python爬虫框架Scrapy基本应用学习教程
在正式编写爬虫案例前,先对 scrapy 进行一下系统的学习。
scrapy 安装与简单运行
使用命令 pip install scrapy 进行安装,成功之后,还需要随手收藏几个网址,以便于后续学习使用。
scrapy 官网:https://scrapy.org
scrapy 文档:https://doc.scrapy.org/en/latest/intro/tutorial.html
scrapy 更新日志:https://docs.scrapy.org/en/latest/news.html
安装完毕之后,在控制台直接输入 scrapy,出现如下命令表示安装成功。
> scrapy Scrapy 2.5.0 - no active project Usage: scrapy <command> [options] [args] Available commands:
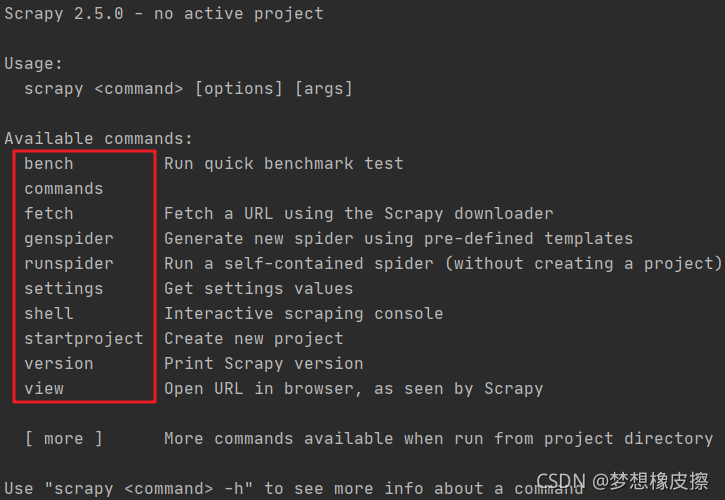
上述截图是 scrapy 的内置命令列表,标准的格式的 scrapy <command> <options> <args>,通过 scrapy <command> -h 可以查看指定命令的帮助手册。
scrapy 中提供两种类型的命令,一种是全局的,一种的项目中的,后者需要进入到 scrapy 目录才可运行。
这些命令无需一开始就完全记住,随时可查,有几个比较常用,例如:
scrpy startproject <项目名>
该命令先依据 项目名 创建一个文件夹,然后再文件夹下创建于个 scrpy 项目,这一步是后续所有代码的起点。
> scrapy startproject my_scrapy
> New Scrapy project 'my_scrapy', using template directory 'e:\pythonproject\venv\lib\site-packages\scrapy\templates\project', created in: # 一个新的 scrapy 项目被创建了,使用的模板是 XXX,创建的位置是 XXX
E:\pythonProject\滚雪球学Python第4轮\my_scrapy
You can start your first spider with: # 开启你的第一个爬虫程序
cd my_scrapy # 进入文件夹
scrapy genspider example example.com # 使用项目命令创建爬虫文件
上述内容增加了一些注释,可以比对着进行学习,默认生成的文件在 python 运行时目录,如果想修改项目目录,请使用如下格式命令:
scrapy startproject myproject [project_dir]
例如
scrapy startproject myproject d:/d1
命令依据模板创建出来的项目结构如下所示,其中红色下划线的是项目目录,而绿色下划线才是 scrapy 项目,如果想要运行项目命令,则必须先进入红色下划线 my_scrapy 文件夹,在项目目录中才能控制项目。
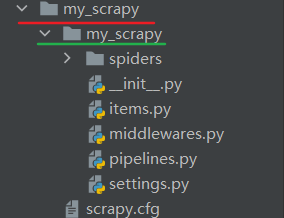
下面生成一个爬虫文件
使用命令 scrapy genspider [-t template] <name> <domain> 生成爬虫文件,该方式是一种快捷操作,也可以完全手动创建。创建的爬虫文件会出现在 当前目录或者项目文件夹中的 spiders 文件夹中,name 是爬虫名字,domain 用在爬虫文件中的 alowed_domains 和 start_urls 数据中,[-t template] 表示可以选择生成文件模板。
查看所有模板使用如下命令,默认模板是 basic。
> scrapy genspider -l basic crawl csvfeed xmlfeed
创建第一个 scrapy 爬虫文件,测试命令如下:
>scrapy genspider pm imspm.com Created spider 'pm' using template 'basic' in module: my_project.spiders.pm
此时在 spiders 文件夹中,出现 pm.py 文件,该文件内容如下所示:
import scrapy
class PmSpider(scrapy.Spider):
name = 'pm'
allowed_domains = ['imspm.com']
start_urls = ['http://imspm.com/']
def parse(self, response):
pass
测试 scrapy 爬虫运行
使用命令 scrapy crawl <spider>,spider 是上文生成的爬虫文件名,出现如下内容,表示爬虫正确加载。
>scrapy crawl pm 2021-10-02 21:34:34 [scrapy.utils.log] INFO: Scrapy 2.5.0 started (bot: my_project) [...]
