Python爬取用户观影数据并分析用户与电影之间的隐藏信息!
一、前言

二、爬取观影数据
https://movie.douban.com/
在『豆瓣』平台爬取用户观影数据。
爬取用户列表
网页分析

为了获取用户,我选择了其中一部电影的影评,这样可以根据评论的用户去获取其用户名称(后面爬取用户观影记录只需要『用户名称』)。
https://movie.douban.com/subject/24733428/reviews?start=0
url中start参数是页数(page*20,每一页20条数据),因此start=0、20、40...,也就是20的倍数,通过改变start参数值就可以获取这4614条用户的名称。
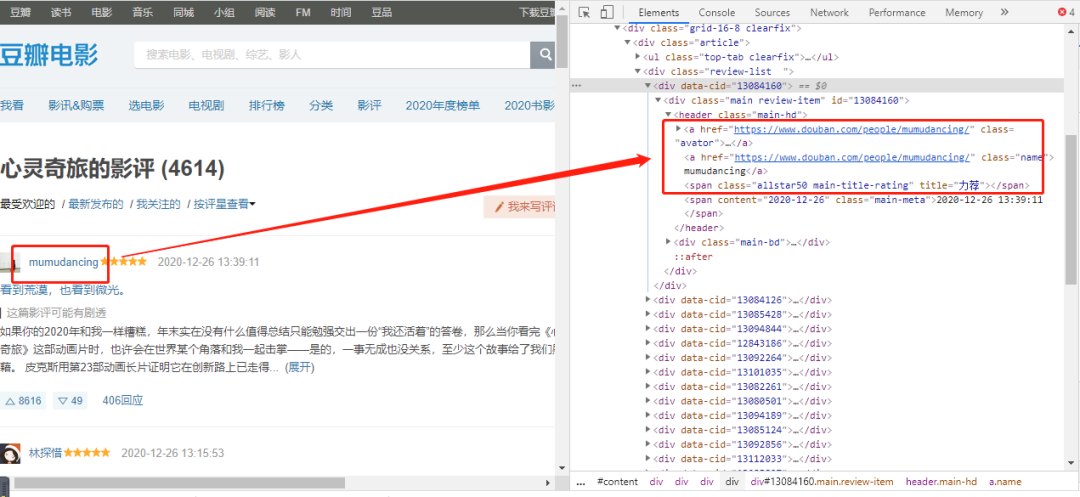
查看网页的标签,可以找到『用户名称』值对应的标签属性。
编程实现
i=0
url = "https://movie.douban.com/subject/24733428/reviews?start=" + str(i * 20)
r = requests.get(url, headers=headers)
r.encoding = 'utf8'
s = (r.content)
selector = etree.HTML(s)
for item in selector.xpath('//*[@class="review-list "]/div'):
userid = (item.xpath('.//*[@class="main-hd"]/a[2]/@href'))[0].replace("https://www.douban.com/people/","").replace("/", "")
username = (item.xpath('.//*[@class="main-hd"]/a[2]/text()'))[0]
print(userid)
print(username)
print("-----")

爬取用户的观影记录
上一步爬取到『用户名称』,接着爬取用户观影记录需要用到『用户名称』。
网页分析


#https://movie.douban.com/people/{用户名称}/collect?start=15&sort=time&rating=all&filter=all&mode=grid
https://movie.douban.com/people/mumudancing/collect?start=15&sort=time&rating=all&filter=all&mode=grid
通过改变『用户名称』,可以获取到不同用户的观影记录。
url中start参数是页数(page*15,每一页15条数据),因此start=0、15、30...,也就是15的倍数,通过改变start参数值就可以获取这1768条观影记录称。

查看网页的标签,可以找到『电影名』值对应的标签属性。
编程实现
url = "https://movie.douban.com/people/mumudancing/collect?start=15&sort=time&rating=all&filter=all&mode=grid"
r = requests.get(url, headers=headers)
r.encoding = 'utf8'
s = (r.content)
selector = etree.HTML(s)
for item in selector.xpath('//*[@class="grid-view"]/div[@class="item"]'):
text1 = item.xpath('.//*[@class="title"]/a/em/text()')
text2 = item.xpath('.//*[@class="title"]/a/text()')
text1 = (text1[0]).replace(" ", "")
text2 = (text2[1]).replace(" ", "").replace("\n", "")
print(text1+text1)
print("-----")

