殊的声明
在声明结构体的时候,可以进行不完全的声明,也就是在声明的时候省略掉结构体类型中的标签。
例如:
struct
{
int a;
char b;
float c;
}a;
struct
{
int a;
char b;
float c;
}*b;
这样的结构体称为匿名结构体类型。
那么下面这个代码合法吗?
b = &a;
如果在编译器中运行,会发现编译器给出一个警告

这说明编译器会将上面两个匿名的结构体类型当成完全不同的两个类型。
就算是这么写:
struct
{
int a;
char b;
float c;
}a, *c;
c = &a;
也是不行的。
而如果我们给这个匿名结构体重命名,接下来使用这个新的类型名,编译器就会将它们当成是同一个类型了,如下代码:
typedef struct
{
int a;
char b;
float c;
}new;
int main()
{
new a = { 0 };
new* b = &a;
return 0;
}
这时编译器就不会有警告了。
1.4结构的自引用
在结构中包含一个类型为该结构本身的成员是否可以呢?
struct Node
{
int data;
struct Node next;
};
如果这个代码可行的话,那么sizeof(struct Node)为多少呢?
可以发现这么写的话,结构体中有结构体,结构体中又有结构体,这样就会像没有限制条件的递归一样一直循环下去。
所以结构的自引用的正确写法应该是这样:
struct Node
{
int data;
struct Node* next;
};
通过指针来找到下一个结构体。
数据在内存中存储的结构有顺序表和链表:
顺序表:
链表:
其中链表可以通过这种自引用的方式找到下一个结构体,而最后一个结构体中的结构体指针给上一个NULL空指针就可以了。
注意:
typedef struct
{
int data;
Node* next;
}Node;
这个代码这么写是不行的,因为代码是一行一行往下读的,用新的类型名给创建结构体成员是,这个新的类型名还未被定义出来。
所以应该这么写,如下代码:
typedef struct Node
{
int data;
struct Node* next;
}Node;
相当于是声明了结构体后再对结构体类型重命名了。
1.5结构体变量的定义和初始化
struct Point
{
int x;
int y;
}p1; //声明类型的同时定义变量p1
struct Point p2; //定义结构体变量p2
struct Point p3 = { 1, 2 };//定义结构体变量p3的同时赋初值,简称初始化
struct Point
{
int x;
int y;
}p1 = {1, 2}; //声明类型的同时初始化
struct Point
{
int x;
int y;
};
struct Node
{
int data;
struct Point p;
}n1 = {1, {1, 2}};//结构体嵌套初始化
struct Node n2 = { 2, {3, 4} };//结构体嵌套初始化
1.6结构体内存对齐
知道结构体怎么声明,怎么定义变量之后,还要学会计算结构体的大小。
首先需要掌握结构体的对齐规则:
1.第1个成员在与结构体变量偏移量为0的地址处
