MySQL优化案例之隐式字符编码转换
目录
- 索性失效前提
- 一个真实的案例
- 优化前原始sql分析
- 优化初步处理
- 初步优化无效分析
- 第二次优化处理
- 第三次优化
- 结论
索性失效前提
MySQL中我们知道有:
- 1、如果对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。
- 2、隐式类型转换也会导致同样的放弃走树搜索。
因为类型转换等价于在条件字段上使用了函数比如:
/*假设tradeid字段有索引,且为varchar类型*/ mysql> select * from tradelog where tradeid=110717; /*等价于*/ mysql> select * from tradelog where CAST(tradid AS signed int) = 110717;
一个真实的案例
下面来看看隐式字符编码转换导致的一个慢sql
优化前原始sql分析
业务上有个sql执行需要1.31秒

看看执行计划:

从执行计划分析看出问题出在r表也就是 h_merge_result_new_indicator 表全表扫描,查看该表的表结构有联合索引。但是联合索引范围后会失效,于是打算新建一个联合索引。
优化初步处理
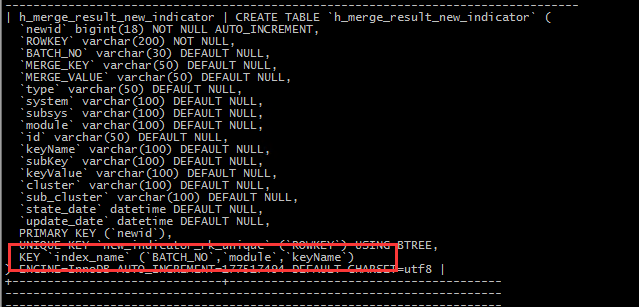
查看预新建联合索引的字段选择性:

结合选择性来看;
create index idx_hmrni on h_merge_result_new_indicator(keyName,module,BATCH_NO);
初步优化无效分析
创建后,再次查看执行计划依然无效;

查看表结构:

另外3个表结构其中有2个utf8mb4,1个utf8


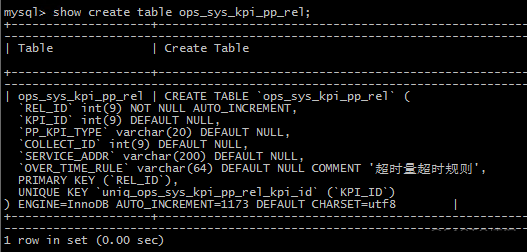
字符集 utf8mb4 是 utf8 的超集,所以当这两个类型的字符串在做比较的时候,MySQL 内部的操作是,先把 utf8 字符串转成 utf8mb4 字符集,再做比较。
因此:

这部分会转换后再与h_merge_result_new_indicator关联
第二次优化处理
优化就只需要将字符集编码转为utf8再和h_merge_result_new_indicator关联就能用上索引

再看查询只需要0.02秒了

第三次优化
但是还有个问题,如上执行计划key_len是606 =(100*3+3)+(100*3+3)
也就是说,没有用上BATCH_NO字段上的索引,我们知道索引少一个字段,占用会减少,不会太臃肿,因此,联合索引只需要包含r(keyName,module)
- drop index idx_hmrni on h_merge_result_new_indicator;
- create index idx_hmrni on h_merge_result_new_indicator(keyName,module);
结论
对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能。该例子是隐式字符编码转换,它们都跟其他条件索引上使用函数一样,因为要求在索引字段上做函数操作而导致了全索引扫描。
MySQL 的优化器确实有“偷懒”的嫌疑,即使简单地把 where id+1=1000 改写成 where id=1000-1 就能够用上索引快速查找,也不会主动做这个语句重写。
保证在条件索引上不做破坏索引值的有序性,是优化索引的利器。
到此这篇关于MySQL优化案例之隐式字符编码转换的文章就介绍到这了,更多相关MySQL隐式字符编码转换内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