保存到excel
定义表头
# 初始化execl表
def initexcel(filename):
# 创建一个workbook 设置编码
workbook = xlwt.Workbook(encoding='utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('sheet1')
workbook.save(str(filename)+'.xls')
##写入表头
value1 = [["用户", "影评"]]
book_name_xls = str(filename)+'.xls'
write_excel_xls_append(book_name_xls, value1)
excel表有两个标题(用户, 影评)
写入excel
# 写入execl
def write_excel_xls_append(path, value):
index = len(value) # 获取需要写入数据的行数
workbook = xlrd.open_workbook(path) # 打开工作簿
sheets = workbook.sheet_names() # 获取工作簿中的所有表格
worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格
rows_old = worksheet.nrows # 获取表格中已存在的数据的行数
new_workbook = copy(workbook) # 将xlrd对象拷贝转化为xlwt对象
new_worksheet = new_workbook.get_sheet(0) # 获取转化后工作簿中的第一个表格
for i in range(0, index):
for j in range(0, len(value[i])):
new_worksheet.write(i+rows_old, j, value[i][j]) # 追加写入数据,注意是从i+rows_old行开始写入
new_workbook.save(path) # 保存工作簿
定义了写入excel函数,这样爬起每一页数据时候调用写入函数将数据保存到excel中。

最后采集了44130条数据(原本是4614个用户,每个用户大约有500~1000条数据,预计400万条数据)。但是为了演示分析过程,只爬取每一个用户的前30条观影记录(因为前30条是最新的)。
最后这44130条数据会在下面分享给大家。
三、数据分析挖掘
读取数据集
def read_excel():
# 打开workbook
data = xlrd.open_workbook('豆瓣.xls')
# 获取sheet页
table = data.sheet_by_name('sheet1')
# 已有内容的行数和列数
nrows = table.nrows
datalist=[]
for row in range(nrows):
temp_list = table.row_values(row)
if temp_list[0] != "用户" and temp_list[1] != "影评":
data = []
data.append([str(temp_list[0]), str(temp_list[1])])
datalist.append(data)
return datalist

从豆瓣.xls中读取全部数据放到datalist集合中。
分析1:电影观看次数排行
###分析1:电影观看次数排行
def analysis1():
dict ={}
###从excel读取数据
movie_data = read_excel()
for i in range(0, len(movie_data)):
key = str(movie_data[i][0][1])
try:
dict[key] = dict[key] +1
except:
dict[key]=1
###从小到大排序
dict = sorted(dict.items(), key=lambda kv: (kv[1], kv[0]))
name=[]
num=[]
for i in range(len(dict)-1,len(dict)-16,-1):
print(dict[i])
name.append(((dict[i][0]).split("/"))[0])
num.append(dict[i][1])
plt.figure(figsize=(16, 9))
plt.title('电影观看次数排行(高->低)')
plt.bar(name, num, facecolor='lightskyblue', edgecolor='white')
plt.savefig('电影观看次数排行.png')

分析由于用户信息来源于 『心灵奇旅』 评论,因此其用户观看量最大。最近的热播电影中,播放量排在第二的是 『送你一朵小红花』,信条和拆弹专家2也紧跟其后。
分析2:用户画像(用户观影相同率最高)
###分析2:用户画像(用户观影相同率最高)
def analysis2():
dict = {}
###从excel读取数据
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
#print(user)
#print(moive)
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
num_dict={}
# 待画像用户(取第一个)
flag_user=userlist[0]
movies = (dict[flag_user]).split(",")
for i in range(0,len(userlist)):
#判断是否是待画像用户
if flag_user != userlist[i]:
num_dict[userlist[i]]=0
#待画像用户的所有电影
for j in range(0,len(movies)):
#判断当前用户与待画像用户共同电影个数
if movies[j] in dict[userlist[i]]:
# 相同加1
num_dict[userlist[i]] = num_dict[userlist[i]]+1
###从小到大排序
num_dict = sorted(num_dict.items(), key=lambda kv: (kv[1], kv[0]))
#用户名称
username = []
#观看相同电影次数
num = []
for i in range(len(num_dict) - 1, len(num_dict) - 9, -1):
username.append(num_dict[i][0])
num.append(num_dict[i][1])
plt.figure(figsize=(25, 9))
plt.title('用户画像(用户观影相同率最高)')
plt.scatter(username, num, color='r')
plt.plot(username, num)
plt.savefig('用户画像(用户观影相同率最高).png')

