python接入使用百度翻译流程
目录
- 一、分析网页
- 二、使用步骤
- 1.导入库
- 2.键盘输入内容
- 3.构建url/headers/data参数
- 4.发起请求响应数据
- 5.解析数据输出结果
- 三、完整代码
一、分析网页
1. 打开网页,在搜索框输入百度翻译并进入百度翻译网站中。F12调出开发者工具,点击Network(网络)\ Fetch/XHR,同时在翻译框中任意输入搜索内容,此时就会发现有一个名称为sug的包。点击该包,点击后会看到有Heders、Payload、Preview和Rsponse等选项。点击Heders选项,将Request URL:后面的网址复制,这就是我们代码中需要的url。
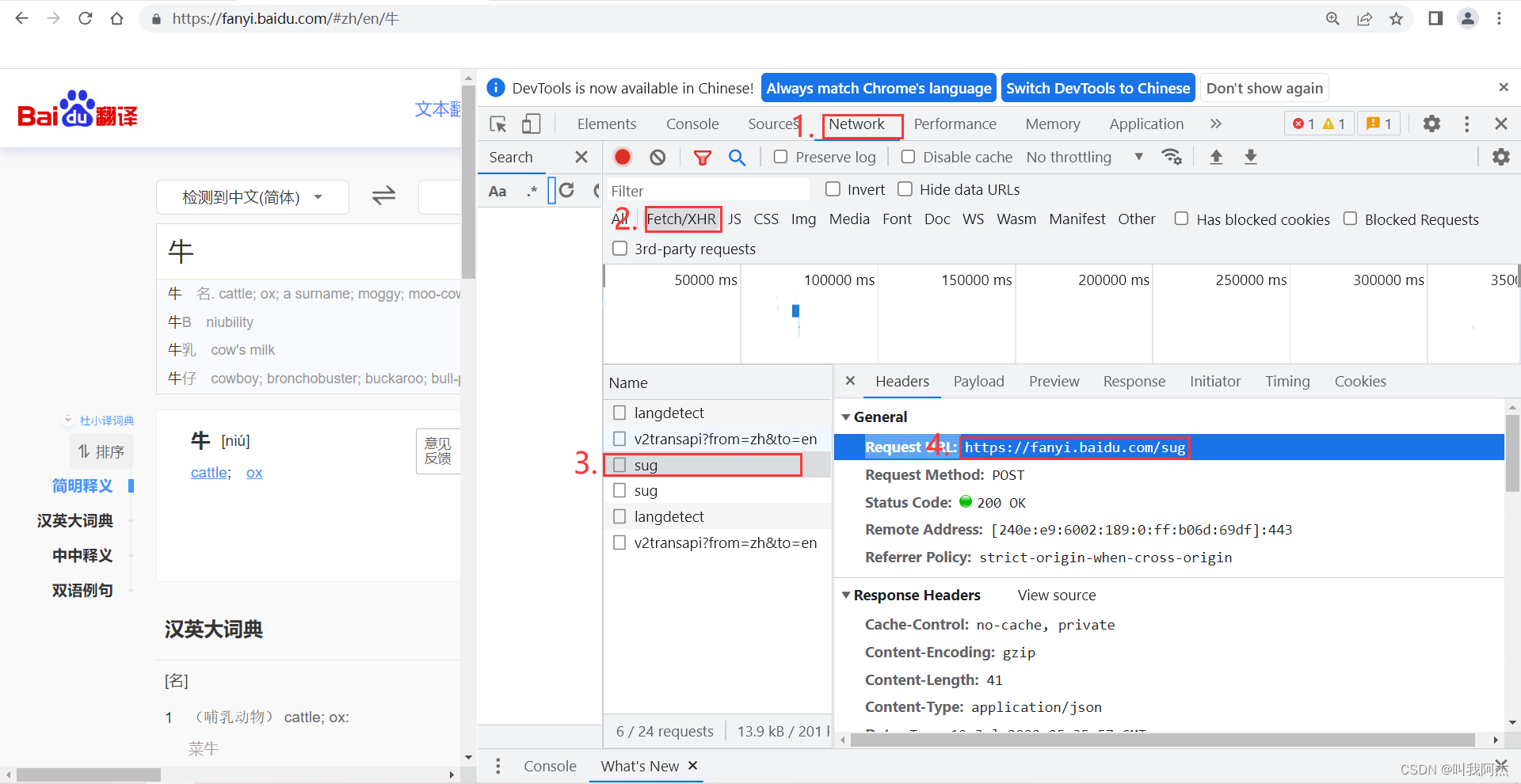
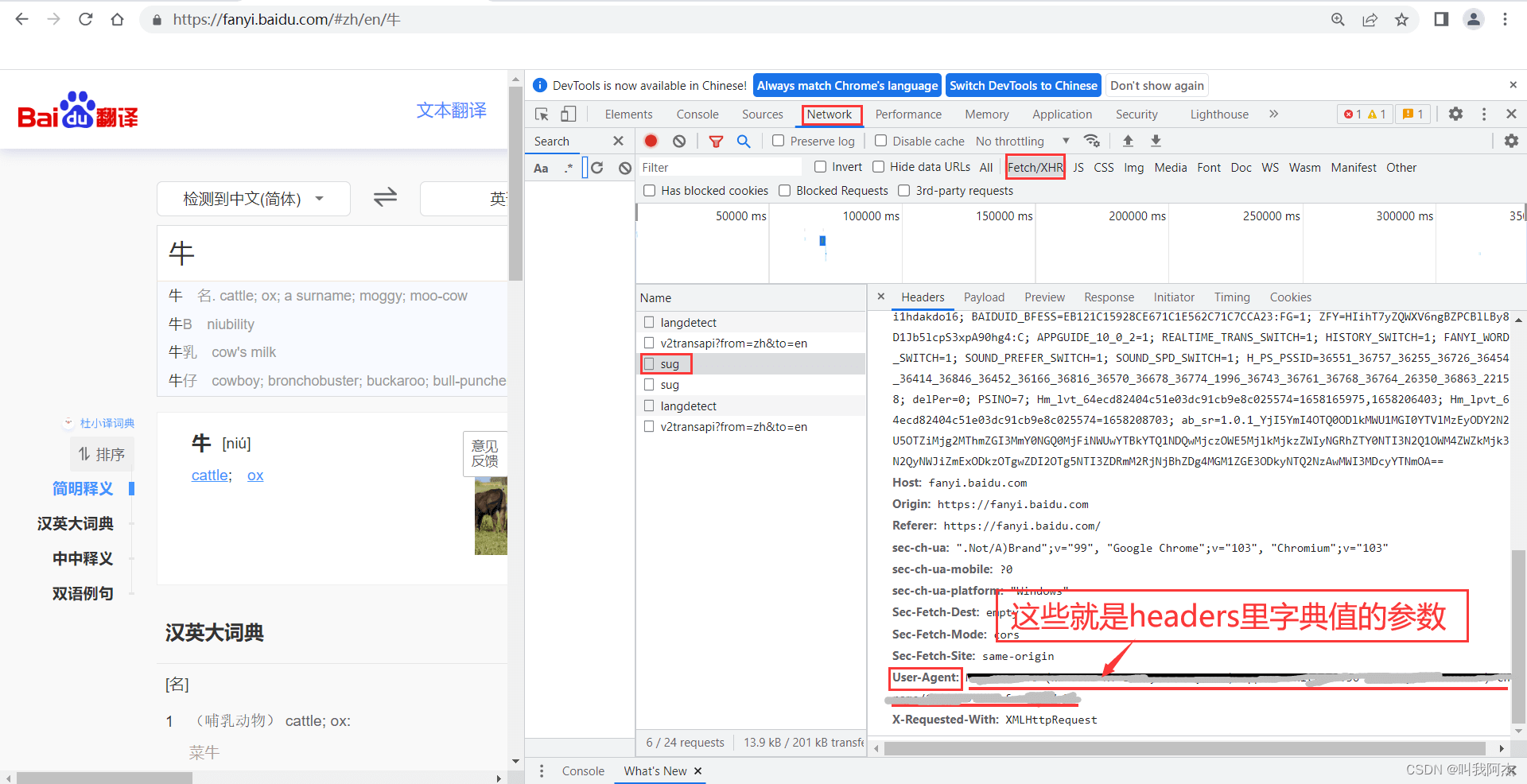
2.在Heders选项中鼠标滚轮到最下方,找到User-Agent:并将后面的参数复制,就是我们所需的headers(请求头参数)。
3.页面中点击Payload选项,在Form Data选项下我们会看到有键值对的参数。前面的”键“相当于百度翻译中的搜索框,而后面的值就是我们输入的翻译内容。这部分参数就是data参数,data参数是以字典方式传递,所以这个”键“即kw就是我们所需的data参数的键。
激动人心的时刻,找到以上参数就可以下一步了!!!
