教你用Python代码实现合并excel文件
一、安装模块
1、找到对应的模块 http://www.python-excel.org/
2、用 pip install 安装
pip3 install xlrd
pip3 install XlsxWriter
因为使用的是 python3,所以安装的时候采用 pip3。
二、XlsxWriter 示例
先看看简单的演示:
import xlsxwriter
# 创建一个工作簿并添加一个工作表
workbook = xlsxwriter.Workbook("c.xlsx")
worksheet = workbook.add_worksheet()
# 设置列宽
worksheet.set_column("A:A", 20)
# 设置格式
bold = workbook.add_format({"bold": True})
# 设置单元格的值
worksheet.write("A1", "Hello")
# 带格式的单元格
worksheet.write("A2", "World")
# 写一些数字,用行列标识
worksheet.write(2, 0, 123)
worksheet.write(3, 0, 123.456, bold)
# 插入一张图片
worksheet.insert_image("B5", "s.png")
# 关闭文件流
workbook.close()
运行结果如下:

三、合并Excel数据
对于合并 excel,有两种 case ,一种是表头都是一样的,一种是表头不一样的excel ,但是希望放到同一个表格里面,方便查看
四、表头都一样的 excel
这个处理很简单,具体代码如下:
import xlrd
import xlsxwriter
source_xls = ["a.xlsx", "b.xlsx"]
target_xls = "3.xlsx"
# 读取数据
data = []
for i in c:
wb = xlrd.open_workbook(i)
for sheet in wb.sheets():
for rownum in range(sheet.nrows):
data.append(sheet.row_values(rownum))
print(data)
# 写入数据
workbook = xlsxwriter.Workbook(target_xls)
worksheet = workbook.add_worksheet()
font = workbook.add_format({"font_size": 14})
for i in range(len(data)):
for j in range(len(data[i])):
worksheet.write(i, j, data[i][j], font)
# 关闭文件流
workbook.close()
Excel 是由行和列组成的,所以这里将所有文件中的所有 sheet 中的数据读取出来组成一个二维数组,然后再写入新的 Excel。
五、表头都不一样的 excel
对于表头不一样的 excel,可能需要手动选取表格的一部分,然后进行合并。具体代码如下:
import xlrd
import xlsxwriter
source_xls = ["a.xlsx", "b.xlsx"]
target_xls = "合并.xlsx"
# 读取数据
data = []
# 重复数据
dupdata = []
# 姓名列表,按照姓名去重
name = []
# 获取excel的个数
sheetcount = len(source_xls)
i = 0
while i < len(source_xls):
wb = xlrd.open_workbook(source_xls[i])
# 存储不同excel 的数据
data.append([])
# 一个excel 可能存在多张表格
for sheet in wb.sheets():
if i == 0:
# 先把表头添加进去
dupdata.append(sheet.row_values(0))
for rownum in range(sheet.nrows):
# 判断名字是否重复,表头都是姓名开头的,所以把姓名除去
if (sheet.row_values(rownum)[0] in name):
dupdata.append(sheet.row_values(rownum))
# 给数据添加另一个表的表头
if (sheet.row_values(rownum)[0] == '姓名'):
data[i].append(sheet.row_values(rownum))
else:
name.append(sheet.row_values(rownum)[0])
data[i].append(sheet.row_values(rownum))
i+=1
# 合并数据
workbook = xlsxwriter.Workbook(target_xls)
