教你使用Python根据模板批量生成docx文档
一、需求说明
能够根据模板批量生成docx文档。具体而言,读取excel中的数据,然后使用python批量生成docx文档。
二、实验准备
准备excel数据:
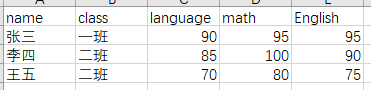
这里是关于学生语数英成绩的统计表,文件名为score.xls
准备模板:

这是给学生家长的成绩通知书,文件名为template.doc
另外,在使用python进行实验之前,需要先安装第三方库docxtpl和xlrd,直接pip install就行:
pip install docxtpl pip install xlrd
然后将xls和doc和python文件放在同一个目录下
三、代码实现
首先打开xls,读取数据:
workbook = xlrd.open_workbook(sheet_path)
然后从文件中获取第一个表格:
sheet = workbook.sheet_by_index(0)
然后遍历表格的每一行,将数据存入字典列表:
tables = []
for num in range(1, sheet.nrows):
stu = {}
stu['name'] = sheet.cell_value(num, 0)
stu['class'] = sheet.cell_value(num, 1)
stu['language'] = sheet.cell_value(num, 2)
stu['math'] = sheet.cell_value(num, 3)
stu['English'] = sheet.cell_value(num, 4)
tables.append(stu)
接下来将列表中的数据写入docx文档,其实这个过程可以在读数据时同时进行,即读完一行数据,然后生成一个文档。
首先在指定路径生成一个docx文档:
document = Document(word_path)
然后逐行进行正则表达式的替换:
paragraphs = document.paragraphs
text = re.sub('name', stu['name'], paragraphs[1].text)
paragraphs[1].text = text
text = re.sub('name', stu['name'], paragraphs[2].text)
text = re.sub('class', stu['class'], text)
text = re.sub('language', str(stu['language']), text)
text = re.sub('math', str(stu['math']), text)
text = re.sub('English', str(stu['English']), text)
paragraphs[2].text = text
其实不关心格式问题的,到现在为止就已经结束了。但是这样替换后docx中被替换的文字格式也被更改为系统默认的正文格式,所以接下来是将这些改成自己想要的格式:
遍历需要更改格式的段落,然后更改字体大小和字体格式:
for run in paragraph.runs:
run.font.size = Pt(16)
run.font.name = "宋体"
r = run._element.rPr.rFonts
r.set(qn("w:eastAsia"), "宋体")
最后保存文件:
document.save(path + "\\" + r"{}的成绩通知单.docx".format(stu['name']))
完整代码:
from docxtpl import DocxTemplate
import pandas as pd
import os
import xlrd
path = os.getcwd()
# 读表格
sheet_path = path + "\score.xls"
workbook = xlrd.open_workbook(sheet_path)
sheet = workbook.sheet_by_index(0)
tables = []
for num in range(1, sheet.nrows):
stu = {}
stu['name'] = sheet.cell_value(num, 0)
stu['class'] = sheet.cell_value(num, 1)
stu['language'] = sheet.cell_value(num, 2)
stu['math'] = sheet.cell_value(num, 3)
stu['English'] = sheet.cell_value(num, 4)
tables.append(stu)
print(tables)
# 写文档
from docx import Document
import re
from docx.oxml.ns import qn
from docx.shared import Cm,Pt
for stu in tables:
word_path = path + "\\template.doc"
document = Document(word_path)
paragraphs = document.paragraphs
