MySQL必备基础之分组函数 聚合函数 分组查询详解
目录
- 一、简单使用
- 二、搭配DISTINCT去重
- 三、COUNT()详细介绍
- 四、分组查询
一、简单使用
SUM:求和(一般用于处理数值型)
AVG:平均(一般用于处理数值型)
MAX:最大(也可以用于处理字符串和日期)
MIN:最小(也可以用于处理字符串和日期)
COUNT:数量(统计非空值的数据个数)
以上分组函数都忽略空NULL值的数据
SELECT SUM(salary) AS 和,AVG(salary) AS 平均,MAX(salary) AS 最大,MIN(salary) AS 最小,COUNT(salary) AS 数量 FROM employees;

二、搭配DISTINCT去重
(以上函数均可)
SELECT SUM(DISTINCT salary) AS 和,AVG(DISTINCT salary) AS 平均,COUNT( DISTINCT salary) AS 去重数量,COUNT(salary) AS 不去重数量 FROM employees;

三、COUNT()详细介绍
#相当于统计行数方式一 SELECT COUNT(*) FROM employees;
#相当于统计行数方式二,其中1可以用其他常量或字段替换 SELECT COUNT(1) FROM employees;
效率问题:
MYISAM存储引擎下,COUNT(*)的效率高
INNODB存储引擎下,COUNT(*)和COUNT(1)的效率差不多,比COUNT(字段)高
因此一般用COUNT(*)统计行数
四、分组查询
#其中[]内为可选 SELECT 分组函数,列表(要求出现在 GROUP BY 的后面) FROM 表 [WHERE 筛选条件] GROUP BY 分组列表 [ORDER BY 子句]
示例:
#查询每个工种的最高工资 SELECT MAX(salary) AS 最高工资,job_id FROM employees GROUP BY job_id;

#查询每个部门中,邮箱包含a的员工的平均工资(分组前的筛选) SELECT AVG(salary) AS 平均工资,department_id FROM employees WHERE email LIKE '%a%' GROUP BY department_id;
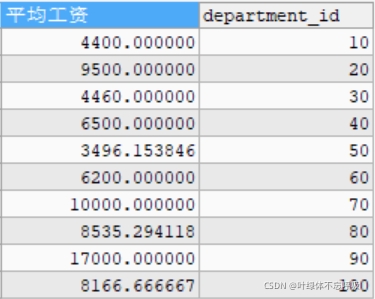
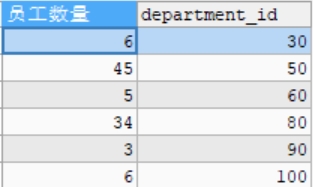
#查询部门员工数量大于2的部门的员工数量(分组后的筛选) #使用HAVING SELECT COUNT(*) AS 员工数量,department_id FROM employees GROUP BY department_id HAVING COUNT(*)>2;

#按照多字段 SELECT COUNT(*) AS 员工数量,job_id,department_id FROM employees GROUP BY job_id,department_id;

#完整结构 SELECT AVG(salary) AS 平均工资,department_id FROM employees WHERE department_id IS NOT NULL GROUP BY department_id HAVING AVG(salary)>9000 ORDER BY AVG(salary) DESC;

到此这篇关于MySQL必备基础之分组函数 聚合函数 分组查询详解的文章就介绍到这了,更多相关MySQL 分组函数 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL中聚合函数count的使用和性能优化技巧
本文的环境是Windows 10,MySQL版本是5.7.12-log 一. 基本使用 count的基本作用是有两个: 统计某个列的数据的数量: 统计结果集的行数: 用来获取满足条件的数据的数量.但是其中有一些与使用中印象不同的情况,比如当count作用一列.多列.以及使用*来表达整行产生的效果是不同的. 示例表如下: CREATE TABLE `NewTable` ( `id` int(11) NULL DEFAULT NULL , `name` varchar(30) NULL DEFAUL
-
MySQL 分组查询和聚合函数
概述 相信我们经常会遇到这样的场景:想要了解双十一天猫购买化妆品的人员中平均消费额度是多少(这可能有利于对商品价格区间的定位):或者不同年龄段的化妆品消费占比是多少(这可能有助于对商品备货量的预估). 这个时候就要用到分组查询,分组查询的目的是为了把数据分成多个逻辑组(购买化妆品的人员是一个组,不同年龄段购买化妆品的人员也是组),并对每个组进行聚合计算的过程:. 分组查询的语法格式如下: select cname, group_fun,... from tname [where conditio
-
MySQL查询排序与查询聚合函数用法分析
本文实例讲述了MySQL查询排序与查询聚合函数用法.分享给大家供大家参考,具体如下: 排序 为了方便查看数据,可以对数据进行排序 语法: select * from 表名 order by 列1 asc|desc [,列2 asc|desc,...] 说明 将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推 默认按照列值从小到大排列(asc) asc从小到大排列,即升序 desc从大到小排序,即降序 例1:查询未删除男生信息,按学号降序 select * from st
-