scrapy 基本应用
scrapy 工作流程非常简单:
采集第一页网页源码;解析第一页源码,并获取下一页链接;请求下一页网页源码;解析源码,并获取下一页源码;[…]过程当中,提取到目标数据之后,就进行保存。
接下来为大家演示 scrapy 一个完整的案例应用,作为 爬虫 120 例 scrapy 部分的第一例。
> scrapy startproject my_project 爬虫 > cd 爬虫 > scrapy genspider pm imspm.com
获得项目结构如下:
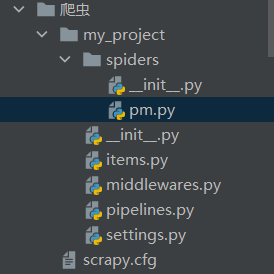
上图中一些文件的简单说明。
scrapy.cfg:配置文件路径与部署配置;
items.py:目标数据的结构;
middlewares.py:中间件文件;
pipelines.py:管道文件;
settings.py:配置信息。
使用 scrapy crawl pm 运行爬虫之后,所有输出内容与说明如下所示:
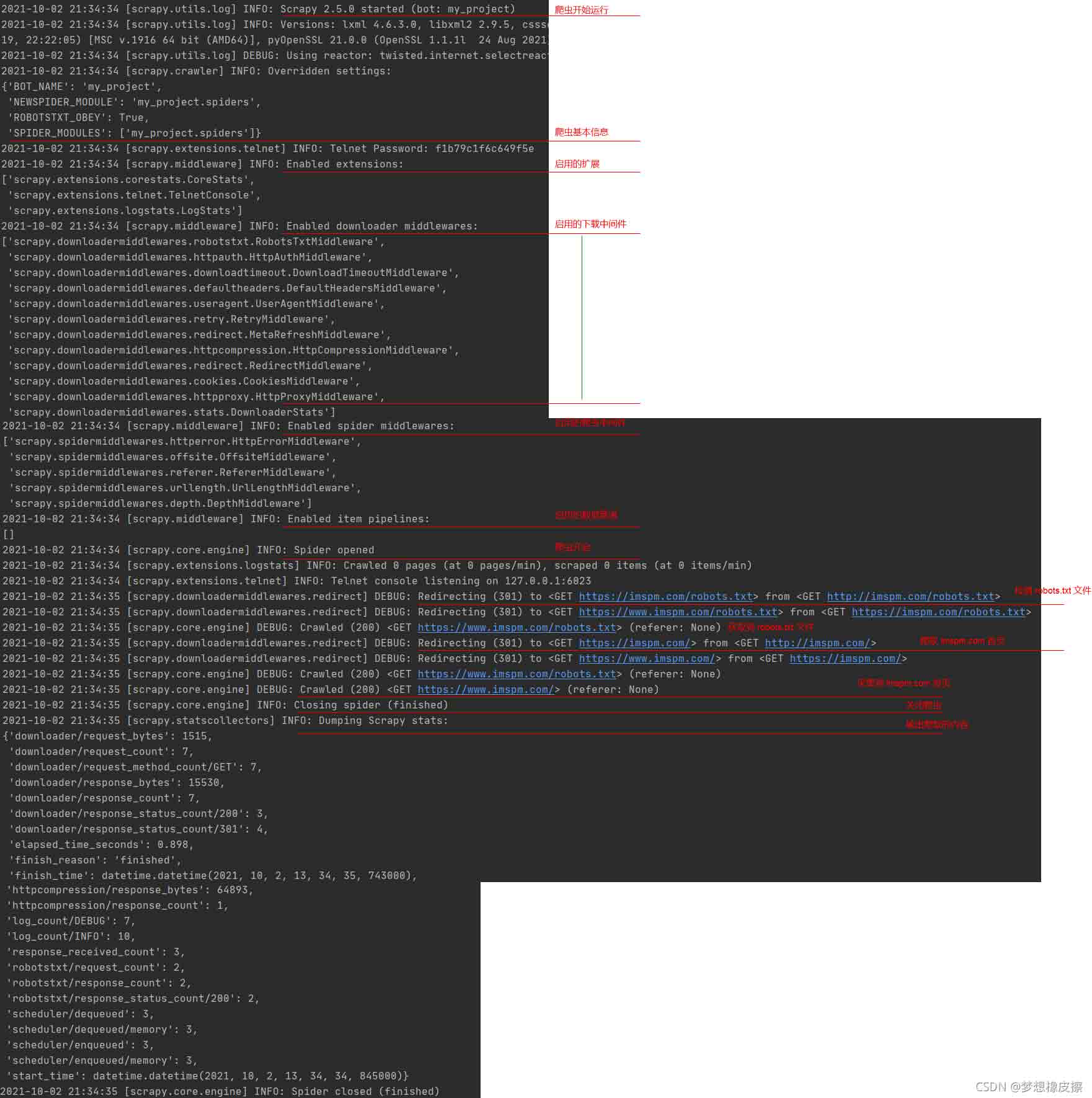
上述代码请求次数为 7 次,原因是在 pm.py 文件中默认没有添加 www,如果增加该内容之后,请求次数变为 4。

现在的 pm.py 文件代码如下所示:
import scrapy
class PmSpider(scrapy.Spider):
name = 'pm'
allowed_domains = ['www.imspm.com']
start_urls = ['http://www.imspm.com/']
def parse(self, response):
print(response.text)
其中的 parse 表示请求 start_urls 中的地址,获取响应之后的回调函数,直接通过参数 response 的 .text 属性进行网页源码的输出。

获取到源码之后,要对源码进行解析与存储
在存储之前,需要手动定义一个数据结构,该内容在 items.py 文件实现,对代码中的类名进行了修改,MyProjectItem → ArticleItem。
import scrapy
class ArticleItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 文章标题
url = scrapy.Field() # 文章地址
author = scrapy.Field() # 作者
修改 pm.py 文件中的 parse 函数,增加网页解析相关操作,该操作类似 pyquery 知识点,直接观察代码即可掌握。
def parse(self, response):
# print(response.text)
list_item = response.css('.list-item-default')
# print(list_item)
for item in list_item:
title = item.css('.title::text').extract_first() # 直接获取文本
url = item.css('.a_block::attr(href)').extract_first() # 获取属性值
author = item.css('.author::text').extract_first() # 直接获取文本
print(title, url, author)
其中 response.css 方法返回的是一个选择器列表,可以迭代该列表,然后对其中的对象调用 css 方法。
item.css('.title::text'),获取标签内文本;
item.css('.a_block::attr(href)'),获取标签属性值;
extract_first():解析列表第一项;extract():获取列表。
在 pm.py 中导入 items.py 中的 ArticleItem 类,然后按照下述代码进行修改:
def parse(self, response):
# print(response.text)
list_item = response.css('.list-item-default')
# print(list_item)
for i in list_item:
item = ArticleItem()
title = i.css('.title::text').extract_first() # 直接获取文本
url = i.css('.a_block::attr(href)').extract_first() # 获取属性值
