python文件排序的方法总结
在python环境中提供两种排序方案:用库函数sorted()对字符串排序,它的对象是字符;用函数sort()对数字排序,它的对象是数字,如果读取文件的话,需要进行处理(把文件后缀名‘屏蔽')。
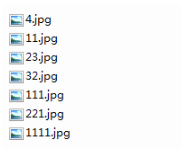
(1)首先:我测试的文件夹是/img/,里面的文件都是图片,如下图所示:
(2)测试库函数sorted(),直接贴出代码:
import numpy as np import os img_path='./img/' img_list=sorted(os.listdir(img_path))#文件名按字母排序 img_nums=len(img_list) for i in range(img_nums): img_name=img_path+img_list[i] print(img_name)
运行效果如下:
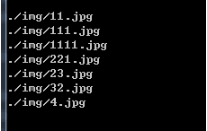
从图片可以清晰的看出,文件名是按字符排序的。
(3)测试函数sort(),代码:
import numpy as np import os img_path='./img/' img_list=os.listdir(img_path) img_list.sort() img_list.sort(key = lambda x: int(x[:-4])) ##文件名按数字排序 img_nums=len(img_list) for i in range(img_nums): img_name=img_path+img_list[i] print(img_name)
运行效果如下:
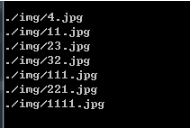
可以看出,文件名是按数字排序的;顺便提下,sort函数中用到了匿名函数(key = lambda x:int(x[:-4])),其作用是将后缀名'.jpg'“屏蔽”(因为‘.jpg'是4个字符,所以[:-4]的含义是从文件名开始到倒数第四个字符为止),具体看python的匿名函数和数组取值方式。
实例扩展:
import gzip
import os
from multiprocessing import Process, Queue, Pipe, current_process, freeze_support
from datetime import datetime
def sort_worker(input,output):
while True:
lines = input.get().splitlines()
element_set = {}
for line in lines:
if line.strip() == 'STOP':
return
try:
element = line.split(' ')[0]
if not element_set.get(element): element_set[element] = ''
except:
pass
sorted_element = sorted(element_set)
#print sorted_element
output.put('\n'.join(sorted_element))
def write_worker(input, pre):
os.system('mkdir %s'%pre)
i = 0
while True:
content = input.get()
if content.strip() == 'STOP':
return
write_sorted_bulk(content, '%s/%s'%(pre, i))
i += 1
def write_sorted_bulk(content, filename):
f = file(filename, 'w')
f.write(content)
f.close()
def split_sort_file(filename, num_sort = 3, buf_size = 65536*64*4):
t = datetime.now()
pre, ext = os.path.splitext(filename)
if ext == '.gz':
file_file = gzip.open(filename, 'rb')
else:
file_file = open(filename)
bulk_queue = Queue(10)
sorted_queue = Queue(10)
NUM_SORT = num_sort
sort_worker_pool = []
for i in range(NUM_SORT):
sort_worker_pool.append( Process(target=sort_worker, args=(bulk_queue, sorted_queue)) )
sort_worker_pool[i].start()
NUM_WRITE = 1
write_worker_pool = []
for i in range(NUM_WRITE):
write_worker_pool.append( Process(target=write_worker, args=(sorted_queue, pre)) )
write_worker_pool[i].start()
buf = file_file.read(buf_size)
sorted_count = 0
while len(buf):
end_line = buf.rfind('\n')
#print buf[:end_line+1]
bulk_queue.put(buf[:end_line+1])
sorted_count += 1
if end_line != -1:
buf = buf[end_line+1:] + file_file.read(buf_size)
else:
buf = file_file.read(buf_size)
for i in range(NUM_SORT):
bulk_queue.put('STOP')
for i in range(NUM_SORT):
sort_worker_pool[i].join()
for i in range(NUM_WRITE):
sorted_queue.put('STOP')
for i in range(NUM_WRITE):
write_worker_pool[i].join()
print 'elasped ', datetime.now() - t
return sorted_count
from heapq import heappush, heappop
from datetime import datetime
from multiprocessing import Process, Queue, Pipe, current_process, freeze_support
import os
class file_heap:
def __init__(self, dir, idx = 0, count = 1):
files = os.listdir(dir)
self.heap = []
self.files = {}
self.bulks = {}
self.pre_element = None