worksheet = workbook.add_worksheet()
font = workbook.add_format({"font_size": 14})
lineNum = 0
for num in range(len(data)):
# 区分来自不同excel 的数据
if num== 0 :
for i in range(len(data[num])):
# 姓名
worksheet.write(lineNum, 0, data[num][i][0], font)
# 检查编号
worksheet.write(lineNum, 1, data[num][i][1], font)
# 年龄
worksheet.write(lineNum, 2, data[num][i][23], font)
# 蓝标
worksheet.write(lineNum, 3, data[num][i][14], font)
# 黄标
worksheet.write(lineNum, 4, data[num][i][19], font)
worksheet.write(lineNum, 5, data[num][i][20], font)
worksheet.write(lineNum, 6, data[num][i][21], font)
# 大小
worksheet.write(lineNum, 7, data[num][i][24], font)
worksheet.write(lineNum, 8, data[num][i][25], font)
worksheet.write(lineNum, 9, data[num][i][26], font)
lineNum += 1
# 只有两个excel ,所以直接用了 else
else:
for i in range(len(data[num])):
lineNum += 1
# 姓名
worksheet.write(lineNum, 0, data[num][i][0], font)
# 检查编号
worksheet.write(lineNum, 1, data[num][i][1], font)
# 年龄
worksheet.write(lineNum, 2, data[num][i][2], font)
# 蓝标
worksheet.write(lineNum, 3, data[num][i][30], font)
# 关闭文件流
workbook.close()
# 针对重复数据,连表头一起输出,方便后续回顾查看
workbook = xlsxwriter.Workbook("重复.xlsx")
worksheet = workbook.add_worksheet()
font = workbook.add_format({"font_size": 14})
for i in range(len(dupdata)):
for j in range(len(dupdata[i])):
worksheet.write(i, j, dupdata[i][j], font)
# 关闭文件流
workbook.close()
六、合并后的结果
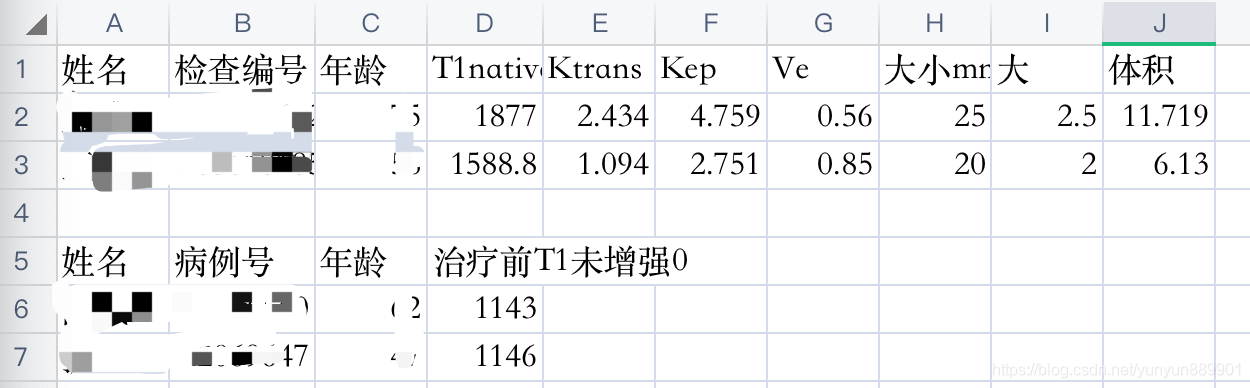
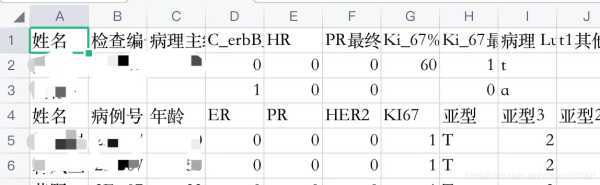
重复列表结果如下:
到此这篇关于教你用Python代码实现合并excel文件的文章就介绍到这了,更多相关Python合并excel文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python关于OS文件目录处理的实例分享
Python----OS 文件目录处理 import os import time # 获取当前文件的绝对路径 dir_1 = os.path.abspath(__file__) # D:\workspace\web-test\Study\Day_5-16\tset3.py # 获取当前文件所在目录的上级路径 dir_2 = os.getcwd() # D:\workspace\web-test\Study\Day_5-16 dir_3_1 = os.path.dirname(dir_1) #
-
python基础之文件处理知识总结
一.open()方法 python open()方法用于打开一个文件,并返回文件对象,在对文件处理的过程中都需要用到这个函数,如果文件无法打开,会抛出OSError. 注意:使用open()方法的时候一定到保证关闭文件对象,文件里面的内容才会被保存,关闭文件需要调用close()方法. open()方法常用的形式是接收两个参数:文件名(file)和模式(mode) 基本语法: open(file,mode='r') 完整的语法: open(file,mode='r',buffering=1,en
-

