在tensorflow下利用plt画论文中loss,acc等曲线图实例
直接上代码:
fig_loss = np.zeros([n_epoch])
fig_acc1 = np.zeros([n_epoch])
fig_acc2= np.zeros([n_epoch])
for epoch in range(n_epoch):
start_time = time.time()
#training
train_loss, train_acc, n_batch = 0, 0, 0
for x_train_a, y_train_a in minibatches(x_train, y_train, batch_size, shuffle=True):
_,err,ac=sess.run([train_op,loss,acc], feed_dict={x: x_train_a, y_: y_train_a})
train_loss += err; train_acc += ac; n_batch += 1
summary_str = sess.run(merged_summary_op,feed_dict={x: x_train_a, y_: y_train_a})
summary_writer.add_summary(summary_str, epoch)
print(" train loss: %f" % (np.sum(train_loss)/ n_batch))
print(" train acc: %f" % (np.sum(train_acc)/ n_batch))
fig_loss[epoch] = np.sum(train_loss)/ n_batch
fig_acc1[epoch] = np.sum(train_acc) / n_batch
#validation
val_loss, val_acc, n_batch = 0, 0, 0
for x_val_a, y_val_a in minibatches(x_val, y_val, batch_size, shuffle=False):
err, ac = sess.run([loss,acc], feed_dict={x: x_val_a, y_: y_val_a})
val_loss += err; val_acc += ac; n_batch += 1
print(" validation loss: %f" % (np.sum(val_loss)/ n_batch))
print(" validation acc: %f" % (np.sum(val_acc)/ n_batch))
fig_acc2[epoch] = np.sum(val_acc) / n_batch
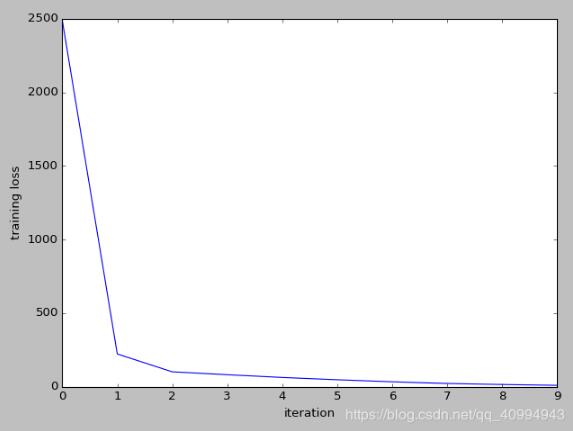
# 训练loss图
fig, ax1 = plt.subplots()
lns1 = ax1.plot(np.arange(n_epoch), fig_loss, label="Loss")
ax1.set_xlabel('iteration')
ax1.set_ylabel('training loss')
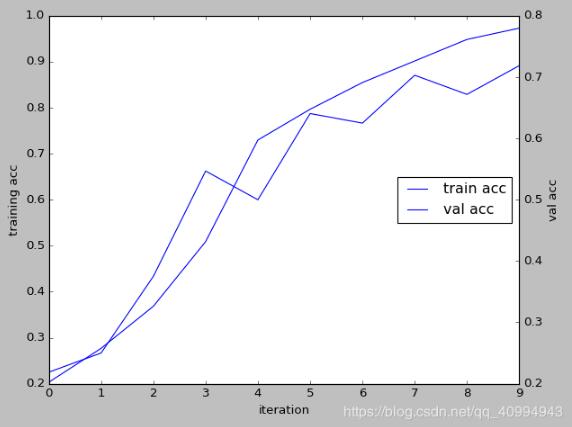
# 训练和验证两种准确率曲线图放在一张图中
fig2, ax2 = plt.subplots()
ax3 = ax2.twinx()#由ax2图生成ax3图
lns2 = ax2.plot(np.arange(n_epoch), fig_acc1, label="Loss")
lns3 = ax3.plot(np.arange(n_epoch), fig_acc2, label="Loss")
ax2.set_xlabel('iteration')
ax2.set_ylabel('training acc')
ax3.set_ylabel('val acc')
# 合并图例
lns = lns3 + lns2
labels = ["train acc", "val acc"]
plt.legend(lns, labels, loc=7)
plt.show()
结果:
补充知识:tensorflow2.x实时绘制训练时的损失和准确率
我就废话不多说了,大家还是直接看代码吧!
