MySQL数据库查询之多表查询总结
目录
- 多表关系
- 表与表之间的联系:
- 一对多(多对一)
- 多对多
- 一对一
- 多表查询
- 多表查询的分类
- 1.连接查询:
- 2.子查询
- 内连接
- 外连接
- 自连接
- 联合查询
- 子查询
- 标量子查询
- 列子查询
- 行子查询
- 表子查询
- 多表查询案例
- 总结
多表关系
在进行数据库表结构的设计时,会根据业务的需求和业务模块之间的关系,分析设计表结构,由于业务之间相互关联,所以各个表结构之间也存在各种联系
表与表之间的联系:
1.一对多(多对一)
2.多对多
3.一对一
一对多(多对一)
例如,一个员工对应一个部门,一个部门可以对应多个员工
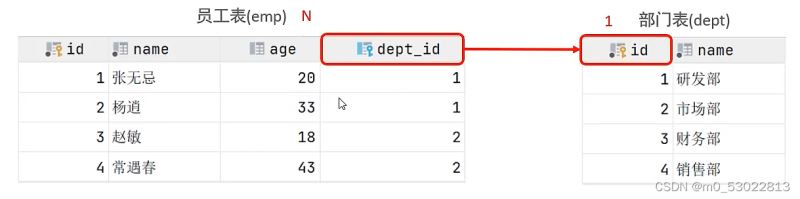
一般在多的一方创建外键,指向一的那一方
员工与部门,在员工表上设置外键,指向部门表
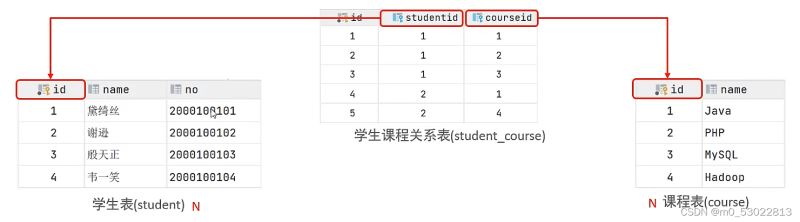
多对多
例如,一个学生可以选修多门课程,一个课程可以被多名学生选修
一般会建立第三张表,至少包含两个外键,分别指向两张表的主键
一对一
例如,用户和自己的学历信息的关系,一个人只对应一条学历信息
可以在任意一方加入外键,关联另一方的主键,并且设置外键为唯一(unique)
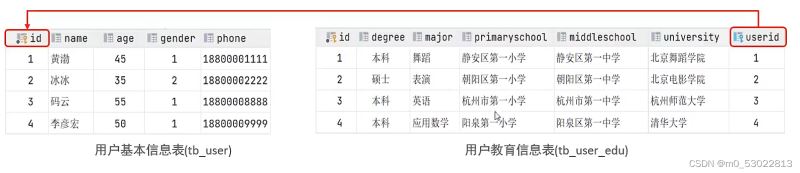
注:可以放在一张表中,但是对其进行拆分,一张表放基础信息,另一张表放详情,可以提升操作效率
多表查询
概述:
从多张表中查询数据
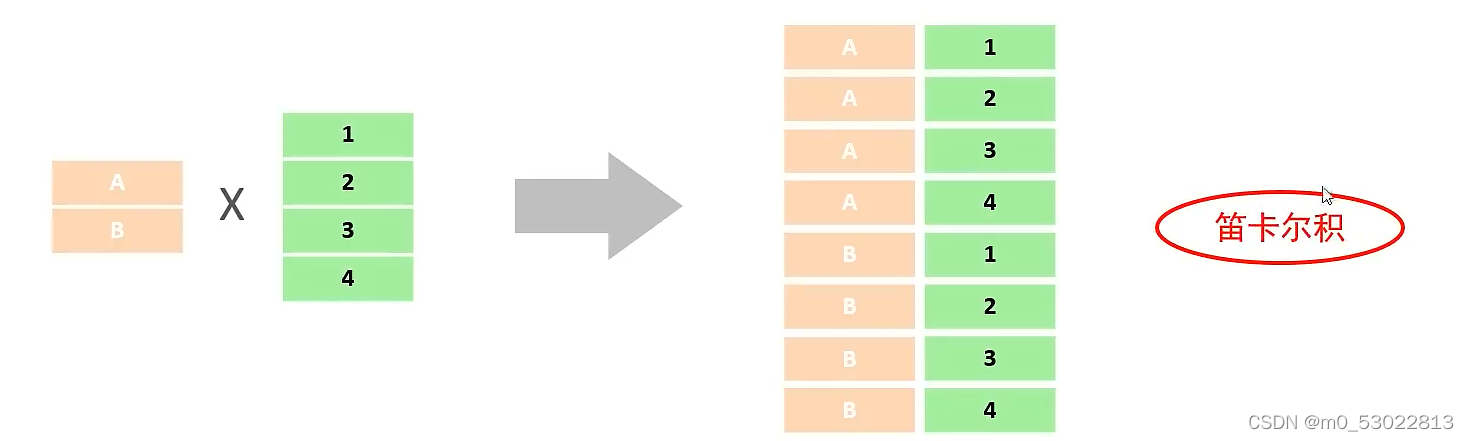
笛卡尔积:
笛卡尔积为两个集合(两张表)中的每条数据进行两两组合的结果
在多表查询时会产生笛卡尔积,要通过添加条件消除笛卡尔积
dept表:
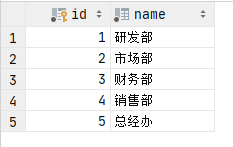
emp表:

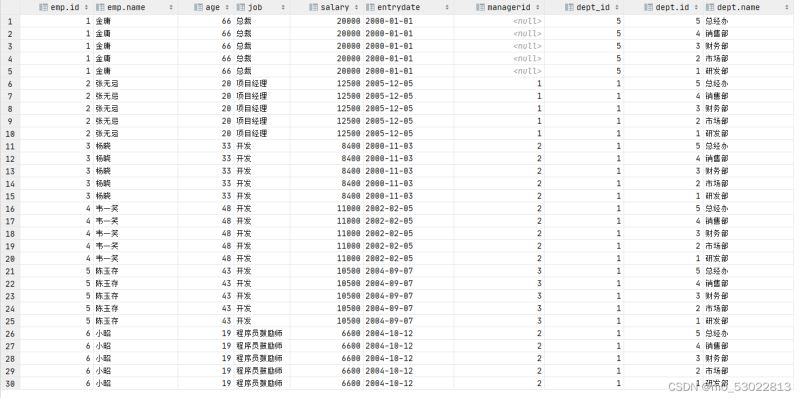
查询产生笛卡尔积的结果:
select * from emp, dept where emp.dept_id=dept.id;
消除笛卡尔积(添加条件):
select * from emp, dept where emp.dept_id=dept.id;

多表查询的分类
1.连接查询:
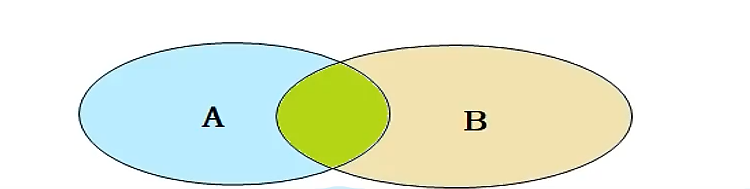
内连接:
相当于查询AB的交集部分
外连接:
左外连接:
查询A的所有数据,同时拼接上B对应的数据
右外连接:
查询B的所有数据,同时拼接上A中对应的数据
自连接:
表与自身连接查询
自连接必须给表取别名
2.子查询
数据准备
部门表:
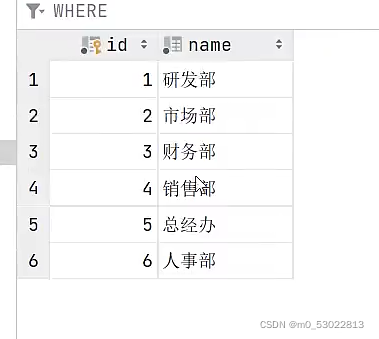
create table dept (
id int auto_increment primary key comment 'id',
name varchar(50) not null comment '部门名称'
) comment '部门表';