MySQL 聚合函数排序
目录 MySQL 结果排序-- 聚集函数 环境 查询结果排序 查询的分组与汇总 查一下 学生们平均年龄 查一下总人数是多少 查一下每个年龄有多少人 查出最大年龄 总结 MySQL 结果排序-- 聚集函数 环境 CREATE TABLE `student` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '学号', `student_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_c
-
MySql 中聚合函数增加条件表达式的方法
Mysql 与聚合函数在一起时候where条件和having条件的过滤时机 where 在聚合之前过滤 当一个查询包含了聚合函数及where条件,像这样的情况 select max(cid) from t where t.id<999 这时候会先进行过滤,然后再聚合.先过滤出ID<999的记录,再查找最大的cid返回. having 在聚合之后过滤 having在分组的时候会使用,对分组结果进行过滤,通常里面包含聚合函数. SELECT ip,MAX(id) FROM app GROUP BY
-
mysql如何对已经加密的字段进行模糊查询详解
目录 问题:但是加密之后我们怎么来查询呢? 1.了解HEX 函数与UNHEX 函数 2.了解AES_ENCRYPT函数与AES_DECRYPT函数 java工具类AES加解密同步使用 总结 场景:在模糊查询电话号码的时候,发现电话号码是进行加密过的,而传进来的参数却是明文的 PS:作为一个合格的程序员对用户的一些敏感数据都要进行加密处理操作 比如:姓名.手机号.身份证号等等. 问题:但是加密之后我们怎么来查询呢? 1.客户端一般是这样的 1.了解HEX 函数与UNHEX 函数 HEX 函数:将一
-
mysql的内连接,左连接和右链接查询详解
mysql> SELECT * FROM tcount_tbl; +---------------+--------------+ | runoob_author | runoob_count | +---------------+--------------+ | 菜鸟教程 | 10 | | RUNOOB.COM | 20 | | Google | 22 | +---------------+--------------+ 3 rows in set (0.01 sec) mysql> SE
-
MySQL必备基础之分组函数 聚合函数 分组查询详解
目录 一.简单使用 二.搭配DISTINCT去重 三.COUNT()详细介绍 四.分组查询 一.简单使用 SUM:求和(一般用于处理数值型) AVG:平均(一般用于处理数值型) MAX:最大(也可以用于处理字符串和日期) MIN:最小(也可以用于处理字符串和日期) COUNT:数量(统计非空值的数据个数) 以上分组函数都忽略空NULL值的数据 SELECT SUM(salary) AS 和,AVG(salary) AS 平均,MAX(salary) AS 最大,MIN(salary) AS 最小
-
Go语言基础函数基本用法及示例详解
目录 概述 语法 函数定义 一.函数参数 无参数无返回 有参数有返回 函数值传递 函数引用传递 可变参数列表 无默认参数 函数作为参数 二.返回值 多个返回值 跳过返回值 匿名函数 匿名函数可以赋值给一个变量 为函数类型添加方法 总结 示例 概述 函数是基本的代码块,用于执行一个任务 语法 函数定义 func 函数名称( 参数列表] ) (返回值列表]){ 执行语句 } 一.函数参数 无参数无返回 func add() 有参数有返回 func add(a, b int) int 函数值传递 fu
-
C语言函数基础教程分类自定义参数及调用示例详解
目录 1. 函数是什么? 2. C语言中函数的分类 2.1 库函数 2.1.1 为什么要有库函数 2.1.2 什么是库函数 2.1.3 主函数只能是main()吗 2.1.4常见的库函数 2.2 自定义函数 2.2.1自定义函数是什么 2.2.2为什么要有自定义函数 2.2.3函数的组成 2.2.4 举例展示 3. 函数的参数 3.1 实际参数(实参) 3.2 形式参数(形参) 4. 函数的调用 4.1 传值调用 4.2 传址调用 4.3 练习 4.3.1. 写一个函数判断一年是不是闰年
-
Node.js基础入门之回调函数及异步与同步详解
目录 回调函数 1. 什么是回调函数? 2. 回调函数实现机制 3. 回调函数用途 4. 回调函数示例 异步与同步 1. 什么是异步与同步? 2. 同步示例 3. 异步示例一 4. 异步示例二 异步的实现 1. 回调函数的同步示例 2. 异步事件示例 3. 异步示例截图 Promise基础 1. 什么是Promise ? 2. Promise特点 3. 异步的缺点 4. Promise保证异步顺序 经过前面两天的学习,已经对Node.js有了一个初步的认识,今天继续学习其他内容,并加以整理分享,
-
Sql Server 开窗函数Over()的使用实例详解
利用over(),将统计信息计算出来,然后直接筛选结果集 declare @t table( ProductID int, ProductName varchar(20), ProductType varchar(20), Price int) insert @t select 1,'name1','P1',3 union all select 2,'name2','P1',5 union all select 3,'name3','P2',4 union all select 4,'name4
-
Python函数装饰器的使用详解
目录 装饰器 装饰器的定义 装饰器的意义 装饰器的使用 无参装饰器 有参装饰器 实例练习 总结 装饰器 装饰器的定义 关于装饰器的定义,我们先来看一段github上大佬的定义: Function decorators are simply wrappers to existing functions.In the context of design patterns,decorators dynamically alter the functionality of a function, met
-
Go语言中函数可变参数(Variadic Parameter)详解
目录 基本语法 示例一:函数中获取可变参数 示例二:将切片传给可变参数 示例三:多参数 基本语法 在Python中,在函数参数不确定数量的情况下,可以使用如下方式动态在函数内获取参数,args实质上是一个list,而kwargs是一个dict def myFun(*args, **kwargs): 在Go语言中,也有类似的实现方式,只不过Go中只能实现类似*args的数组方式,而无法实现**kwargs的方式.实现这种方式,其实也是利用数组的三个点表达方式,我们这里来回忆一下. 关于三个点(…)
-
JavaScript数组对象高阶函数reduce的妙用详解
目录 reduce 是 JavaScript 数组对象上的一个高阶函数 计算数组的平均数 求数组的最大值 求数组的最小值 数组去重 计算数组中每个元素出现的次数 实现数组分组 计算数组中连续递增数字的长度 计算对象数组的属性总和 将对象数组转换为键值对对象 计算数组中出现次数最多的元素 实现 Promise 串行执行 对象属性值求和 按属性对数组分组 扁平化数组 合并对象 reduce 是 JavaScript 数组对象上的一个高阶函数 它可以用来迭代数组中的所有元素,并返回一个单一的值. 其常