2.其他成员变量要对齐到自身对齐数的整数倍的地址处
对齐数:取编译器默认的一个对齐数和该成员的大小其中的较小值,VS中默认的对齐数为8
3.结构体总大小为成员中最大对齐数的整数倍
4.如果是嵌套了结构体的情况,嵌套的结构体对齐到自己的成员中最大对齐数的整数倍的地址处,结构体的总体大小就是所有对齐数(包含嵌套结构体的对齐数)的整数倍
练习1:
struct s1
{
char c1;
int i;
char c2;
};
int main()
{
printf("%d\n", sizeof(struct s1));
return 0;
}
可以画图来算:
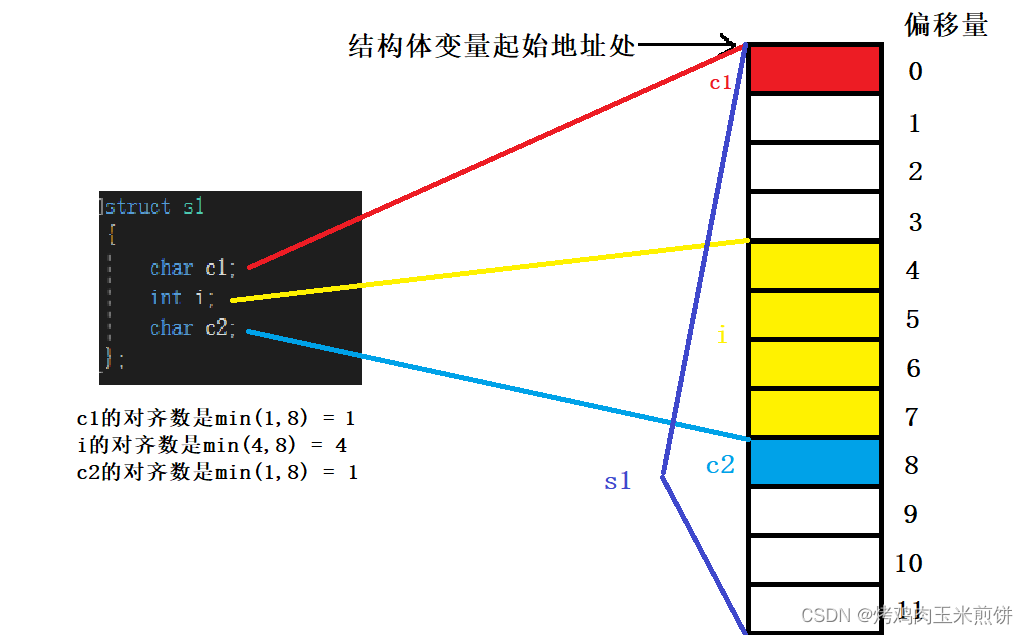
其中空白的空间没有被使用,对应的颜色为对应成员变量所占的空间,都是根据对齐规则来排放的,要注意成员的变量的对齐数是要取自身大小和默认对齐数两者之一的最小值的,最终计算结构体总大小是取这些对齐数中最大的对齐数的整数倍。
利用这个方法,来做一下下面几道题吧:
练习2:
struct s2
{
char c1;
char c2;
int i;
};
int main()
{
printf("%d\n", sizeof(struct s2));
return 0;
}
练习3:
struct s3
{
double d;
char c;
int i;
};
int main()
{
printf("%d\n", sizeof(struct s3));
return 0;
}
练习4:
struct s3
{
double d;
char c;
int i;
};
struct s4
{
char c1;
struct s3 s3;
double d;
};
int main()
{
printf("%d\n", sizeof(struct s4));
return 0;
}
其中成员s3的大小为16
为什么会存在内存对齐?
1.平台原因:
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则会出现硬件异常
2.性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐
原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问只需要一次访问。
例如,在32位平台上,处理器一次访问4个字节的数据
这是没对齐的情况:
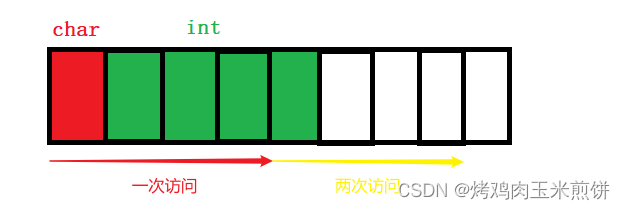
这是对齐的情况:
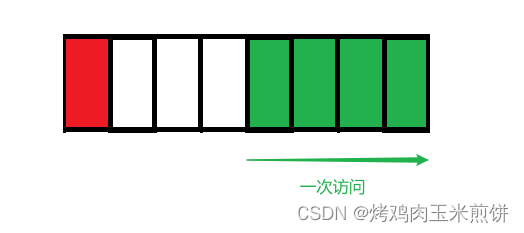
从对齐的位置开始一次访问就拿到了int类型的数据了
总体来说,结构体的内存对齐是拿空间换取时间的做法。
如果想要既要满足对齐,又要节省空间的话,可以这么做,让结构体中占用空间小的成员尽量集中在一起。
例如:
struct s1
{
char c1;
int i;
char c2;
};
struct s2
{
char c1;
char c2;
int i;
};
int main()
{
printf("%d\n", sizeof(struct s1));
printf("%d\n", sizeof(struct s2));
return 0;
}