insert into dept (id, name)
values (1, '研发部'),
(2, '市场部'),
(3, '财务部'),
(4, '销售部'),
(5, '总经办'),
(6, '人事部');
员工表:
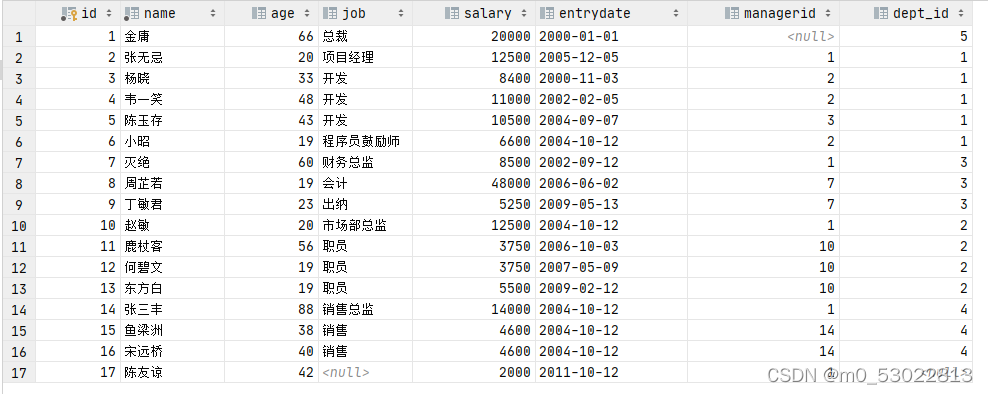
create table emp(
id int auto_increment primary key ,
name varchar(50) not null ,
age int,
job varchar(20) comment '职位',
salary int ,
entrydate date comment '入职时间',
managerid int comment '直属领导id',
dept_id int comment '所在部门id'
) comment '员工表';
insert into emp
values ( 1, '金庸', 66, '总裁', 20000, '2000-01-01', null, 5 ),
( 2, '张无忌', 20, '项目经理', 12500, '2005-12-05', 1, 1 ),
( 3, '杨晓', 33, '开发', 8400, '2000-11-03', 2, 1 ),
( 4, '韦一笑', 48, '开发', 11000, '2002-02-05', 2, 1 ),
( 5, '陈玉存', 43, '开发', 10500, '2004-09-07', 3, 1 ),
( 6, '小昭', 19, '程序员鼓励师', 6600, '2004-10-12', 2, 1 ),
( 7, '灭绝', 60, '财务总监', 8500, '2002-09-12', 1, 3 ),
( 8, '周芷若', 19, '会计', 48000, '2006-06-02', 7, 3 ),
( 9, '丁敏君', 23, '出纳', 5250, '2009-05-13', 7, 3 ),
( 10, '赵敏', 20, '市场部总监', 12500, '2004-10-12', 1, 2 ),
( 11, '鹿杖客', 56, '职员', 3750, '2006-10-03', 10, 2 ),
( 12, '何碧文', 19, '职员', 3750, '2007-05-09', 10, 2 ),
( 13, '东方白', 19, '职员', 5500, '2009-02-12', 10, 2 ),
( 14, '张三丰', 88, '销售总监', 14000, '2004-10-12', 1, 4 ),
( 15, '鱼梁洲', 38, '销售', 4600, '2004-10-12', 14, 4 ),
( 16, '宋远桥', 40, '销售', 4600, '2004-10-12', 14, 4 ),
( 17, '陈友谅', 42, null, 2000, '2011-10-12', 1, null );
内连接
语法:
# 隐式内连接 select 字段列表 from 表1,表2 where 条件; # 显示内连接 select 字段列表 from 表1 [inner] join 表2 on 连接条件;
内连接查询的是两张表交集的部分
# 查询每一个员工的姓名及关联的部门的名称 select emp.name, dept.name from emp, dept where emp.dept_id=dept.id; select emp.name, dept.name from emp inner join dept on emp.dept_id = dept.id;
外连接
语法:
# 左外连接 select 字段列表 from 表1 left [outer] join 表2 on 条件; # 右外连接 select 字段列表 from 表1 right [outer] join 表2 on 条件;
左外连接相当于查询表1的所有数据包含表1和表2交集的部分数据
右外连接相当于查询表2的所有数据包含表1和表2交集部分的数据
# 查询emp表的所有数据,和应于的部门信息(左) select emp.*, dept.* from emp left outer join dept on emp.dept_id = dept.id; # 查询dept表的所有数据,和对于的员工信息(右) select dept.*, emp.* from emp right outer join dept on emp.dept_id = dept.id;
左外连接和右外连接可以进行相互转化
自连接
语法:
select 字段列表 from 表a 别名a join 表a 别名b on 条件;
自链接查询可以是内连接查询也可以是外连接查询
# 查询员工及其所属领导的名字 # 自连接可以看成两张一样的表进行连接查询 select a.name, b.name from emp a join emp b on a.managerid=b.id;
联合查询
union、union all
对于联合查询就是把多次查询的结果合并起来,形成一个新的查询结果集
语法:
select 字段列表 from 表a union [all] select 字段列表 from 表b
# 将薪资低于5000的员工和年龄大于50的员工查询出来 select * from emp where salary>5000 union all select * from emp where age>50;
# 没有all重复满足条件的只出现一次 # 将薪资低于5000的员工和年龄大于50的员工查询出来 select * from emp where salary>5000 union select * from emp where age>50;
对于联合查询的多张表的列数必须保持一致,字段类型也要保持一致
union all会将全部的数据直接合并在一起,union会对合并之后的数据去重
子查询
概念:SQL语句中嵌套select语句为嵌套查询,又称子查询
select * from 表1 where 字段=(select 字段 from 表2);
子查询外的语句可以是insert、update、delete、select中的一个