将Python代码打包成.exe可执行文件的完整步骤
前言 有时候我们需要将自己写的代码打包成exe文件,给别人使用需要怎么办呢?以下将讲解Python代码如何打包成.exe文件. 1. 下载pyinstaller PyInstaller是一个十分有用的第三方库,它能够在Windows.Linux. Mac OS X 等操作系统下将 Python 源文件打包,通过对源文件打包, Python 程序可以在没有安装 Python 的环境中运行,也可以作为一个 独立文件方便传递和管理. 因为Python中有很多三方包,我们想要这些三方包也包含在里面就需要
-
python可视化hdf5文件的操作
对于一些复杂的hdf5文件,通过可视化的方法可以比较容易的了解文件的内部结构,下面介绍基于python的一个hdf5文件的安装使用方法 1 安装vitables工具包 命令 pip install vitables 2 安装完成后在终端中使用命令 vitables 文件名.hdf5 最终实现hdf5文件的可视化,方便直观就像一层层打开文件夹一样 补充:python对于HDF5的操作 看代码吧~ import h5py #导入工具包 import numpy as np #HDF5的写入: img
-
Python 如何读取.txt,.md等文本文件
看代码吧~ # example.md 1 2 3 4 5 6 7 8 9 >>> with open('example.md') as f: lines = f.readlines() >>> lines ['1 2 3\n', '4 5 6\n', '7 8 9\n'] # 我们发现每一行后面都会有一个回车符,我们使用strip()函数消除它 >>> lines = [i.strip() for i in lines] ['1 2 3', '4 5
-
python基础学习之组织文件
一.Shutil 模块 shutil其实也就是shell模块.其中包含一些函数,可以让我们在python程序中复制.移动.改名和删除文件. 1.1 复制文件和文件夹 shutil.copy(source,destination):将路径source处的文件复制到路径destination处的文件夹.如果destination是一个文件名,那么它将作为被复制的新名字 shutil.copytree(source,destination):将路径source处的文件夹,包括它的所有文件和子文件夹,复
-
用python删除文件夹中的重复图片(图片去重)
第一部分:判断两张图片是否相同 要查找重复的图片,必然绕不开判断两张图片是否相同.判断两张图片简单呀!图片可以看成数组,比较两个数组是否相等不就行了.但是这样做太过简单粗暴,因为两个数组的每个元素都要一一比较,效率很低.为了尽量避免两个庞大的数组比较: 先进行两张图片的大小(byte)比较,若大小不相同,则两张图片不相同: 在两张图片的大小相同的前提下,进行两张图片的尺寸(长和宽)比较,若尺寸不相同,则两张不相同: 在两张图片的尺寸相同的前提下,进行两张图片的内容(即数组元素)比较,若内容不相同
-
Python爬虫之m3u8文件里提取小视频的正确姿势
前言 在网上爬取的小视频(.ts格式)打不开怎么搞?使用IDM下载有时候还会出现数据受法律保护,IDM无法下载该内容,如何解决?这篇博客就来聊聊如何正确提取m3u8文件里的.ts视频,并合成完整的.mp4格式视频. 1. HLS协议与m3u8文件 HLS,即 H T T P L i v e S t r e a m i n g HTTP\ Live\ Streaming HTTP Live Streaming的缩写,是由苹果公司提出基于HTTP的流媒体网络传输协议.是苹果公司Qui
-
解决python中os.system调用exe文件的问题
前一段时间导师叫我写一个批处理的小程序,就是循环修改辐射传输模型软件MODTRAN的输入参数,然后运行MODTRAN软件进行计算,输出 需要的结果.我这里用的是python写的小程序,那就需要考虑用python调用MODTRAN的exe文件运行,查了一些资料可以用os.system命令来 执行exe文件,说起来直接调用就行了嘛,对吧,但是说起来简单,还是会遇到一些莫名其妙的问题,下面我来说说我遇到的问题. 先给大家介绍一下MODTRAN这个软件运行的一个过程. 这个软件里的东西如下图所示: 简单
-
python使用glob检索文件的操作
一.检索当前目录下所有文件.文件夹 from glob import glob glob('./*') Output: ['./0a.wav', './aaa', './1b.wav', './1a.wav', './0b.wav'] #返回一个list 二.检索当前目录下指定后缀名文件 假设我们需要获取当前文件夹下所有后缀名为".wav"的文件, from glob import glob glob('./*.wav') Output: ['./0a.wav', './1b.wav'