for i in range(len(files)):
file = files[i]
if hash(file) % count != idx: continue
input = open(os.path.join(dir, file))
self.files[i] = input
self.bulks[i] = ''
heappush(self.heap, (self.get_next_element_buffered(i), i))
def get_next_element_buffered(self, i):
if len(self.bulks[i]) < 256:
if self.files[i] is not None:
buf = self.files[i].read(65536)
if buf:
self.bulks[i] += buf
else:
self.files[i].close()
self.files[i] = None
end_line = self.bulks[i].find('\n')
if end_line == -1:
end_line = len(self.bulks[i])
element = self.bulks[i][:end_line]
self.bulks[i] = self.bulks[i][end_line+1:]
return element
def poppush_uniq(self):
while True:
element = self.poppush()
if element is None:
return None
if element != self.pre_element:
self.pre_element = element
return element
def poppush(self):
try:
element, index = heappop(self.heap)
except IndexError:
return None
new_element = self.get_next_element_buffered(index)
if new_element:
heappush(self.heap, (new_element, index))
return element
def heappoppush(dir, queue, idx = 0, count = 1):
heap = file_heap(dir, idx, count)
while True:
d = heap.poppush_uniq()
queue.put(d)
if d is None: return
def heappoppush2(dir, queue, count = 1):
heap = []
procs = []
queues = []
pre_element = None
for i in range(count):
q = Queue(1024)
q_buf = queue_buffer(q)
queues.append(q_buf)
p = Process(target=heappoppush, args=(dir, q_buf, i, count))
procs.append(p)
p.start()
queues = tuple(queues)
for i in range(count):
heappush(heap, (queues[i].get(), i))
while True:
try:
d, i= heappop(heap)
except IndexError:
queue.put(None)
for p in procs:
p.join()
return
else:
if d is not None:
heappush(heap,(queues[i].get(), i))
if d != pre_element:
pre_element = d
queue.put(d)
def merge_file(dir):
heap = file_heap( dir )
os.system('rm -f '+dir+'.merge')
fmerge = open(dir+'.merge', 'a')
element = heap.poppush_uniq()
fmerge.write(element+'\n')
while element is not None:
element = heap.poppush_uniq()
fmerge.write(element+'\n')
class queue_buffer:
def __init__(self, queue):
self.q = queue
self.rbuf = []
self.wbuf = []
def get(self):
if len(self.rbuf) == 0:
self.rbuf = self.q.get()
r = self.rbuf[0]
del self.rbuf[0]
return r
def put(self, d):
self.wbuf.append(d)
if d is None or len(self.wbuf) > 1024:
self.q.put(self.wbuf)
self.wbuf = []
def diff_file(file_old, file_new, file_diff, buf = 268435456):
print 'buffer size', buf
from file_split import split_sort_file
os.system('rm -rf '+ os.path.splitext(file_old)[0] )
os.system('rm -rf '+ os.path.splitext(file_new)[0] )
t = datetime.now()
split_sort_file(file_old,5,buf)
split_sort_file(file_new,5,buf)
print 'split elasped ', datetime.now() - t
os.system('cat %s/* | wc -l'%os.path.splitext(file_old)[0])
os.system('cat %s/* | wc -l'%os.path.splitext(file_new)[0])
os.system('rm -f '+file_diff)
t = datetime.now()
zdiff = open(file_diff, 'a')
old_q = Queue(1024)
new_q = Queue(1024)
old_queue = queue_buffer(old_q)
new_queue = queue_buffer(new_q)
h1 = Process(target=heappoppush2, args=(os.path.splitext(file_old)[0], old_queue, 3))
h2 = Process(target=heappoppush2, args=(os.path.splitext(file_new)[0], new_queue, 3))
h1.start(), h2.start()
old = old_queue.get()
new = new_queue.get()