author = i.css('.author::text').extract_first() # 直接获取文本
# print(title, url, author)
# 对 item 进行赋值
item['title'] = title
item['url'] = url
item['author'] = author
yield item
此时在运行 scrapy 爬虫,就会出现如下提示信息。
此时完成了一个单页爬虫
接下来对 parse 函数再次改造,使其在解析完第 1 页之后,可以解析第 2 页数据。
def parse(self, response):
# print(response.text)
list_item = response.css('.list-item-default')
# print(list_item)
for i in list_item:
item = ArticleItem()
title = i.css('.title::text').extract_first() # 直接获取文本
url = i.css('.a_block::attr(href)').extract_first() # 获取属性值
author = i.css('.author::text').extract_first() # 直接获取文本
# print(title, url, author)
# 对 item 进行赋值
item['title'] = title
item['url'] = url
item['author'] = author
yield item
next = response.css('.nav a:nth-last-child(2)::attr(href)').extract_first() # 获取下一页链接
# print(next)
# 再次生成一个请求
yield scrapy.Request(url=next, callback=self.parse)
上述代码中,变量 next 表示下一页地址,通过 response.css 函数获取链接,其中的 css 选择器请重点学习。
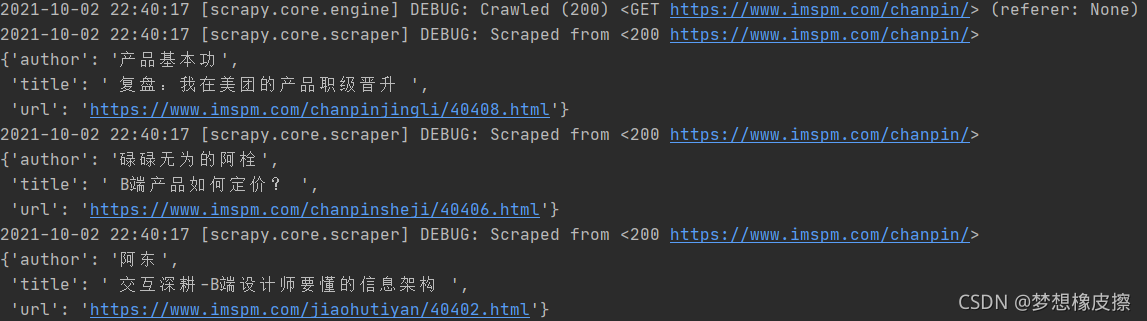
yield scrapy.Request(url=next, callback=self.parse) 表示再次创建一个请求,并且该请求的回调函数是 parse 本身,代码运行效果如下所示。

如果想要保存运行结果,运行下面的命令即可。
scrapy crawl pm -o pm.json
如果想要将每条数据存储为单独一行,使用如下命令即可 scrapy crawl pm -o pm.jl 。
生成的文件还支持 csv 、 xml、marchal、pickle ,可自行尝试。
下面将数据管道利用起来
打开 pipelines.py 文件,修改类名 MyProjectPipeline → TitlePipeline,然后编入如下代码:
class TitlePipeline:
def process_item(self, item, spider): # 移除标题中的空格
if item["title"]:
item["title"] = item["title"].strip()
return item
else:
return DropItem("异常数据")
该代码用于移除标题中的左右空格。
编写完毕,需要在 settings.py 文件中开启 ITEM_PIPELINES 配置。
ITEM_PIPELINES = {
'my_project.pipelines.TitlePipeline': 300,
}
300 是 PIPELINES 运行的优先级顺序,根据需要修改即可。再次运行爬虫代码,会发现标题的左右空格已经被移除。
到此 scrapy 的一个基本爬虫已经编写完毕。
以上就是python爬虫框架Scrapy基本应用学习教程的详细内容,更多关于python爬虫框架Scrapy的资料请关注我们其它相关文章!
相关推荐
-
python scrapy拆解查看Spider类爬取优设网极细讲解
目录 拆解 scrapy.Spider scrapy.Spider 属性值 scrapy.Spider 实例方法与类方法 爬取优设网 Field 字段的两个参数: 拆解 scrapy.Spider 本次采集的目标站点为:优设网 每次创建一个 spider 文件之后,都会默认生成如下代码: import scrapy class UiSpider(scrapy.Spider): name = 'ui' allowed_domains = ['www.uisdc.com'] start_urls =
