python pandas分割DataFrame中的字符串及元组的方法实现
目录
- 1.使用str.split()方法
- 2.使用join()与split()方法结合
- 3.使用apply方法分割元组
1.使用str.split()方法
可以使用pandas 内置的 str.split() 方法实现分割字符串类型的数据,并将分割结果写入DataFrame中,以表格形式呈现。
语法:
Series.str.split(pat=None, n=-1, expand=False)
其中,pat是字符串或正则表达式,
n是一个整数数字,默认为-1。为0或-1时即为最大次数的分割。其他数值因数值而定。
expand为布尔类型,表示分割后是否转换为DataFrame。默认为False表示不转换。
首先准备一组DataFrame数据:
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
address = ['重庆 重庆市 南岸区 ',
'江苏省 苏州市 吴江区 吴江经济技术开发区亨通路',
'江苏省 苏州市 园区 苏州市工业园区唯亭镇阳澄湖大道维纳阳光花园',
'重庆 重庆市 南岸区 长生桥镇茶园新区长电路',
'安徽省 滁州市 明光市 三界镇中心街10001号',
'山东省 潍坊市 寿光市 圣城街道潍坊科技学院',
'吉林省 长春市 二道区 东盛街道彩虹风景',
'福建省 厦门市 湖里区 江头街道厦门市湖里区祥店福满园小区',
'山西省 吕梁市 离石区 滨河街道山西省吕梁市离石区后瓦师巷',
'河南省 濮阳市 华龙区 中原路街道中原路与107国道交叉口东',
'广东省 深圳市 宝安区 松岗街道松岗镇潭头第二工业区',
'河北省 石家庄市 辛集市 辛集镇辛集市新皮革城7期125楼',
'广东省 深圳市 宝安区 松岗街道松岗镇潭头第二工业区',
'贵州省 贵阳市 花溪区 党武镇师范大学师大超市',
'广东省 深圳市 福田区 沙头街道上沙龙秋村五十巷',
'福建省 福州市 闽侯县 上街镇福州闽侯上街国宾大道',
'湖北省 鄂州市 鄂城区 西山街道江碧路和馨居',
'上海 上海市 松江区',
'山东省 青岛市 市北区',
'山西省 晋中市 灵石县',
'浙江省 杭州市 余杭区']
df = pd.DataFrame()
df['address'] = address
print(df)
原数据示例如下:

将address分割成不同的地理级别,结果生成一个DataFrame对象:
print("=======================================================================")
df1 = df['address'].str.split(' ', expand=True)
print(df1)
结果如下:
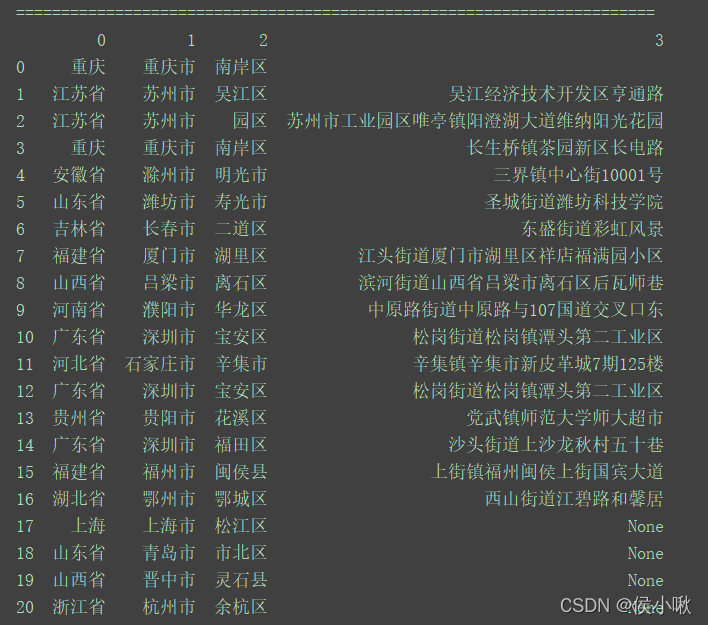
最后将结果放入原DataFrame中。
df['省'] = series[0] df['市'] = series[1] df['区'] = series[2] df = df[['省', '市', '区']] print(df)

2.使用join()与split()方法结合
import pandas as pd
pd.set_option('display.unicode.east_asian_width', True)
address = ['重庆 重庆市 南岸区 ',
'江苏省 苏州市 吴江区 吴江经济技术开发区亨通路',
'江苏省 苏州市 园区 苏州市工业园区唯亭镇阳澄湖大道维纳阳光花园',
'重庆 重庆市 南岸区 长生桥镇茶园新区长电路',
'安徽省 滁州市 明光市 三界镇中心街10001号',
'山东省 潍坊市 寿光市 圣城街道潍坊科技学院',
'吉林省 长春市 二道区 东盛街道彩虹风景',
'福建省 厦门市 湖里区 江头街道厦门市湖里区祥店福满园小区',
'山西省 吕梁市 离石区 滨河街道山西省吕梁市离石区后瓦师巷',
'河南省 濮阳市 华龙区 中原路街道中原路与107国道交叉口东',
'广东省 深圳市 宝安区 松岗街道松岗镇潭头第二工业区',
'河北省 石家庄市 辛集市 辛集镇辛集市新皮革城7期125楼',
'广东省 深圳市 宝安区 松岗街道松岗镇潭头第二工业区',
'贵州省 贵阳市 花溪区 党武镇师范大学师大超市',
'广东省 深圳市 福田区 沙头街道上沙龙秋村五十巷',