s1和s2的类型成员一模一样,但是s1和s2所占空间的大小不同,s2所占空间明显要小。
1.7修改默认对齐数
#pragma是个预处理指令,可以修改默认对齐数
#pragma pack(4)//修改默认对齐数为4
struct s1
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
#pragma pack(1)//修改默认对齐数为1
struct s2
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认
int main()
{
printf("%d\n", sizeof(struct s1));
printf("%d\n", sizeof(struct s2));
return 0;
}
由于代码是一行一行往下读的,所以后面取消设置的默认对齐数对前面已经声明的结构体类型不会产生影响,结构体的对齐数在结构体声明的时候已经定下来了。
注意:不要随便修改默认对齐数。
结构在对齐方式不合适的时候,可以自己更改默认对齐数
1.8结构体传参
如下代码:
struct s
{
int num;
};
void print1(struct s s)
{
printf("%d\n", s.num);
}
void print2(struct s* p)
{
printf("%d\n", p->num);
}
int main()
{
struct s a = { 0 };
a.num = 123;
print1(a);//传结构体
print2(&a);//传结构体地址
return 0;
}
用print2函数会好一点,函数在传参的时候,参数是需要压栈的,会有时间和空间上的开销,如果传递一个结构体的时候,结构体过大,参数压栈的系统开销就会比较大,会导致性能上的下降。
所以在进行结构体传参的时候,要传结构体的地址。
2.位段
结构体可以实现位段的能力
2.1什么是位段
位段的成员和结构体是类似的,但有两个不同:
1.位段的成员必须是int、unsigned int或signed int或者char、unsignef char或者signed char
2.位段的成员名后面有一个冒号和一个数字(区别于结构体)
例如:
struct s
{
int _a : 2;
int _b : 5;
int _c : 8;
int _d : 10;
};
s就是一个位段类型
又比如:
struct x
{
short _a : 3;
short _b : 4;
};
x也是一个位段类型,要区别于结构体
那么,位段的大小是多少呢?
2.2位段的内存分配
1.位段的成员需要时整型家族类型的,如long long、int,short、char这些
2.位段上的空间是按照需要以4个字节(int)或者1个字节(char)来开辟的
3.位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段
如下代码:
struct s
{
char a : 3;
char b : 4;
char c : 5;
char d : 5;
};
struct s s = { 0 };
int main()
{
s.a = 12;
s.b = 8;
s.c = 7;
s.d = 9;
return 0;
}
位段是如何在内存中开辟空间的呢?