-

python实战scrapy操作cookie爬取博客涉及browsercookie
browsercookie 知识铺垫 第一个要了解的知识点是使用 browsercookie 获取浏览器 cookie ,该库使用命令 pip install browsercookie 安装即可. 接下来获取 firefox 浏览器的 cookie,不使用 chrome 谷歌浏览器的原因是在 80 版本之后,其 cookie 的加密方式进行了修改,所以使用 browsercookie 模块会出现如下错误 win32crypt must be available to decrypt Chrom
-
python爬虫框架scrapy代理中间件掌握学习教程
目录 代理的使用场景 使用 HttpProxyMiddleware 中间件 代理的使用场景 编写爬虫代码的程序员,永远绕不开就是使用代理,在编码过程中,你会碰到如下情形: 网络不好,需要代理: 目标站点国内访问不了,需要代理: 网站封杀了你的 IP,需要代理. 使用 HttpProxyMiddleware 中间件 本次的测试站点依旧使用 http://httpbin.org/,通过访问 http://httpbin.org/ip 可以获取当前请求的 IP 地址. HttpProxyMiddlew
-
安装mysql noinstall zip版
版本号: 5.5.19-winx64 1.将my-small.ini 改为my.ini (请按照自己的机器配置更改) 2.在命令行输入: \bin\mysqld –-console<BR> 回车后应该看到下面表示启动成功: mysqld: ready for connections Version: '5.5.19-log' socket: '' port: 3306 接下来可以注册为win 服务 1.确认mysql 服务终止: bin\mysqladmin -u root shutdown
-
python实战项目scrapy管道学习爬取在行高手数据
目录 爬取目标站点分析 编码时间 爬取结果展示 爬取目标站点分析 本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据. 本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示. 对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕. class ZaihangItem(scrapy.Item): # define the fields for your item here like: name
-
讲解Python的Scrapy爬虫框架使用代理进行采集的方法
1.在Scrapy工程下新建"middlewares.py" # Importing base64 library because we'll need it ONLY in case if the proxy we are going to use requires authentication import base64 # Start your middleware class class ProxyMiddleware(object): # overwrite process
-
python爬虫框架Scrapy基本应用学习教程
在正式编写爬虫案例前,先对 scrapy 进行一下系统的学习. scrapy 安装与简单运行 使用命令 pip install scrapy 进行安装,成功之后,还需要随手收藏几个网址,以便于后续学习使用. scrapy 官网:https://scrapy.org scrapy 文档:https://doc.scrapy.org/en/latest/intro/tutorial.html scrapy 更新日志:https://docs.scrapy.org/en/latest/news.htm
-
Python爬虫框架Scrapy基本用法入门教程
本文实例讲述了Python爬虫框架Scrapy基本用法.分享给大家供大家参考,具体如下: Xpath <html> <head> <title>标题</title> </head> <body> <h2>二级标题</h2> <p>爬虫1</p> <p>爬虫2</p> </body> </html> 在上述html代码中,我要获取h2的内容,