'福建省 福州市 闽侯县 上街镇福州闽侯上街国宾大道',
'湖北省 鄂州市 鄂城区 西山街道江碧路和馨居',
'上海 上海市 松江区',
'山东省 青岛市 市北区',
'山西省 晋中市 灵石县',
'浙江省 杭州市 余杭区']
df = pd.DataFrame()
df['address'] = address
df = df.join(df['address'].str.split(' ', expand=True))
print(df)
运行结果同上。
3. 使用apply方法分割元组
使用apply方法,将某个元素类型为元组的列,将其元组中的元素拆分为不同的列。
import pandas as pd
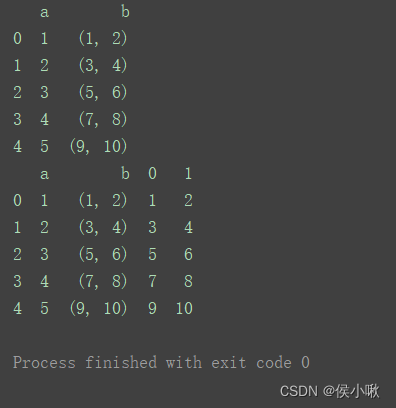
df = pd.DataFrame({'a': [1, 2, 3, 4, 5], 'b': [(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]})
print(df)
df[['b1', 'b2']] = df['b'].apply(pd.Series)
print(df)

或者也可以这样写:
import pandas as pd
df = pd.DataFrame({'a': [1, 2, 3, 4, 5], 'b': [(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]})
print(df)
df = df.join(df['b'].apply(pd.Series))
print(df)
参考资源: python数据分析从入门到精通 明日科技编著 清华大学出版社
到此这篇关于python pandas分割DataFrame中的字符串及元组的方法实现的文章就介绍到这了,更多相关python pandas分割DataFrame字符串及元组内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas中DataFrame的分组/分割/合并的实现
学习<Python3爬虫.数据清洗与可视化实战>时自己的一些实践. DataFrame分组操作 注意分组后得到的就是Series对象了,而不再是DataFrame对象. import pandas as pd # 还是读取这份文件 df = pd.read_csv("E:/Data/practice/taobao_data.csv", delimiter=',', encoding='utf-8', header=0) # 计算'成交量'按'位置'分组的平均值 groupe
-

python pandas分割DataFrame中的字符串及元组的方法实现
目录 1.使用str.split()方法 2.使用join()与split()方法结合 3.使用apply方法分割元组 1.使用str.split()方法 可以使用pandas 内置的 str.split() 方法实现分割字符串类型的数据,并将分割结果写入DataFrame中,以表格形式呈现. 语法: Series.str.split(pat=None, n=-1, expand=False) 其中,pat是字符串或正则表达式,n是一个整数数字,默认为-1.为0或-1时即为最大次数的分割.其他数
-
python 怎样将dataframe中的字符串日期转化为日期的方法
方法一:也是最简单的 直接使用pd.to_datetime函数实现 data['交易时间'] = pd.to_datetime(data['交易时间']) 方法二: 源自利用python进行数据分析P304 使用python的datetime包中的 strptime函数,datetime.strptime(value,'%Y/%M/%D') strftime函数,datetime.strftime('%Y/%M/%D') 注意使用datetime包中后面的字符串匹配需要和原字符串的格式相同,才能
-
Pandas过滤dataframe中包含特定字符串的数据方法
假如有一列全是字符串的dataframe,希望提取包含特定字符的所有数据,该如何提取呢? 因为之前尝试使用filter,发现行不通,最终找到这个行得通的方法. 举例说明: 我希望提取所有包含'Mr.'的人名 1.首先将他们进行字符串化,并得到其对应的布尔值: >>> bool = df.str.contains('Mr\.') #不要忘记正则表达式的写法,'.'在里面要用'\.'表示 >>> print('bool : \n', bool) 2.通过dataframe的