这里画个图来讲解一下:
首先我们假设在一个字节空间里面如果有放不下的位空间就会新开辟一个字节空间来存放位空间,比如成员a和成员b一共占了7个位,那么成员c需要占5个位,这时一个字节空间放不下了,就需要新开辟一个字节空间来存放c的这5个位,而d也需要5个位,这个时候就又需要再开辟一个新的字节空间了。
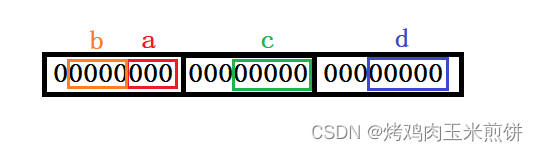
接下来对数据进行存储,如果数据大于对应的位空间,就要发生截断,而如果小于,那就要高位补0直到补满位空间
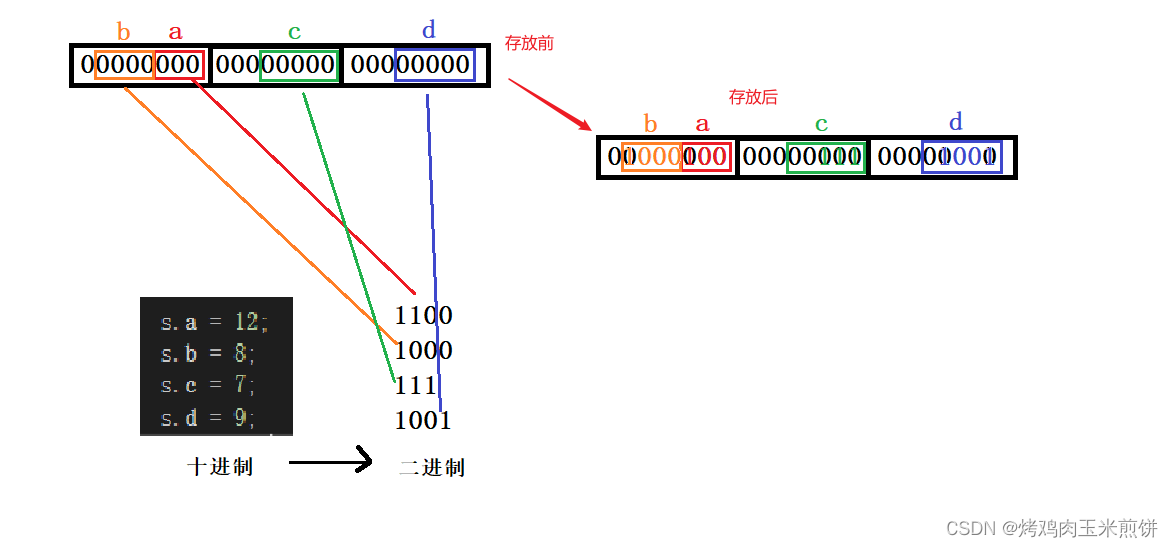
这样对应的字节上的数据转化成16进制位就是44、07、09
此时可以进入调试观察内存中的值来验证假设

这三个 内存空间的值可以看到和计算出来的是一样的,那么说明在MSVC这个编译器下位段就是这么开辟空间和存储数据
那么位段究竟有什么用呢?比如当一个数据的值只需要它的范围在0~3的时候,这个时候就可以用到位段了
2.3位段的跨平台问题
1.int位段被当成有符号数还是无符号数,这是不确定的
2.位段中最大位的数目不能确定(16位机器最大16,32位机器最大32,写成27,就会在16位机器中出现问题)
3.位段中的成员在内存中从左向右分配,还是从右向左分配,C语言的标准尚未定义
4.当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用剩余的位,这是不确定的
总结:和结构相比,位段可以达到同样的效果,可以很好的节省空间,但是又跨平台的问题存在
2.4位段的应用

这个功能可以用位段来实现的
3.枚举
枚举就是列举,把可能的值一 一列举出来
比如:
一周的星期一到星期天是有限的7天,可以一 一列举
性别有男、女、保密,可以一 一列举
月份有12个月,也可以一 一列举
对于这些例子,就可以使用枚举了
3.1枚举类型的定义
如下代码:
enum Day
{
Mon,
Tues,
Wed,
Thur,
Fri,
Sat,
Sun
};
enum Sex
{
MALE,
FEMALE,
SECRET
};
enum Color
{
RED,
GREEN,
BLUE
};
以上定义的enum Mon, enum Sex, enum Color都是枚举类型,{}中的内容是枚举类型的可能取值,也叫枚举常量。
这些可能的取值都是有初值的,默认第一个成员为0,然后递增1,也可以在定义枚举类型的时候对其中的内容进行初始化,注意,这是初始化,不是赋值。
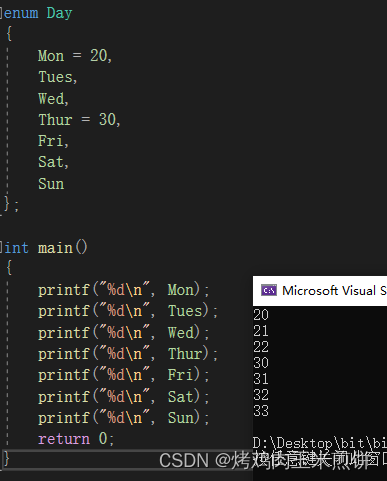
enum Color
{
RED = 2,
GREEN = 5,
BLUE = 8
};
要是其中的一个枚举常量改了初值,那么在这个常量开始往后的常量若是没有改初值的话,都是在其基础上递增1,比如:
3.2枚举的优点
可以使用#define来定义常量,为什么还要使用枚举常量呢?