二、使用步骤
1.导入库
代码如下(示例):
import requests import json
2.键盘输入内容
代码如下(示例):
fan_yi = input("请输入要翻译的内容:") # 2.键盘输入翻译内容
该处使用的url网络请求的数据。
3.构建url/headers/data参数
这里面的headers参数因为设备不同可能会报错,大家可以根据我上面的网页分析去找自己电脑浏览器的参数,复制过来就行了。
注意事项:headers参数是以字典的形式存在的,其键和值都是字符串格式,还有User-Agent参数中的U字母和A字母都必须是大写,如果粗心写错了是会报错的哟。
代码如下(示例):
import requests # 1.导入库
import json
fan_yi = input("请输入要翻译的内容:") # 2.键盘输入翻译内容
url = "https://fanyi.baidu.com/sug" # 3.写入url
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 "} # 4.构建headers
data = {"kw":fan_yi} # 5.构建data
rsponse1 = requests.post(url = url,headers = headers,data = data) # 6.发起请求
rsponse2 = rsponse1.text # 获取响应数据
jie_xi = json.loads(rsponse2) # 解析数据
print(jie_xi) # 输出结果
4.发起请求响应数据
代码如下(示例):
rsponse1 = requests.post(url = url,headers = headers,data = data) # 发起请求 rsponse2 = rsponse1.text # 获取响应数据
5.解析数据输出结果
代码如下(示例):
jie_xi = json.loads(rsponse2) # 解析数据 print(jie_xi) # 输出结果
三、完整代码
注意事项:headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 "} 这一部分中的"Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 "我已经删减所以直接复制过去运行会报错,因按照如下图找到自己电脑浏览器的User-Agent:后面的参数复制进代码修改才行。
重要的事情讲三遍!!!:headers参数是以字典的形式存在的,其键和值都是字符串格式,还有User-Agent参数中的U字母和A字母都必须是大写,如果粗心写错了是会报错的哟。
重要的事情讲三遍!!!:headers参数是以字典的形式存在的,其键和值都是字符串格式,还有User-Agent参数中的U字母和A字母都必须是大写,如果粗心写错了是会报错的哟。
重要的事情讲三遍!!!:headers参数是以字典的形式存在的,其键和值都是字符串格式,还有User-Agent参数中的U字母和A字母都必须是大写,如果粗心写错了是会报错的哟。
方法一:中规中矩写
代码如下(示例):
import requests # 导入库
import json
fan_yi = input("请输入要翻译的内容:") # 键盘输入翻译内容
url = "https://fanyi.baidu.com/sug" # 写入url
# 构建headers
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 "}
data = {"kw":fan_yi} 构建data
rsponse1 = requests.post(url = url,headers = headers,data = data) # 发起请求
rsponse2 = rsponse1.text # 获取响应数据
jie_xi = json.loads(rsponse2) # 解析数据
print(jie_xi) # 输出结果
方法二:将代码封装到函数里
def fangYi(data1):
url = "https://fanyi.baidu.com/sug"
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64)
data = {"kw":data1}
rsponse1 = requests.post(url = url,headers = headers,data = data)
rsponse2 = rsponse1.content.decode()
json1 = json.loads(rsponse2)
print(json1)
if __name__ == '__main__':
while True:
data1 = input("+++++请在下方输入要翻译的内容,退出请输入”no“+++++\n\t请输入要翻译的内容:")
if data1 == "no":
break
else:
fangYi(data1)
到此这篇关于python接入使用百度翻译流程的文章就介绍到这了,更多相关python百度翻译内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python如何通过百度翻译API实现翻译功能
本人英语不好,很多词组不认识,只能借助工具:百度翻译和谷歌翻译都不错,近期自学Python,就想能否自己设计一个百度翻译软件呢? 百度翻译开放平台:http://api.fanyi.baidu.com/api/trans/product/index 百度翻译开放平台是百度翻译面向广大开发者提供开放服务的平台. 服务涵盖:通用翻译API.定制化翻译API.语音翻译SDK.拍照翻译SDK等,并持续更新中.自己用通用的即可. 通用翻译API采用全流程自助申请的模式.点击网站上方的"登录"按钮
-
python 爬虫如何实现百度翻译