-
python Pandas之DataFrame索引及选取数据
目录 1.索引是什么 1.1 认识索引 1.2 自定义索引 2. 索引的简单使用 2.1 列索引 2.2 行索引 2.2.1 使用[ ] 2.2.2 使用.loc()和.iloc() 1.索引是什么 1.1 认识索引 先创建一个简单的DataFrame. myList = [['a', 10, 1.1], ['b', 20, 2.2], ['c', 30, 3.3], ['d', 40, 4.4]] df1 = pd.DataFrame(data = myList) print(df1) ---
-
对pandas将dataframe中某列按照条件赋值的实例讲解
在数据处理过程中,经常会出现对某列批量做某些操作,比如dataframe df要对列名为"values"做大于等于30设置为1,小于30设置为0操作,可以这样使用dataframe的apply函数来实现, 具体实现代码如下: def fun(x): if x >= 30: return 1 else: return 0 values= feature['values'].apply(lambda x: fun(x)) 具体的逻辑可以修改fun函数来实现,但是按照某些条件选择列不是
-
Python中修改字符串的四种方法
在Python中,字符串是不可变类型,即无法直接修改字符串的某一位字符. 因此改变一个字符串的元素需要新建一个新的字符串. 常见的修改方法有以下4种. 方法1:将字符串转换成列表后修改值,然后用join组成新字符串 >>> s='abcdef' #原字符串 >>> s1=list(s) #将字符串转换为列表 >>> s1 ['a', 'b', 'c', 'd', 'e', 'f'] #列表的每一个元素为一个字符 >>> s1[4]='
-
解决python pandas读取excel中多个不同sheet表格存在的问题
摘要:不同方法读取excel中的多个不同sheet表格性能比较 # 方法1 def read_excel(path): df=pd.read_excel(path,None) print(df.keys()) # for k,v in df.items(): # print(k) # print(v) # print(type(v)) return df # 方法2 def read_excel1(path): data_xls = pd.ExcelFile(path) print(data_x
-
去除python中的字符串空格的简单方法
python编程中,我们在修改代码,遇到空格很多的情况下,我们要删除空格.本文小编整理了三种字符串去除空格的方法: 方法一:使用字符串函数replace,去除全部空格. 实例: >>> a = " a b c " >>> a.replace(" ", "") 'abc' 方法二:使用字符串函数split,去除字符串开头或者结尾的空格. 实例: >>> a = ''.join(a.split()
-
Pandas检查dataFrame中的NaN实现
目录 检查Pandas DataFrame中的NaN值 方法1:使用isnull().values.any()方法 方法2:使用isnull().sum()方法 方法3:使用isnull().sum().any()方法 方法4:使用isnull().sum().sum()方法 参考 NaN代表Not A Number,是表示数据中缺失值的常用方法之一.它是一种特殊的浮点值,不能转换为浮点数以外的任何其他类型. NaN值是数据分析中的主要问题之一,为了得到理想的结果,对NaN进行处理是非常必要的.
-
python pandas消除空值和空格以及 Nan数据替换方法
在人工采集数据时,经常有可能把空值和空格混在一起,一般也注意不到在本来为空的单元格里加入了空格.这就给做数据处理的人带来了麻烦,因为空值和空格都是代表的无数据,而pandas中Series的方法notnull()会把有空格的数据也纳入进来,这样就不能完整地得到我们想要的数据了,这里给出一个简单的方法处理该问题. 方法1: 既然我们认为空值和空格都代表无数据,那么可以先得到这两种情况下的布尔数组. 这里,我们的DataFrame类型的数据集为df,其中有一个变量VIN,那么取得空值和空格的布尔数组