枚举的优点:
1.增加代码的可读性和可维护性
2.和#define定义的标识符比较枚举类型检查,更加严谨
3.防止命名污染
4.便于调试
5.使用方便,一次可以定义多个常量
从test.c文件到test.exe文件中间要经过预编译,编译,反汇编和链接等过程,其中在预编译阶段,用#define定有的标识符常量会被转化成字面常量,这导致了在调试过程中看到的标识符常量和程序运行中是不一样的,不方便进行调试,而且用标识符常量是不能给枚举类型定义的变量初始化的
3.3枚举的使用
enum Color
{
RED = 2,
GREEN = 5,
BLUE = 8
};
enum Color clr = RED;
只能拿枚举常量给枚举变量初始化,才不会出现类型上的差异
4.联合
联合体也叫做共用体
4.1联合类型的定义
联合也是一种特殊的自定义类型,这种类型定义的变量包含了一系列的成员,特征是这些成员共用同一块空间,所以联合也叫共同体
//联合类型的声明
union Un
{
char c;
int i;
}a;
union Un un;//联合变量的定义
计算一下联合变量的大小:
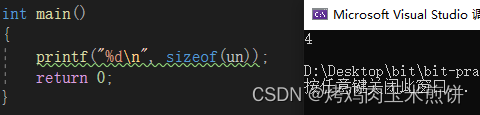
可以看到联合变量只占4个字节的大小,它其中的成员c和成员i是公用一个空间的
如图:
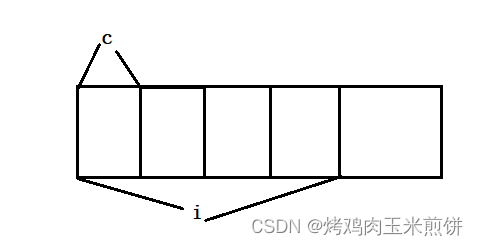
它们在内存中的第一个字节空间是共用的
4.2联合的特点
联合的成员是共用一块内存空间的,这样一个联合变量的大小,至少是最大成员的大小(引文联合至少得有能力保存最大的那个成员)
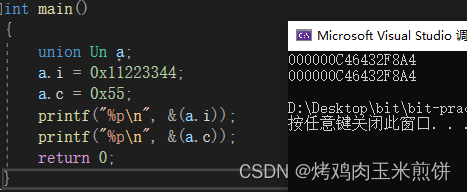
可以看到,成员c和成员i的起始地址是一样的
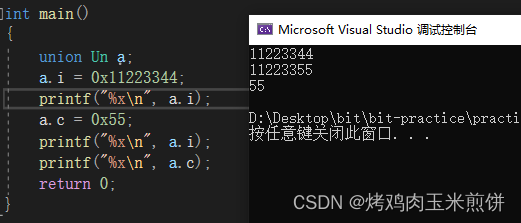
而在这个代码里,因为成员的空间是共用的,所以改变c的值的时候,i也相应的发生了变化(机器上是小端字节序存储)
利用联合的这个特点,可以用来判断联合的大小端存储模式
如下代码:
union Un
{
char c;
int i;
};
int main()
{
union Un un;
un.i = 1;
if (1 == un.c)
{
printf("小端");
}
else
{
printf("大端");
}
return 0;
}
4.3联合大小的计算
1.联合的大小至少是最大成员的大小
2.当最大成员的大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍
union Un1
{
char c[5];
int i;
};
union Un2
{
short c[7];
int i;
};
int main()
{
printf("%d\n", sizeof(union Un1));
printf("%d\n", sizeof(union Un2));
return 0;
}
Un1的最大对齐数是4,数组的对齐数根据数组元素的对齐数来定,Un1的最大成员大小是5,不是最大对齐数的整数倍,所以要进行对齐,Un1的最终大小为8
Un2的最大对齐数是4,最大成员大小是14,所以要对齐,最终大小是16
关于自定义类型的内容就到这里了,今后也会不定期更新
到此这篇关于C语言中的自定义类型之结构体与枚举和联合详解的文章就介绍到这了,更多相关C语言自定义类型内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C语言深入讲解指针与结构体的使用
