Python利用selenium建立代理ip池访问网站的全过程
目录
- 一、使用selenium前?
- 1.安装selenium
- 2.安装浏览器驱动
- 3.配置环境
- 二、使用selenium
- 1.引入库
- 2.完整代码
- 总结
一、使用selenium前?
1.安装selenium
pip install Selenium
2.安装浏览器驱动
Chrome驱动文件下载:点击下载
3.配置环境
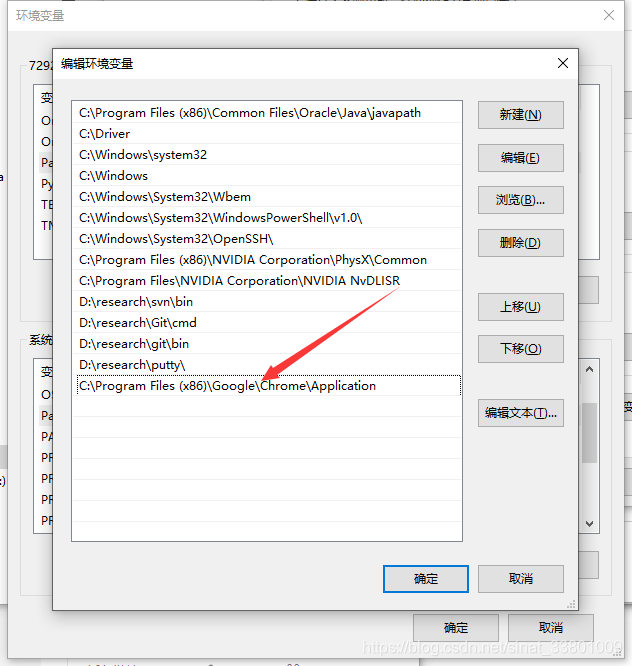
1.将下载文件放进C:\Program Files (x86)\Google\Chrome\Application下就可以

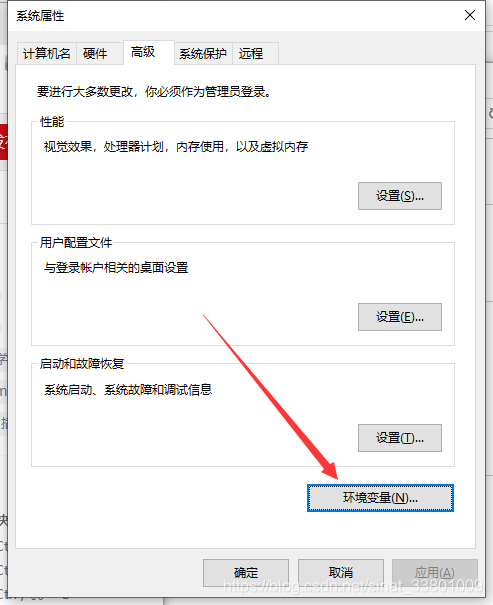
2.然后配置下系统变量:我的电脑–>属性–>系统设置–>高级–>环境变量–>系统变量–>Path,将“C:\Program Files (x86)\Google\Chrome\Application”目录添加到Path的值中。

注:之后如果代码不能调起浏览器,重启电脑,再运行!!!
二、使用selenium
1.引入库
代码如下(示例):
from selenium import webdriver from selenium.webdriver.chrome.options import Options
2.完整代码
如果有多个代理ip可循环使用,防止被禁几率
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
#以下ip使用自己可使用的代理IP
proxy_arr = [
'--proxy-server=http://171.35.141.103:9999',
'--proxy-server=http://36.248.132.196:9999',
# '--proxy-server=http://125.46.0.62:53281',
'--proxy-server=http://219.239.142.253:3128',
'--proxy-server=http://119.57.156.90:53281',
'--proxy-server=http://60.205.132.71:80',
'--proxy-server=https://139.217.110.76:3128',
'--proxy-server=https://116.196.85.150:3128'
]
chrome_options = Options()
proxy = random.choice(proxy_arr) # 随机选择一个代理
print(proxy) #如果某个代理访问失败,可从proxy_arr中去除
chrome_options.add_argument(proxy) # 添加代理
browser = webdriver.Chrome(options=chrome_options)
browser.get("http://httpbin.org/ip")
print(browser.page_source)
代码如下(示例):

总结
到此这篇关于Python利用selenium建立代理ip池访问网站的文章就介绍到这了,更多相关Python selenium代理ip池访问网站内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
selenium+python设置爬虫代理IP的方法
1. 背景 在使用selenium浏览器渲染技术,爬取网站信息时,一般来说,速度是很慢的.而且一般需要用到这种技术爬取的网站,反爬技术都比较厉害,对IP的访问频率应该有相当的限制.所以,如果想提升selenium抓取数据的速度,可以从两个方面出发: 第一,提高抓取频率,出现验证信息时进行破解,一般是验证码或者用户登录. 第二,使用多线程 + 代理IP, 这种方式,需要电脑有足够的内存和充足稳定的代理IP . 2. 为chrome设置代理IP from selenium import webdri
-