-
Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例
本文实例讲述了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能.分享给大家供大家参考,具体如下: 一.背景: 小编在爬虫的时候肯定会遇到被封杀的情况,昨天爬了一个网站,刚开始是可以了,在settings的设置DEFAULT_REQUEST_HEADERS伪装自己是chrome浏览器,刚开始是可以的,紧接着就被对方服务器封杀了. 代理: 代理,代理,一直觉得爬去网页把爬去速度放慢一点就能基本避免被封杀,虽然可以使用selenium,但是这个坎必须
-
python爬虫框架scrapy实战之爬取京东商城进阶篇
前言 之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看看详细的介绍吧. 代码详解 1.首先应该构造请求,这里使用scrapy.Request,这个方法默认调用的是start_urls构造请求,如果要改变默认的请求,那么必须重载该方法,这个方法的返回值必须是一个可迭代的对象,一般是用yield返回. 代码如下: def start_requests(self): fo
-
Python爬虫框架Scrapy实例代码
目标任务:爬取腾讯社招信息,需要爬取的内容为:职位名称,职位的详情链接,职位类别,招聘人数,工作地点,发布时间. 一.创建Scrapy项目 scrapy startproject Tencent 命令执行后,会创建一个Tencent文件夹,结构如下 二.编写item文件,根据需要爬取的内容定义爬取字段 # -*- coding: utf-8 -*- import scrapy class TencentItem(scrapy.Item): # 职位名 positionname = scrapy.
-
Python爬虫框架Scrapy常用命令总结
本文实例讲述了Python爬虫框架Scrapy常用命令.分享给大家供大家参考,具体如下: 在Scrapy中,工具命令分为两种,一种为全局命令,一种为项目命令. 全局命令不需要依靠Scrapy项目就可以在全局中直接运行,而项目命令必须要在Scrapy项目中才可以运行 全局命令 全局命令有哪些呢,要想了解在Scrapy中有哪些全局命令,可以在不进入Scrapy项目所在目录的情况下,运行scrapy-h,如图所示: 可以看到,此时在可用命令在终端下展示出了常见的全局命令,分别为fetch.runspi
-
Python爬虫框架scrapy实现的文件下载功能示例
本文实例讲述了Python爬虫框架scrapy实现的文件下载功能.分享给大家供大家参考,具体如下: 我们在写普通脚本的时候,从一个网站拿到一个文件的下载url,然后下载,直接将数据写入文件或者保存下来,但是这个需要我们自己一点一点的写出来,而且反复利用率并不高,为了不重复造轮子,scrapy提供很流畅的下载文件方式,只需要随便写写便可用了. mat.py文件 # -*- coding: utf-8 -*- import scrapy from scrapy.linkextractor impor
-
python爬虫框架scrapy实现模拟登录操作示例
本文实例讲述了python爬虫框架scrapy实现模拟登录操作.分享给大家供大家参考,具体如下: 一.背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎,很多信息都是需要登录以后才能爬取,但是频繁登录后就会出现验证码(有些网站直接就让你输入验证码),这就坑了,毕竟运维同学很辛苦,该反的还得反,那我们怎么办呢?这不说验证码的事儿,你可以自己手动输入验
-
Python爬虫框架-scrapy的使用
Scrapy Scrapy是纯python实现的一个为了爬取网站数据.提取结构性数据而编写的应用框架. Scrapy使用了Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,并且包含了各种中间件接口,可以灵活的完成各种需求 1.安装 sudo pip3 install scrapy 2.认识scrapy框架 2.1 scrapy架构图 Scrapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递