环境 python版本号 系统 游览器 python 3.7.2 win7 google chrome 关于本文 本文将会通过爬虫的方式实现简单的百度翻译.本文中的代码只供学习,不允许作为于商务作用.商务作用请前往api.fanyi.baidu.com购买付费的api.若有侵犯,立即删文! 实现思路 在网站文件中找到隐藏的免费api.传入api所需要的参数并对其发出请求.在返回的json结果里找到相应的翻译结果. 百度翻译的反爬机制 由js算法生成的sign cookie检测 token暗号 在
-
python使用百度翻译进行中翻英示例
利用百度词典进行中翻英 复制代码 代码如下: import urllib2import reimport sys reload(sys)sys.setdefaultencoding('utf-8')def tran(word): url='http://dict.baidu.com/s?wd={0}&tn=dict'.format(word) print url req=urllib2.Request(url) resp=urllib2.urlopen(req) r
-
Python爬虫实现百度翻译功能过程详解
首先,需要简单的了解一下爬虫,尽可能简单快速的上手,其次,需要了解的是百度的API的接口,搞定这个之后,最后,按照官方给出的demo,然后写自己的一个小程序 打开浏览器 F12 打开百度翻译网页源代码: 我们可以轻松的找到百度翻译的请求接口为:http://fanyi.baidu.com/sug 然后我们可以从方法为POST的请求中找到参数为:kw:job(job是输入翻译的内容) 下面是代码部分: from urllib import request,parse import json def
-

用python实现百度翻译的示例代码
用python实现百度翻译,分享给大家,具体如下: 首先,需要简单的了解一下爬虫,尽可能简单快速的上手,其次,需要了解的是百度的API的接口,搞定这个之后,最后,按照官方给出的demo,然后写自己的一个小程序 打开浏览器 F12 打开百度翻译网页源代码: 我们可以轻松的找到百度翻译的请求接口为:http://fanyi.baidu.com/sug 然后我们可以从方法为POST的请求中找到参数为:kw:job(job是输入翻译的内容) 下面是代码部分: from urllib import req
-
Python使用requests模块爬取百度翻译
requests模块: python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高. 作用:模拟浏览器发请求. 提示:老版使用 urllib模块,但requests比urllib模块要简单好用,现在学习requests模块即可! requests模块编码流程 指定url 1.1 UA伪装 1.2 请求参数的处理 2.发起请求 3.获取响应数据 4.持久化存储 环境安装: pip install requests 案例一:破解百度翻译(post请求) 1.代码如下: #爬取百度翻
-
python爬虫之爬取百度翻译
破解百度翻译 翻译是一件麻烦的事情,如果可以写一个爬虫程序直接爬取百度翻译的翻译结果就好了,可当我打开百度翻译的页面,输入要翻译的词时突然发现不管我要翻译什么,网址都没有任何变化,那么百度翻译要怎么爬取呢? 爬取百度翻译之前,我们先要明白百度翻译是怎么在不改变网址的情况下实现翻译的.百度做到这一点是用 AJAX 实现的,简单地说,AJAX的作用是在不重新加载网页的情况下进行局部的刷新. 了解了这一点,那么我们要怎么得到 AJAX 工作时请求的URL呢?老规矩,使用抓包工具. 爬虫步骤 在 "百度
-
基于python实现百度翻译功能
运行环境: python 3.6.0 今天处于练习的目的,就用 python 写了一个百度翻译,是如何做到的呢,其实呢就是拿到接口,通过这个接口去访问,不过中间确实是出现了点问题,不过都解决掉了 先晾图后晾代码 运行结果: 代码: # -*- coding: utf-8 -*- """ 功能:百度翻译 注意事项:中英文自动切换 """ import requests import re class Baidu_Translate(object):
-
Python爬取百度翻译实现中英互译功能
目录 基础步骤 提交表单 获取响应并处理结果 消除警告 main.py sign.py 由于下学期报了一个Python的入门课程 所以寒假一直在自己摸索,毕竟到时候不能挂科,也是水水学分 最近心血来潮打算试试爬一下百度翻译 肝了一天终于搞出来了 话不多说,直接开搞(环境是Python 3.8 PyCharm Community Edition 2021.3.1) 基础步骤 百度翻译会识别到爬虫,所以得用headers隐藏一下 以chorme浏览器为例 在百度翻译页面点击鼠标右键,选择“检查”(或
-
python接入使用百度翻译流程
目录 一.分析网页 二.使用步骤 1.导入库 2.键盘输入内容 3.构建url/headers/data参数 4.发起请求响应数据 5.解析数据输出结果 三.完整代码 一.分析网页 1. 打开网页,在搜索框输入百度翻译并进入百度翻译网站中.F12调出开发者工具,点击Network(网络)\ Fetch/XHR,同时在翻译框中任意输入搜索内容,此时就会发现有一个名称为sug的包.点击该包,点击后会看到有Heders.Payload.Preview和Rsponse等选项.点击Heders选项,将Re
-
Python使用百度翻译开发平台实现英文翻译为中文功能示例
本文实例讲述了Python使用百度翻译开发平台实现英文翻译为中文功能.分享给大家供大家参考,具体如下: #coding=utf8 import random import requests import hashlib appid = 'xxxxxx' secretKey = 'xxxxx' def get_md5(string):#返回字符串md5加密 hl = hashlib.md5() hl.update(string.encode('utf-8')) return hl.hexdiges