Python利用selenium建立代理ip池访问网站的全过程
目录 一.使用selenium前? 1.安装selenium 2.安装浏览器驱动 3.配置环境 二.使用selenium 1.引入库 2.完整代码 总结 一.使用selenium前? 1.安装selenium pip install Selenium 2.安装浏览器驱动 Chrome驱动文件下载:点击下载 3.配置环境 1.将下载文件放进C:\Program Files (x86)\Google\Chrome\Application下就可以 2.然后配置下系统变量:我的电脑–>属性–>系统设置
-
Python爬虫实现搭建代理ip池
目录 前言 一.User-Agent 二.发送请求 三.解析数据 四.构建ip代理池,检测ip是否可用 五.完整代码 总结 前言 在使用爬虫的时候,很多网站都有一定的反爬措施,甚至在爬取大量的数据或者频繁地访问该网站多次时还可能面临ip被禁,所以这个时候我们通常就可以找一些代理ip来继续爬虫测试.下面就开始来简单地介绍一下爬取免费的代理ip来搭建自己的代理ip池: 本次爬取免费ip代理的网址:http://www.ip3366.net/free/ 提示:以下是本篇文章正文内容,下面案例可供参考
-
Python爬虫代理IP池实现方法
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源出来.不过呢,闲暇时间手痒,所以就想利用一些免费的资源搞一个简单的代理池服务. 1.问题 代理IP从何而来? 刚自学爬虫的时候没有代理IP就去西刺.快代理之类有免费代理的网站去爬,还是有个别代理能用.当然,如果你有更好的代理接口也可以自己接入. 免费代理的采集也很简单,无非就是:访问页面页面 -> 正则/xpath提
-
Python搭建代理IP池实现检测IP的方法
在获取 IP 时,已经成功将各个网站的代理 IP 获取下来了,然后就需要一个检测模块来对所有的代理进行一轮轮的检测,检测可用就设置为满分,不可用分数就减 1,这样就可以实时改变每个代理的可用情况,在获取有效 IP 的时候只需要获取分数高的 IP 代码地址:https://github.com/Stevengz/Proxy_pool 另外三篇: Python搭建代理IP池(一)- 获取 IP Python搭建代理IP池(二)- 存储 IP Python搭建代理IP池(四)- 接口设置与整体调度 由
-
Python搭建代理IP池实现接口设置与整体调度
接口模块需要用 API 来提供对外服务的接口,当然也可以直接连数据库来取,但是这样就需要知道数据库的连接信息,不太安全,而且需要配置连接,所以一个比较安全和方便的方式就是提供一个 Web API 接口,通过访问接口即可拿到可用代理 代码地址:https://github.com/Stevengz/Proxy_pool 另外三篇: Python搭建代理IP池(一)- 获取 IP Python搭建代理IP池(二)- 存储 IP Python搭建代理IP池(三)- 检测 IP 添加设置 添加模块开关变
-
Python搭建代理IP池实现获取IP的方法
使用爬虫时,大部分网站都有一定的反爬措施,有些网站会限制每个 IP 的访问速度或访问次数,超出了它的限制你的 IP 就会被封掉.对于访问速度的处理比较简单,只要间隔一段时间爬取一次就行了,避免频繁访问:而对于访问次数,就需要使用代理 IP 来帮忙了,使用多个代理 IP 轮换着去访问目标网址可以有效地解决问题. 目前网上有很多的代理服务网站提供代理服务,也提供一些免费的代理,但可用性较差,如果需求较高可以购买付费代理,可用性较好. 因此我们可以自己构建代理池,从各种代理服务网站中获取代理 IP,并
-
Python搭建代理IP池实现存储IP的方法
上一文写了如何从代理服务网站提取 IP,本文就讲解如何存储 IP,毕竟代理池还是要有一定量的 IP 数量才行.存储的方式有很多,直接一点的可以放在一个文本文件中,但操作起来不太灵活,而我选择的是 MySQL 数据库,因为数据库便于管理而且功能强大,当然你还可以选择其他数据库,比如 MongoDB.Redis 等. 代码地址:https://github.com/Stevengz/Proxy_pool 另外三篇: Python搭建代理IP池(一)- 获取 IP Python搭建代理IP池(三)-
-
python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检测是否可用,可用保存,通过函数get_proxies可以获得ip,如:{'HTTPS': '106.12.7.54:8118'} 下面放上源代码,并详细注释: import requests from lxml import etree from requests.packages import u
-
Python实现爬虫设置代理IP和伪装成浏览器的方法分享
1.python爬虫浏览器伪装 #导入urllib.request模块 import urllib.request #设置请求头 headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0") #创建一个opener opene
-
Python爬虫抓取代理IP并检验可用性的实例
经常写爬虫,难免会遇到ip被目标网站屏蔽的情况,银次一个ip肯定不够用,作为节约的程序猿,能不花钱就不花钱,那就自己去找吧,这次就写了下抓取 西刺代理上的ip,但是这个网站也反爬!!! 至于如何应对,我觉得可以通过增加延时试试,可能是我抓取的太频繁了,所以被封IP了. 但是,还是可以去IP巴士试试的,条条大路通罗马嘛,不能吊死在一棵树上. 不废话,上代码. #!/usr/bin/env python # -*- coding:utf8 -*- import urllib2 import time