分析
以用户 『mumudancing』 为例进行用户画像
1.从图中可以看出,与用户 『mumudancing』 观影相同率最高的是:“请带我回布拉格”,其次是“李校尉”。
2.用户:'绝命纸牌', '笨小孩', '私享史', '温衡', '沈唐', '修左',的观影相同率****相同。
分析3:用户之间进行电影推荐
###分析3:用户之间进行电影推荐(与其他用户同时被观看过)
def analysis3():
dict = {}
###从excel读取数据
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
#print(user)
#print(moive)
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
num_dict={}
# 待画像用户(取第2个)
flag_user=userlist[0]
print(flag_user)
movies = (dict[flag_user]).split(",")
for i in range(0,len(userlist)):
#判断是否是待画像用户
if flag_user != userlist[i]:
num_dict[userlist[i]]=0
#待画像用户的所有电影
for j in range(0,len(movies)):
#判断当前用户与待画像用户共同电影个数
if movies[j] in dict[userlist[i]]:
# 相同加1
num_dict[userlist[i]] = num_dict[userlist[i]]+1
###从小到大排序
num_dict = sorted(num_dict.items(), key=lambda kv: (kv[1], kv[0]))
# 去重(用户与观影率最高的用户两者之间重复的电影去掉)
user_movies = dict[flag_user]
new_movies = dict[num_dict[len(num_dict)-1][0]].split(",")
for i in range(0,len(new_movies)):
if new_movies[i] not in user_movies:
print("给用户("+str(flag_user)+")推荐电影:"+str(new_movies[i]))

分析
以用户 『mumudancing』 为例,对用户之间进行电影推荐
1.根据与用户 『mumudancing』 观影率最高的用户(A)进行进行关联,然后获取用户(A)的全部观影记录
2.将用户(A)的观影记录推荐给用户 『mumudancing』(去掉两者之间重复的电影)。
分析4:电影之间进行电影推荐
###分析4:电影之间进行电影推荐(与其他电影同时被观看过)
def analysis4():
dict = {}
###从excel读取数据
movie_data = read_excel()
userlist=[]
for i in range(0, len(movie_data)):
user = str(movie_data[i][0][0])
moive = (str(movie_data[i][0][1]).split("/"))[0]
try:
dict[user] = dict[user]+","+str(moive)
except:
dict[user] =str(moive)
userlist.append(user)
movie_list=[]
# 待获取推荐的电影
flag_movie = "送你一朵小红花"
for i in range(0,len(userlist)):
if flag_movie in dict[userlist[i]]:
moives = dict[userlist[i]].split(",")
for j in range(0,len(moives)):
if moives[j] != flag_movie:
movie_list.append(moives[j])
data_dict = {}
for key in movie_list:
data_dict[key] = data_dict.get(key, 0) + 1
###从小到大排序
data_dict = sorted(data_dict.items(), key=lambda kv: (kv[1], kv[0]))
for i in range(len(data_dict) - 1, len(data_dict) -16, -1):
print("根据电影"+str(flag_movie)+"]推荐:"+str(data_dict[i][0]))