目录 1 啥是指针 1.1指针与指针变量 1.2总结 2 指针和指针类型 2.1指针+-整数 3 野指针 3.1 野指针的成因 1指针未初始化 2指针越界访问 3指针指向的空间释放 3.2 如何避免野指针的出现 4 二级指针 5 指针数组 6 结构体 6.1 结构的声明 6.2 结构体变量的定义和初始化 6.3 结构体的访问 6.4 结构体传参 1 啥是指针 刚刚接触指针的同学肯定会很懵逼,指针是啥啊?指南针哈哈,不和大家开玩笑,我们进行正题吧,指针是本质是就是地址,但我们要注意我们口头上常说的
-
C语言中结构体的内存对齐规则讲解
目录 1.结构体的内存对齐规则 2.例子 3.为什么存在内存对齐 4.如何修改默认对齐数 1.结构体的内存对齐规则 1.第一个成员在与结构体变量偏移量为0的地址处. 2.其他成员变量都放在对齐数(成员的大小和默认对齐数的较小值)的整数倍的地址处. 对齐数=编译器默认的一个对齐数与该成员大小的较小值.(VS中默认的对齐数是8) 3.结构体总大小为最大对齐数(每个成员变量都有一个对齐数 )的整数倍. 4.如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最
-
C语言示例讲解结构体的声明与初始化方法
目录 一.结构体声明的结构 1.直接声明 2.使用typedef声明一个新的类型 3.不完全声明 二.结构体初始化 1.声明(同时定义)时直接赋值 2.定义时直接赋值 3.定义后赋值 4.指定初始化 一.结构体声明的结构 1.直接声明 struct tag { member-list: member-list: member-list: ... } variable-list; tag 是结构体类型的标签. member-list 结构体的元素定义,比如 int i; 或者 float f,或者
-
C语言全面梳理结构体知识点
目录 一.什么是结构体 二.结构体的定义 三.结构体变量的定义 四.结构体变量的初始化 五.结构体变量的赋值 六.引用结构体变量中的成员 七.结构体变量的传参问题 八.传输地址带来的问题 九.动态结构体数组 十.关键字typedef 十一.C++中的引用 一.什么是结构体 为了更好地模拟现实,需要把各种基本数据类型组合在一起构成一种新的复合数据类型,我们把这种自定义的数据类型称为结构体.结构体是程序员根据实际需求,把各种基本数据类型组合在一起构成的一种新的复合数据类型. 二.结构体的定义 结构体
-
C语言深入回顾讲解结构体对齐
目录 结构体对齐问题 结构体嵌套结构体 强制内存对齐 拓展求结构体成员的偏移量 结构体对齐问题 1.知识点的引入: struct data1 { char a;//1B int b;//4B }; void test01() { printf("%d\n",sizeof(struct data1));//8B 为啥? } 2.对齐规则(默认对齐) 第一步:确定分配单位(每行开辟多少字节) 结构体中最大的基本类型的长度 为分配单位. 第二步:确定成员的偏移位置. 偏移位置:成员自身类型的
-
C语言结构体数组常用的三种赋值方法(包含字符串)
目录 一.按照成员变量进行赋值(麻烦,好理解,字符串赋值需要strcpy) 二.对数组整体进行赋值.(一次性需要把所有的都添加进去,不需要strcpy) (1) 在声明数组的时候,进行赋值 (2)对有规律的数据赋值,比如学生结构体的学号是有规律的. 三.使用输入进行赋值 总结 一.按照成员变量进行赋值(麻烦,好理解,字符串赋值需要strcpy) 这里使用了一个Init函数,为了在进一步说明传参的使用.实际上赋值按照需要放在主函数就行. (使用strcpy函数需要添加头文件string.h) #i
-
详解C语言中结构体的使用