text = re.sub('name', stu['name'], paragraphs[1].text)
paragraphs[1].text = text
text = re.sub('name', stu['name'], paragraphs[2].text)
text = re.sub('class', stu['class'], text)
text = re.sub('language', str(stu['language']), text)
text = re.sub('math', str(stu['math']), text)
text = re.sub('English', str(stu['English']), text)
paragraphs[2].text = text
for paragraph in paragraphs[1:]:
for run in paragraph.runs:
run.font.size = Pt(16)
run.font.name = "宋体"
r = run._element.rPr.rFonts
r.set(qn("w:eastAsia"), "宋体")
document.save(path + "\\" + r"{}的成绩通知单.docx".format(stu['name']))
四、实验结果
文件中的文件:

生成的文件样例:

到此这篇关于教你使用Python根据模板批量生成docx文档的文章就介绍到这了,更多相关Python批量生成docx文档内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python利用faker库批量生成测试数据
安装 pip install faker 使用 简单使用 本库可生成姓名.地址.电话.邮箱.公司等等一系列数据.首先导入库,实例化: from faker import Faker fake = Faker() 先看看正面生成一个人的姓名地址吧: for _ in range(10): print(fake.name()) rs. Elizabeth Carter MD Mark Obrien Madeline Oliver Ruth Newman Lori Bennett Victor Nol
-
python批量生成条形码的示例
在工作中,有时会遇见需要将数字转换为条码的问题,每次都需要打开条码转换的网站,一次次的转换后截图,一两个还行,但是当需要转换的数量较多时,就会显得特别麻烦,弄不好还会遗漏或者重复,为了解决这个问题,使用python写了以下脚本,用来解决此问题 1.安装python-barcode库和pillow库 需要导入的python库 import barcode from barcode.writer import ImageWriter 2.将需要转换的条形码数据保存到同级目录下的 EAN.txt 内
-

如何使用python-opencv批量生成带噪点噪线的数字验证码
第一次使用csdn写一个文章,如果有什么写的不对的地方,欢迎在下面评论指正,谢谢各位. 1.明确要使用的包 首先就是opencv的函数库,还有python自带的random和PIL(Image.ImageDraw.ImageFont),一般pthon3以上的版本都是内置安装的,如果没有安装可以通过pip install的方法安装具体操作如图: 输入完按回车键即可安装,因为我已经安装了,就不输入回车键了,安装完了之后可以通过import的方式检验是否安装成功.记住先输入python进入python
-
python批量生成本地ip地址的方法
本文实例讲述了python批量生成本地ip地址的方法.分享给大家供大家参考.具体分析如下: 这段代码用于在本地计算机上生成本地ip地址绑定到网卡,生成的是一个bat的批处理文件,运行此批处理文件,可以通过ipconfig查看 #!/usr/bin/python2.7 # -*- coding: utf-8 -*- # Filename: AddIPAliases.py import re,sys,socket,struct # 1. 判断IP地址是否合法: 2. 判断用户输入的IP是否在Clas
-
python基于opencv批量生成验证码的示例
基本思路是使用opencv来把随机生成的字符,和随机生成的线段,放到一个随机生成的图像中去. 虽然没有加复杂的形态学处理,但是目前看起来效果还不错 尝试生成1000张图片,但是最后只有998张,因为有有重复的,被覆盖掉了. 代码如下: import cv2 import numpy as np line_num = 10 pic_num = 1000 path = "./imgs/" def randcolor(): return (np.random.randint(0,255),n
-
基于Python批量生成指定尺寸缩略图代码实例
这篇文章主要介绍了基于Python批量生成指定尺寸缩略图代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 最近我们商城上架的应用越来越丰富了.但在应用上传的过程中遇到这样的一个问题:每一个上架的应用需要配置一个应用封面图片,并且封面的图片大小有指定的范围:300*175.而 我们制作完的图片一般都会大于这个尺寸.所以每次手动调整大小,又让我产生了偷懒的想法,想法有了那就开始行动吧. 代码 import requests as req fr