分析
以电影 『送你一朵小红花』 为例,对电影之间进行电影推荐
1.获取观看过 『送你一朵小红花』 的所有用户,接着获取这些用户各自的观影记录。
2.将这些观影记录进行统计汇总(去掉“送你一朵小红花”),然后进行从高到低进行排序,最后可以获取到与电影 『送你一朵小红花』 关联度最高排序的集合。
3.将关联度最高的前15部电影给用户推荐。
四、总结
1.分析爬取豆瓣平台数据思路,并编程实现。
2.对爬取的数据进行分析(电影观看次数排行、用户画像、用户之间进行电影推荐、电影之间进行电影推荐)
到此这篇关于Python爬取用户观影数据并分析用户与电影之间的隐藏信息!的文章就介绍到这了,更多相关Python爬取数据并分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预
-
用Python 爬取猫眼电影数据分析《无名之辈》
前言 作者: 罗昭成 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef 获取猫眼接口数据 作为一个长期宅在家的程序员,对各种抓包简直是信手拈来.在 Chrome 中查看原代码的模式,可以很清晰地看到接口,接口地址即为:http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&o
-
详解python爬取弹幕与数据分析
很不幸的是,由于疫情的关系,原本线下的AWD改成线上CTF了.这就很难受了,毕竟AWD还是要比CTF难一些的,与人斗现在变成了与主办方斗. 虽然无奈归无奈,但是现在还是得打起精神去面对下一场比赛.这个开始也是线下的,决赛地点在南京,后来是由于疫情的关系也成了线上. 当然,比赛内容还是一如既往的得现学,内容是关于大数据的. 由于我们学校之前并没有开设过相关培训,所以也只能自己琢磨了. 好了,废话先不多说了,正文开始. 一.比赛介绍 大数据总体来说分为三个过程. 第一个过程是搭建hadoop环境.
-
Python数据分析之彩票的历史数据
一.需求介绍 该需求主要是分析彩票的历史数据 客户的需求是根据彩票的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票 对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5: 对于2.,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10. 然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按照这种方法,连续6次以及6次以上的购买彩票才能够命中一次奖
-
Python爬取用户观影数据并分析用户与电影之间的隐藏信息!
一.前言 二.爬取观影数据 https://movie.douban.com/ 在『豆瓣』平台爬取用户观影数据. 爬取用户列表 网页分析 为了获取用户,我选择了其中一部电影的影评,这样可以根据评论的用户去获取其用户名称(后面爬取用户观影记录只需要『用户名称』). https://movie.douban.com/subject/24733428/reviews?start=0 url中start参数是页数(page*20,每一页20条数据),因此start=0.20.40...,也就是20的倍数
-
如何用python爬取微博热搜数据并保存
主要用到requests和bf4两个库 将获得的信息保存在d://hotsearch.txt下 import requests; import bs4 mylist=[] r = requests.get(url='https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6',timeout=10) print(r.status_code) # 获取返回状态 r.encoding=r.apparent_encoding demo
-
Python爬取当网书籍数据并数据可视化展示
目录 一.开发环境 二.模块使用 三.爬虫代码实现步骤 1. 导入所需模块 2. 发送请求, 用python代码模拟浏览器发送请求 3. 解析数据, 提取我们想要数据内容 4. 多页爬取 5. 保存数据, 保存csv表格里面 四.数据可视化 1.导入所需模块 2.导入数据 3.可视化 一.开发环境 Python 3.8 Pycharm 2021.2 专业版 二.模块使用 csv 模块 把爬取下来的数据保存表格里面的 内置模块requests >>> pip install request
-
用python爬取今日说法每期数据
目录 实验目的 代码 实验结果 总结 实验目的 主要是获取2021年今日说法每期节目主要内容及时间今日说法的网址为:http://tv.cctv.com/lm/jrsf/index.shtml当时怎么写的思路有点不太记得了,先把代码贴上,后续有时间再补上. 代码 import xlwt import re import requests # url = "https://tv.cctv.com/lm/jrsf/index.shtml" def get_data(page): url =
-
python爬取抖音视频的实例分析
现在抖音的火爆程度,大家都是有目共睹的吧,之前小编在网络上发现好玩的事情,就是去爬取一些网站,因此,也考虑能否进行抖音上的破案去,在实际操作以后,真的实现出来了,利用自动化工具,就可以轻松实现了,后有小伙伴提出把appium去掉瘦身之后也是可以实现的,那么看下详细操作内容吧. 1.mitmproxy/mitmdump抓包 import requests path = 'D:/video/' num = 1788 def response(flow): global num target_urls
-
Python爬取智联招聘数据分析师岗位相关信息的方法
进入智联招聘官网,在搜索界面输入'数据分析师',界面跳转,按F12查看网页源码,点击network 选中XHR,然后刷新网页 可以看到一些Ajax请求, 找到画红线的XHR文件,点击可以看到网页的一些信息 在Header中有Request URL,我们需要通过找寻Request URL的特点来构造这个请求网址, 点击Preview,可以看到我们所需要的信息就存在result中,这信息基本是json格式,有些是列表: 下面我们通过Python爬虫来爬取上面的信息: 代码如下: import req
-
基于Python爬取fofa网页端数据过程解析
FOFA-网络空间安全搜索引擎是网络空间资产检索系统(FOFA)是世界上数据覆盖更完整的IT设备搜索引擎,拥有全球联网IT设备更全的DNA信息.探索全球互联网的资产信息,进行资产及漏洞影响范围分析.应用分布统计.应用流行度态势感知等. 安装环境: pip install requests pip install lxml pip install fire 使用命令: python fofa.py -s=title="你的关键字" -o="结果输出文件" -c=&qu
-
通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
在学习python的时候,一定会遇到网站内容是通过 ajax动态请求.异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果在python中爬取ajax动态生成的数据. 至于读取静态网页内容的方式,有兴趣的可以查看本文内容. 这里我们以爬取淘宝评论为例子讲解一下如何去做到的. 这里主要分为了四步: 一 获取淘宝评论时,ajax请求链接(url) 二 获取该ajax请求返回的json数据 三 使用python解析json数据
-
使用python爬取B站千万级数据
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象.直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定.它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务.它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句. Python支持命令式程序设计.面向对象程序设计.函数式编程.面向切面编程.泛型编程多种编程范式.与Scheme.Ruby.Perl.Tcl等动态语言一样,Python具备垃圾回收
-
python爬取拉勾网职位数据的方法
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站--拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助. 完成的效果 爬取数据只是第一步,怎样使用和分析数据也是一大重点,当然这不是本次博客的目的,由于本次只是一个上手的爬虫程序,所以我们的最终目的只是爬取到拉钩网的职位信息,然后保存到Mysql数据库中.最后中的效果示意图如下: 控制台输入 数据库显示 准备工作 首先需要安装python,这个网上已经有很多的