目录 结构体的声明 结构体成员的类型 结构体成员的访问 结构体的声明 结构体的定义:结构体是一些值的集合,这些值称为成员变量,结构体的每个成员可以是不同类型的变量. 举例: //定义结构体类型 struct tag//struct结构体关键字 tag结构体标签 struct tag结构体类型 { //成员变量 char name[20]; short age; char telphone[12]; char sex[5]; }s1,s2,s3;//s1,s2,s3是三个全局结构体变量 int m
-
C语言深入探究自定义类型之结构体与枚举及联合
目录 1.结构体 1.1结构体类型的声明 1.2结构的自引用 1.3结构体变量的定义和初始化 1.4结构体内存对齐 1.5结构体传参 1.6结构体实现位段(位段的填充&可移植性) 2.枚举 2.1枚举类型的定义 2.2枚举的优点 3.联合 3.1联合类型的定义 3.2联合的特点 3.3联合大小的计算 1.结构体 1.1结构体类型的声明 结构是一些值的集合,这些值称为成员变量.结构的每个成员可以是不同类型的变量 这里给大家举个列子演示一下: //定义一个学生的结构体 typedef struct
-
C语言详细分析结构体的内存对齐规则
目录 引例 结构体内存对齐规则 那么为什么要有内存对齐呢 如何优化 修改默认对齐数 结构体的内存对齐是一个特别热门的知识点! 引例 #include<iostream> using namespace std; struct S { char c; // 1 int a; // 4 char d; // 1 }; int main() { struct S s = { 'a',2,'y'}; cout << sizeof(struct S) << endl;// 12
-
C语言中的自定义类型之结构体与枚举和联合详解
目录 1.结构体 1.1结构的基础知识 1.2结构的声明 1.3特殊的声明 1.4结构的自引用 1.5结构体变量的定义和初始化 1.6结构体内存对齐 1.7修改默认对齐数 1.8结构体传参 2.位段 2.1什么是位段 2.2位段的内存分配 2.3位段的跨平台问题 2.4位段的应用 3.枚举 3.1枚举类型的定义 3.2枚举的优点 3.3枚举的使用 4.联合 4.1联合类型的定义 4.2联合的特点 4.3联合大小的计算 1.结构体 1.1结构的基础知识 结构是一些值的集合,这些值称为成员变量.结构
-
C语言自定义数据类型的结构体、枚举和联合详解
结构体基础知识 首先结构体的出现是因为我们使用C语言的基本类型无法满足我们的需求,比如我们要描述一本书,就需要书名,作者,价格,出版社等等一系列的属性,无疑C语言的基本数据类型无法解决,所以就出现了最重要的自定义数据类型,结构体. 首先我们创建一个书的结构体类型来认识一下 struct Book { char name[20]; char author[20]; int price; }; 首先是struct是结构体关键字,用来告诉编译器你这里声明的是一个结构体类型而不是其他的东西,然后是Boo
-
C#中的只读结构体(readonly struct)详解
翻译自 John Demetriou 2018年4月8日 的文章 <C# 7.2 – Let's Talk About Readonly Structs>[1] 在本文中,我们来聊一聊从 C# 7.2 开始出现的一个特性 readonly struct. 任一结构体都可以有公共属性.私有属性访问器等等.我们从以下结构体示例来开始讨论: public struct Person { public string Name { get; set; } public string Surname {
-
Golang中结构体映射mapstructure库深入详解