-
Python文件基本操作实用指南
文件的存储方式 在计算机中,文件是以 二进制的方式保存在磁盘上的 文本文件和二进制文件 文本文件 可以使用文本编辑软件查看 本质上还是二进制文件 二进制文件 保存的内容 不是给人直接阅读的,而是提供给其她软件使用的 二进制文件不能使用 文件编辑软件 查看 文件基本操作 操作文件的套路 在计算机 中要操作文件一共包含三个步骤: 1.打开文件 2.读.写文件 读 将文件内容读入内容 写 将内存内容写入文件 3.关闭文件 操作文件的函数/方法 序号 函数/方法 说明 1 open 打开文件,并且返回文
-
python3 hdf5文件 遍历代码
看代码吧~ import h5py import numpy as np f = h5py.File('train/e1_1.hdf5') key = "" for k in f.keys(): key = k d = f[key] print(d) a = np.ones(d.shape) d.read_direct(a) print(a) f.close() 补充:HDF5 文件及Python模块之h5py HDF5文件 什么是HDF5文件呢? 先引用一波维基百科的介绍,『层级数据
-
教你利用Python破解ZIP或RAR文件密码
一.破解原理 其实原理很简单,一句话概括就是「大力出奇迹」,Python 有两个压缩文件库:zipfile 和 rarfile,这两个库提供的解压缩方法 extractall()可以指定密码,这样的话首先生成一个密码字典(手动或用程序),然后依次尝试其中的密码,如果能够正常解压缩表示密码正确. 二.实验环境 本文采取的虚拟环境为 Pipenv. 库 zipfile:Python 标准库,使用时直接导入即可 rarfile:Python 第三方库 利用 Pipenv 安装 rarfile pipe
-
Python文件名的匹配之clob库
一.前言 既然在Pathlib库中提到了glob()函数,那么我们就专门用一篇内容讲解文件名的匹配.其实我们有专门的一个文件名匹配库就叫:glob. 不过,glob库的API非常小,但是仅仅应用于文件名的匹配绰绰有余.只要是在实际的项目中需要过滤,或者匹配一组文件,都可以使用该库进行操作. 二.通配符 星号(*) 话不多说,下面我们使用通配符来匹配文件名,示例如下: import glob for name in sorted(glob.glob('text/*')): print(name)
-
python引入其他文件夹下的py文件具体方法
红色方框要引入箭头里面的 import sys sys.path.append('../../config/') from database import * print(MYSQL_CONFIG) 内容扩展: Python的import包含文件功能就跟PHP的include类似,但更确切的说应该更像是PHP中的require,因为Python里的import只要目标不存在就报错程序无法往下执行.要包含目录里的文件,PHP中只需要给对路径就OK.Python中则不同 a.py 要 import
-
Python基础之元组与文件知识总结
大纲 Python文件类型及汇总 一.元组 1 特征 1.任意对象的有序集合 2.通过下标访问 3.不可变 4.长度固定,任意类型,任意嵌套 >>> t = (1,2,3,4,5) >>> t[0] = 2 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not suppo
-
python 如何把classification_report输出到csv文件
今天想把classification_report的统计结果输出到文件中,我这里分享一下一个简洁的方式: 我的pandas版本: pandas 1.0.3 代码: from sklearn.metrics import classification_report report = classification_report(y_test, y_pred, output_dict=True) df = pd.DataFrame(report).transpose() df.to_csv("resu
-
python提取word文件中的所有图片
前言 办公中,偶尔会碰到一种情况,需要提取word文档中的图片,决定写这样一款工具自动提取图片. 关于脚本的使用: 情景1:如果你拿到的是一个文件夹,所有的word文件都在这个文件夹的子目录下,深度为1层,你可以直接使用该脚本 情景2:如果你拿到的是一个文件夹,打开之后,里面杂乱无章的充斥着各种文件,你也不确定word文档都在哪,那么你需要使用Everything来手动提取出所有的word文档,虽然我也可以让脚本实现这个功能,但是使用脚本需要考虑到有可能存在同名文件,再处理起来代码量会更大,还是