-
Python批量生成幻影坦克图片实例代码
前言 说到幻影坦克,我就想起红色警戒里的-- 幻影坦克(Mirage Tank),<红色警戒2>以及<尤里的复仇>中盟军的一款伪装坦克,盟军王牌坦克之一.是爱因斯坦在德国黑森林中研发的一种坦克.虽然它无法隐形,但它却可以利用先进的光线偏折原理可以伪装成树木(岩石或草丛)来隐藏自己. 在一些MOD中,幻影坦克可以选择变换的树木,这样便可以和背景的树木融合,而不会令人生疑. 额!这是从什么百科ctrl+v过来的吗.我跟你说个P~ UBG 不过话说回来,里面有一句说到和背景融合,这大概就
-
利用Python脚本批量生成SQL语句
通过Python脚本批量生成插入数据的SQL语句 原始SQL语句: INSERT INTO system_user (id, login_name, name, password, salt, code, createtime, email, main_org, positions, status, used, url, invalid, millis, id_card, phone_no, past, end_date, start_date) VALUES ('6', 'db', 'db',
-
Python操作Word批量生成合同的实现示例
背景:大约有3K家商家需要重新确认信息并签订合同.合同是统一的Word版本.每个供应商需要修改合同内的金额部分.人工处理方式需要每个复制粘贴且金额要生成大写金额.基于重复工作可偷懒.用Python解救一下. #导入对应数据库 import numpy as np import pandas as pd import os import docx from docx.shared import Pt from docx.oxml.ns import qn #修改项目文件地址 os.chdir(r'
-
Python3批量生成带logo的二维码方法
最近有个需求:批量生成带Logo的二维码 生成二维码比较简单,网上的资源也比较多,不赘述了.自己研究了一下加了logo并且美化了一下(网上的资源直接加Logo特别丑!!!忍不了!!!),直接上代码: def create_qrcode(url, filename): qr = qrcode.QRCode( version=1, #设置容错率为最高 error_correction=qrcode.ERROR_CORRECT_H, box_size=10, border=4, ) qr.add_da
-
利用Python批量生成任意尺寸的图片
实现效果 通过源图片,在当前工作目录的/img目录下生成1000张,分别从1*1到1000*1000像素的图片. 效果如下: 目录结构 实现示例 # -*- coding: utf-8 -*- import threading from PIL import Image image_size = range(1, 1001) def start(): for size in image_size: t = threading.Thread(target=create_image, args=(s
-
Python如何批量生成和调用变量
这几天写代码中遇到的一个常见问题,在Python中如何批量的生成一些变量,如生成变量X1, X2, X3,并在后续的方法中调用,完成赋值.取值等操作.这个问题也算是常见的吧,之前遇到过,也不了了之了.而这次遇到了同样的问题,虽然是创建三个变量数量较少,但从代码维护和易读性的角度考虑,需要使用一些恰当的手段,来避免重复写三次同样代码带来的弊端.一百次,一万次?总不能复制这么多次吧.(为何不复制?详情参考软件工程中的软件维护). 因此有必要养成良好的习惯,而不是复制三次同样的代码. 使用Locals
-
python用faker库批量生成假数据
楔子 我们平时在做测试的时候,经常会使用一些假数据,而Python中有一个包叫faker(不是打LOL的那个),专门用来生成假数据,并且生成的假数据非常逼真,下面我们就来看一下. faker使用方法 基本使用 faker使用起来非常简单,我们看一下就知道了. from faker import Faker # 导入Faker这个类, 实例化即可 fake = Faker(locale="zh_CN") # 然后调用里面的方法即可生成相应的假数据 print(fake.name()) #
-
python批量生成身份证号到Excel的两种方法实例
身份证号码的编排规则 前1.2位数字表示:所在省份的代码: 第3.4位数字表示:所在城市的代码: 第5.6位数字表示:所在区县的代码: 第7~14位数字表示:出生年.月.日: 第15.16位数字表示:所在地的派出所的代码: 第17位数字表示性别:奇数表示男性,偶数表示女性: 第18位数字是校检码,计算方法如下: (1)将前面的身份证号码17位数分别乘以不同的系数.从第一位到第十七位的系数分别为:7-9-10-5-8-4-2-1-6-3-7-9-10-5-8-4-2. (2)将这17位数字和系数相