目录 mapstructure库 字段标签 内嵌结构 未映射字段 Metadata 弱类型输入 逆向转换 解码器 示例 在数据传递时,需要先编解码:常用的方式是JSON编解码(参见<golang之JSON处理>).但有时却需要读取部分字段后,才能知道具体类型,此时就可借助mapstructure库了. mapstructure库 mapstructure可方便地实现map[string]interface{}与struct间的转换:使用前,需要先导入库: go get github.com/m
-
基于C#调用c++Dll结构体数组指针的问题详解
C#调用c++dll文件是一件很麻烦的事情,首先面临的是数据类型转换的问题,相信经常做c#开发的都和我一样把学校的那点c++底子都忘光了吧(语言特性类). 网上有一大堆得转换对应表,也有一大堆的转换实例,但是都没有强调一个更重要的问题,就是c#数据类型和c++数据类型占内存长度的对应关系. 如果dll文件中只包含一些基础类型,那这个问题可能可以被忽略,但是如果是组合类型(这个叫法也许不妥),如结构体.类类型等,在其中的成员变量的长度的申明正确与否将决定你对dll文件调用的成败. 如有以下代码,其
-
Go结构体SliceHeader及StringHeader作用详解
目录 引言 SliceHeader 疑问 坑 StringHeader 0 拷贝转换 总结 引言 在 Go 语言中总是有一些看上去奇奇怪怪的东西,咋一眼一看感觉很熟悉,但又不理解其在 Go 代码中的实际意义,面试官却爱问... 今天要给大家介绍的是 SliceHeader 和 StringHeader 结构体,了解清楚他到底是什么,又有什么用,并且会在最后给大家介绍 0 拷贝转换的内容. 一起愉快地开始吸鱼之路. SliceHeader SliceHeader 如其名,Slice + Heade
-
goalng 结构体 方法集 接口实例详解
目录 一 前序 二 事出有因 errors.As 方法签名 三 结构体与实例的数据结构 1. 结构体类型 2. 实例 3 方法调用 3.1 方法表达式 3.2 值实例调用所有方法 3.3 指针实例调用所有方法 3.4 空指针无法调用值方法 四 接口 1 接口数据结构 2 接口赋值 值方法集 指针方法集 总结 一 前序 很多时候我们以为自己懂了,但内心深处却偶有困惑,知识是严谨的,偶有困惑就是不懂,很幸运通过大量代码的磨练,终于看清困惑,并弄懂了. 本篇包括结构体,类型, 及 接口相关知识,希望对
-
解析结构体的定义及使用详解
结构的定义 定义一个结构的一般形式为: struct 结构名 { 成员表列 }成员表由若干个成员组成,每个成员都是该结构的一个组成部分.对每个成员也必须作类型说明. 例如: 复制代码 代码如下: struct stu { int num; char name[20]; int age; } 结构类型变量的说明结构体定义并不是定义一个变量,而是定义了一种数据类型,这种类型是你定义的,它可以和语言本身所自有的简单数据类型一样使用(如 int ).结构体本身并不会被作为数据而开辟内存,真正作为数据而在
-
C语言中判断int,long型等变量是否赋值的方法详解
当然,如果你不赋值给局部变量,这样会导致整个程序的崩溃,因为,它的内容被系统指向了垃圾内存.下面我们看一段代码: 复制代码 代码如下: #include <stdio.h>#include <string.h>#include <stdlib.h>int globle_value;int my_sum(int value1, int value2);long my_sub(long value1, long value2);int main(void){ int aut