sgd = SGD(lr=float(model_value[3]), decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
# validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集
history=model.fit(self.x_train, self.y_train, batch_size=self.batch_size, epochs=self.epoch_size, class_weight = 'auto', validation_split=0.1)
# 绘制训练 & 验证的准确率值
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# 绘制训练 & 验证的损失值
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
print("savemodel---------------")
model.save(os.path.join(model_value[0],'model3_3.h5'))
#输出损失和精确度
score = model.evaluate(self.x_test, self.y_test, batch_size=self.batch_size)
以上这篇在tensorflow下利用plt画论文中loss,acc等曲线图实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
解决Tensorflow2.0 tf.keras.Model.load_weights() 报错处理问题
错误描述: 1.保存模型:model.save_weights('./model.h5') 2.脚本重启 3.加载模型:model.load_weights('./model.h5') 4.模型报错:ValueError: You are trying to load a weight file containing 12 layers into a model with 0 layers. 问题分析: 模型创建后还没有编译,一般是在模型加载前调用model.build(input_shape)
-
浅谈Tensorflow由于版本问题出现的几种错误及解决方法
1.AttributeError: 'module' object has no attribute 'rnn_cell' S:将tf.nn.rnn_cell替换为tf.contrib.rnn 2.TypeError: Expected int32, got list containing Tensors of type '_Message' instead. S:由于tf.concat的问题,将tf.concat(1, [conv1, conv2]) 的格式替换为tf.concat( [con
-
tensorflow2.0与tensorflow1.0的性能区别介绍
从某种意义讲,tensorflow这个项目已经失败了,要不了几年以后,江湖上再无tensorflow 因为tensorflow2.0 和tensorflow1.0 从本质上讲就是两个项目,1.0的静态图有他的优势,比如性能方面,但是debug不方便,2.0的动态图就是在模仿pytorch,但是画虎不成反类犬. 为了对比1.0 与2.0 1. pip install tensorflow==2.0.0a0 2. 为了控制变量我把mnist保存到本地的mongodb 3. 两种网络结构是一样的 ip
-
在tensorflow下利用plt画论文中loss,acc等曲线图实例
直接上代码: fig_loss = np.zeros([n_epoch]) fig_acc1 = np.zeros([n_epoch]) fig_acc2= np.zeros([n_epoch]) for epoch in range(n_epoch): start_time = time.time() #training train_loss, train_acc, n_batch = 0, 0, 0 for x_train_a, y_train_a in minibatches(x_trai
-
TensorFlow绘制loss/accuracy曲线的实例
1. 多曲线 1.1 使用pyplot方式 import numpy as np import matplotlib.pyplot as plt x = np.arange(1, 11, 1) plt.plot(x, x * 2, label="First") plt.plot(x, x * 3, label="Second") plt.plot(x, x * 4, label="Third") plt.legend(loc=0, ncol=1)
-
tensorflow下的图片标准化函数per_image_standardization用法
实验环境:windows 7,anaconda 3(Python 3.5),tensorflow(gpu/cpu) 函数介绍:标准化处理可以使得不同的特征具有相同的尺度(Scale). 这样,在使用梯度下降法学习参数的时候,不同特征对参数的影响程度就一样了. tf.image.per_image_standardization(image),此函数的运算过程是将整幅图片标准化(不是归一化),加速神经网络的训练. 主要有如下操作,(x - mean) / adjusted_stddev,其中x为图
-
在Java下利用log4j记录日志的方法
1.前言 log4j是一个用Java编写的可靠,快速和灵活的日志框架(API),它在Apache软件许可下发布. Log4j已经被移植到了C,C++,C#,Perl,Python和Ruby等语言中. Log4j是高度可配置的,并可通过在运行时的外部文件配置.它根据记录的优先级别,并提供机制,以指示记录信息到许多的目的地,例如:数据库,文件,控制台,UNIX系统日志等. Log4j中有三个主要组成部分: loggers: 负责捕获记录信息. appenders : 负责发布日志信息,以不同的首选目
-

Linux下利用Opencv打开笔记本摄像头问题
新建test文件夹,文件夹存在test.cpp和CMakeLists.txttest.cpp#include <iostream> #include <string> #include <sstream> #include <opencv2/core.hpp> #include <opencv2/highgui.hpp> #include <opencv2/videoio.hpp> using namespace cv; using
-
详解linux下利用crontab创建定时任务
Linux下可以利用crontab创建定时任务. 常用搭配 crontab -e 编辑任务 crontab -l 查看所有任务[该用户] crontab -r 取消所有任务[该用户] 任务格式 × × × × × +命令(具体任务) 前5个参数表示时间,依次为: 参数 范围 分钟 0-59 小时 0-23 日期 1-31 月份 1-12 星期 0-6(0代表星期日) 特殊符号 为了精确表示定时,需要一些特殊符号来描述具体的任务执行时间.有以下几个符号: "/" 代表每,每隔多长时间 &
-
centOS7 下利用iptables配置IP地址白名单的方法
编辑iptables配置文件,将文件内容更改为如下,则具备了ip地址白名单功能 #vim /etc/sysconfig/iptables *filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [0:0] -N whitelist -A whitelist -s 1.2.3.0/24 -j ACCEPT -A whitelist -s 4.5.6.7 -j ACCEPT -A INPUT -m state --state
-
Docker下利用jenkins和docker实现持续交付
一.什么是持续交付 让软件产品的产出过程在一个短周期内完成,以保证软件可以稳定.持续的保持在随时可以发布的状况.它的目标在于让软件的构建.测试与发布变得更快以及更频繁.这种方式可以减少软件开发的成本与时间,减少风险. 二.对比持续交付和传统交付 传统交付的发布周期可以表示为下图: 传统交付的缺点: 慢交付:在这里,客户在指定需求之后很长时间才收到产品.这导致了不满意的上市时间和客户反馈的延迟. 反馈周期长:反馈周期不仅与客户有关,还与开发人员有关.假设您意外地创建了一个bug,并在UAT阶段了解
-
在Vue环境下利用worker运行interval计时器的步骤
今天在code review时,发现之前遗留的问题: 在一个视频播放页面,有一个40ms的interval一直在阻碍,导致视频延时逐渐增大 于是写了一个worker单独把计时器拉出去跑了 实现步骤如下 由于用的是vue-cli,在webpack下要安装worker-loader依赖才能单独加载worker.js npm install worker-loader --save-dev 更改 vue.config.js 文件的配置项 configureWebpack:{ module: { rul
-
linux下利用shell在指定的行添加内容的方法
在linux的一些配置中总会要进行某个文件中的某行的操作,进行增加,修改,删除等操作. 而这里主要是进行的是指定的行添加数据的操作: 脚本如下: sed -i '3i asdf 1.sh' 1.sh 这个就是在1.sh中的第3行加入asdf的数据. 首先看1.sh内容如下: 执行sed命令如下: 这个就是一个比较简单的操作,比较实用. 以上这篇linux下利用shell在指定的行添加内容的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.