MySQL 字符串转换为数字的方法小结
方法一:直接 加 0select '123' + 0 方法二:函数 convert语法:convert (value, type);type可以为: decimal 浮点数 signed 整数 unsigned 无符号整数 select convert('123',signed) 方法三:函数 cast语法:cast (value as type); type可以为: decimal 浮点数 signed 整数 unsigned 无符号整数 select cast('123' as signed
-
浅谈MySql整型索引和字符串索引失效或隐式转换问题
目录 问题概述 问题重现 问题引申 结论 问题概述 今天在上班时,DBA突然找出来一段sql,表示该sql存在隐式转换,不走索引.经过我们的查看后,发现是类型varchar的字段, 我们使用条件传入了数值型的值,由于担心违反保密协议,在此就不贴图了,由我重现一下类似情况给大家看一下. 问题重现 首先我们先创建一张用户表test_user,其中USER_ID为了效果我们设置为varchar类型且加上唯一索引. CREATE TABLE test_user ( ID int(11) NOT NULL
-
mysql字符串的‘123’转换为数字的123的实例
方法一:SELECT CAST('123' AS SIGNED); 方法二:SELECT CONVERT('123',SIGNED); 方法三:SELECT '123'+0; 以上这篇mysql字符串的'123'转换为数字的123的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
php中将图片gif,jpg或mysql longblob或blob字段值转换成16进制字符串
数据库脚本: -- -------------------------------------------------------- -- -- 表的结构 `highot_attachment` -- 复制代码 代码如下: CREATE TABLE IF NOT EXISTS `highot_attachment` ( `id` int(11) NOT NULL auto_increment, `phone_number_id` int(11) NOT NULL COMMENT 'phone_n
-
MySql获取当前时间并转换成字符串的实现
目录 MySql获取当前时间的函数 时间转字符串 字符串转日期 MySql获取当前时间的函数 now(); select now(); //结果:2019-04-19 09:31:59 sysdate(); select SYSDATE(); //结果:2019-04-19 09:31:59 MySql 还有其他的一些函数,本人没用过 current_timestamp() current_timestamp localtime() localtime localtimestamp – (v4.
-
完美转换MySQL的字符集 解决查看utf8源文件中的乱码问题
MySQL从4.1版本开始才提出字符集的概念,所以对于MySQL4.0及其以下的版本,他们的字符集都是Latin1的,所以有时候需要对mysql的字符集进行一下转换,MySQL版本的升级.降级,特别是升级MySQL的版本,为了不让程序继续沿用Latin1字符集之后对以后Discuz!版本升级的影响和安装SupeSite,这就需要我们进行字符集的转换! 本人转换过好多数据了,也用过了好多的办法,个人感觉最好用的就是使用MySQL命令导出导入中将字符集转换过去! 现在我将用图文并茂的方式向大家展示一
-
mysql 乱码字符 latin1 characters 转换为 UTF8详情
背景:目前正在进行业务重构,需要对使用MySQL的业务库表进行重新设计,在迁移时,遇到了中文字符乱码问题(源库表的默认编码是LATIN1,新库表的默认编码为UTF8),故重新学习了下MySQL编码和解码相关知识,并整理了在遭遇乱码时的一些常用技巧. 比如我下面一张表是省市区的编码存储,导入之后数据库变成如下的乱码: 这个实际上是latin1字符编码. 如果我们直接查的话,那么需要转换一下: select id,parent_code,area_code,CONVERT(CAST(CONVERT(
-
详解MySQL如何有效的存储IP地址及字符串IP和数值之间如何转换
在看高性能MySQL第3版(4.1.7节)时,作者建议当存储IPv4地址时,应该使用32位的无符号整数(UNSIGNED INT)来存储IP地址,而不是使用字符串.但是没有给出具体原因.为了搞清楚这个原因,查了一些资料,记录下来. 相对字符串存储,使用无符号整数来存储有如下的好处: 节省空间,不管是数据存储空间,还是索引存储空间 便于使用范围查询(BETWEEN...AND),且效率更高 通常,在保存IPv4地址时,一个IPv4最小需要7个字符,最大需要15个字符,所以,使用VARCHAR(15
-
深入MYSQL字符数字转换的详解
1.将字符的数字转成数字,比如'0'转成0可以直接用加法来实现例如:将pony表中的d 进行排序,可d的定义为varchar,可以这样解决select * from pony order by (d+0) 2.在进行ifnull处理时,比如 ifnull(a/b,'0') 这样就会导致 a/b成了字符串,因此需要把'0'改成0,即可解决此困扰 3.比较数字和varchar时,比如a=11,b="11ddddd";则 select 11="11ddddd"相等若绝对比
-
MySQL优化案例之隐式字符编码转换