old_count, new_count = 0, 0
while old is not None or new is not None:
if old > new or old is None:
zdiff.write('< '+new+'\n')
new = new_queue.get()
new_count +=1
elif old < new or new is None:
zdiff.write('> '+old+'\n')
old = old_queue.get()
old_count +=1
else:
old = old_queue.get()
new = new_queue.get()
print 'new_count:', new_count
print 'old_count:', old_count
print 'diff elasped ', datetime.now() - t
h1.join(), h2.join()
到此这篇关于python文件排序的方法总结的文章就介绍到这了,更多相关python文件排序都有哪些方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python实现大文件排序的方法
本文实例讲述了Python实现大文件排序的方法.分享给大家供大家参考.具体实现方法如下: import gzip import os from multiprocessing import Process, Queue, Pipe, current_process, freeze_support from datetime import datetime def sort_worker(input,output): while True: lines = input.get().splitlin
-
python 实现对文件夹内的文件排序编号
使用时,需更改rootdir, 即文件保存的路径,以及要保存的格式,例如'.jpg' 如果排序前后文件格式一样,建议先随便换个格式,然后再换回来,也就是程序运行两次,第一次随便换个格式,第二次换成想要的格式. #!usr/bin/env python import os import os.path rootdir = "C:\\Users\\IronMan\\Desktop\\launch\\" files = os.listdir(rootdir) b=0 for name in
-
python文件排序的方法总结
在python环境中提供两种排序方案:用库函数sorted()对字符串排序,它的对象是字符:用函数sort()对数字排序,它的对象是数字,如果读取文件的话,需要进行处理(把文件后缀名'屏蔽'). (1)首先:我测试的文件夹是/img/,里面的文件都是图片,如下图所示: (2)测试库函数sorted(),直接贴出代码: import numpy as np import os img_path='./img/' img_list=sorted(os.listdir(img_path))#文
-
Android编程实现对文件夹里文件排序的方法
本文实例讲述了Android编程实现对文件夹里文件排序的方法.分享给大家供大家参考,具体如下: private int mFileSize = 0; private List<String> mPathString = new ArrayList<String>(); private boolean sortFolder(String path) { if (path == null || StringUtil.isEmpty(path)) return false; File[]
-

Python文件操作的方法
目录 1.文件的概念 1.1文件的概念和作用 1.2文件的存储方式 2.文件的基本操作 2.1操作文件的套路 2.2操作文件的函数/方法 2.3read方法--读取文件 2.4打开文件的方式 2.5按行读取文件内容 2.6文件读写案例--复制文件 小文件复制 大文件复制 2.7文件读写中的函数 3.文件/目录的常用管理操作 4.文本文件的编码方式 5.拓展:eval函数 目标: 文件的概念 文件的基本操作 文件/文件夹的常用操作 文本文件的编码方式 1.文件的概念 1.1文件的概念和作用 计算机
-
python字典排序的方法
python字典怎么排序? 定义一个字典类型 mydict = {2: '小路', 3: '黎明', 1: '郭富城', 4:'周董'} 可分别打印 key和value 看一下数据 按KEY排序,使用了 lambda和 reverse= False(正序) key和value都输出 reverse= True(逆序) 按value排序,汉字次序不是按拼音输出 sorted并不改变字典本身的数据次序. 输出后为列表和元组 可以 A = sorted(mydict.items(),key = lam
-
python字典排序实例详解
本文实例分析了python字典排序的方法.分享给大家供大家参考.具体如下: 1. 准备知识: 在python里,字典dictionary是内置的数据类型,是个无序的存储结构,每一元素是key-value对: 如:dict = {'username':'password','database':'master'},其中'username'和'database'是key,而'password'和'master'是value,可以通过d[key]获得对应值value的引用,但是不能通过value得到k
-
Python编程对列表中字典元素进行排序的方法详解
本文实例讲述了Python编程对列表中字典元素进行排序的方法.分享给大家供大家参考,具体如下: 内容目录: 1. 问题起源 2. 对列表中的字典元素排序 3. 对json进行比较(忽略列表中字典的顺序) 一.问题起源 json对象a,b a = '{"ROAD": [{"id": 123}, {"name": "no1"}]}' b = '{"ROAD": [{"name": "
-
Python使用sorted排序的方法小结
本文实例讲述了Python使用sorted排序的方法.分享给大家供大家参考,具体如下: # 例1. 按照元素出现的次数来排序 seq = [2,4,3,1,2,2,3] # 按次数排序 seq2 = sorted(seq, key=lambda x:seq.count(x)) print(seq2) # [4, 1, 3, 3, 2, 2, 2] # 改进:第一优先按次数,第二优先按值 seq3 = sorted(seq, key=lambda x:(seq.count(x), x)) prin
-
php实现有序数组打印或排序的方法【附Python、C及Go语言实现代码】
本文实例讲述了php实现有序数组打印或排序的方法.分享给大家供大家参考,具体如下: 有序的数组打印或排序对于php来讲非常的简单了这里整理了几个不同语言的做法的实现代码,具体的我们一起来看这篇php中有序的数组打印或排序的例子吧. 最近有个面试题挺火的--把2个有序的数组打印或排序,刚看到这个题的时候也有点蒙,最优的算法肯定要用到有序的特性. 思考了一会发现也不是很难,假如数组是正序排列的,可以同时遍历2个数组,将小的值进行排序,最后会遍历完一个数组,留下一个非空数组,而且剩下的值肯定大于等于已