目录 索性失效前提 一个真实的案例 优化前原始sql分析 优化初步处理 初步优化无效分析 第二次优化处理 第三次优化 结论 索性失效前提 MySQL中我们知道有: 1.如果对索引字段做函数操作,可能会破坏索引值的有序性,因此优化器就决定放弃走树搜索功能. 2.隐式类型转换也会导致同样的放弃走树搜索. 因为类型转换等价于在条件字段上使用了函数比如: /*假设tradeid字段有索引,且为varchar类型*/ mysql> select * from tradelog where tradeid=
-
MySQL索引失效之隐式转换的问题
目录 常见索引失效: 一.常见索引失效场景 1.条件字段函数操作 2.条件字段运算操作 3.隐式类型转换 4.隐式字符编码转换 二.类型转换 1.字符串转整型 2.时间类型转换 常见索引失效: 1. 条件索引字段"不干净":函数操作.运算操作 2. 隐式类型转换:字符串转数值:其他类型转换 3. 隐式字符编码转换:按字符编码数据长度大的方向转换,避免数据截取 一.常见索引失效场景 root@test 10:50 > show create table t_num\G ******
-
MySQL隐式类型的转换陷阱和规则
前言 相信大家都知道隐式类型转换有无法命中索引的风险,在高并发.大数据量的情况下,命不中索引带来的后果非常严重.将数据库拖死,继而整个系统崩溃,对于大规模系统损失惨重.所以下面通过本文来好好学习下MySQL隐式类型的转换陷阱和规则. 1. 隐式类型转换实例 今天生产库上突然出现MySQL线程数告警,IOPS很高,实例会话里面出现许多类似下面的sql:(修改了相关字段和值) SELECT f_col3_id,f_qq1_id FROM d_dbname.t_tb1 WHERE f_col1_id=
-
MySQL令人大跌眼镜的隐式转换
目录 MySQL的隐式转换 一.问题描述 二.源码解释 三.结论 MySQL的隐式转换 一.问题描述 show create table t1\G *************************** 1. row *************************** Table: t1 Create Table: CREATE TABLE `t1` ( `id` varchar(255) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 1
-
php中的字符编码转换函数用法示例
本文实例讲述了php中的字符编码转换函数的用法,分享给大家供大家参考.具体实现方法如下: 一般来说,在网页程序中,尤其是涉及到数据库的读出过程中,往往最恼火的就是字符编码的问题,php4.0.6以上的版本提供了mb_convert_encoding 可以方便的转换编码. 具体如下: 复制代码 代码如下: <?php /* Convert internal character encoding to SJIS */ $str = mb_convert_encoding($str, "SJIS
-
php字符编码转换之gb2312转为utf8
在php中字符编码转换我们一般会用到iconv与mb_convert_encoding进行操作,但是mb_convert_encoding在转换性能上比iconv要差很多哦.string iconv ( string in_charset, string out_charset, string str ) 注意:第二个参数,除了可以指定要转化到的编码以外,还可以增加两个后缀://TRANSLIT 和 //IGNORE,其中 //TRANSLIT 会自动将不能直接转化的字符变成一个或多个近似的字符
-
PHP iconv()函数字符编码转换的问题讲解
在php中iconv函数库能够完成各种字符集间的转换,是php编程中不可缺少的基础函数库:但有时候iconv对于部分数据转码会无缘无故的少一些.比如在转换字符"-"到gb2312时会出错. 下面一起慢慢看一下这个函数的用法. 最简单的应用,把gb2312置换成utf-8: $text=iconv("GB2312","UTF-8",$text); 在用$text=iconv("UTF-8","GB2312",
-
MySQL优化案例系列-mysql分页优化
通常,我们会采用ORDER BY LIMIT start, offset 的方式来进行分页查询.例如下面这个SQL: SELECT * FROM `t1` WHERE ftype=1 ORDER BY id DESC LIMIT 100, 10; 或者像下面这个不带任何条件的分页SQL: SELECT * FROM `t1` ORDER BY id DESC LIMIT 100, 10; 一般而言,分页SQL的耗时随着 start 值的增加而急剧增加,我们来看下面这2个不同起始值的分页SQL执行
-
浅谈JavaScript中的字符编码转换问题
要获得字符的Unicode编码,可以使用string.charCodeAt(index)方法,其定义为: strObj.charCodeAt(index) index为指定字符在strObj对象中的位置(基于0的索引),返回值为0与65535之间的16位整数.例如: var strObj = "ABCDEFG"; var code = strObj.charCodeAt(2); // Unicode value of character 'C' is 67 如果index指定的索引处没
-
shell实现字符编码转换工具分享
复制代码 代码如下: #!/bin/bash : << mark转码工具,支持UTF-8转GBK和GBK转UTF-8孔令飞@2012-05-07mark #set -x scode="gbk"dcode="utf-8" function Usage(){ cat << EOFUsage: conv [OPTIONS] [DIR][-u] GBK to UTF-8[-g] UTF-8 to GBKEOF exit 1} #将当前目录下所有普通文