根据子查询的结构不同,分为:
标量子查询:子查询的结果为单个值
列子查询:子查询的结果为一列
行子查询:子查询的结果为一行
表子查询:子查询的结果为多行多列
根据子查询的位置,分为:
where之后
from之后
select之后
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式,这种子查询称为标量子查询
常用符号:=、<>、>、>=、<、<=
# 根据销售部门的id查询员工信息 # 先分开查询 # 查询销售部门的id select id from dept where name='销售部'; #id为4 # 查询销售部门中员工的信息 select * from emp where dept_id=4; # 合并为一个查询 select * from emp where dept_id=(select dept.id from dept where dept.name='销售部' );
列子查询
子查询的结果为一列(可以是多行)的,这种子查询为列子查询
常用操作符:

# 列子查询 # 查询销售部和市场部的所有员工信息 # 查询销售部和市场部的id select id from dept where name='销售部' or name='市场部'; #id为2 4 # 查询两个部门的所有员工 select * from emp where dept_id in (2,4); # 合并 select * from emp where dept_id in (select id from dept where name='销售部' or name='市场部');
行子查询
子查询返回的结果是一行(可以是多列),这种子查询为行子查询
常用操作符:=、<>、in、not in
# 查询与张无忌的薪资及直属领导相同的员工信息 # 查询张无忌的薪资和直属领导 select salary, managerid from emp where name='张无忌'; # 查询与张无忌的薪资及直属领导相同的员工信息 select * from emp where (salary,managerid)=(select salary, managerid from emp where name='张无忌');
表子查询
子查询的结果是多行多列这种查询为表子查询
常用操作符:in
# 查询与鹿杖客和宋远桥的职位和薪资相同的员工信息
select * from emp where (job, salary) in ( select job, salary from emp where name in ('鹿杖客', '宋远桥'));
表子查询的子表作为临时表
# 查询入职日期是'2006-01-01‘之后的员工信息和部门信息 # 先查询出入职在'2006-01-01‘之后员工的所有信息 # 与部门表左连接 select e.*, dept.* from (select * from emp where entrydate>'2006-01-01') e left outer join dept on e.dept_id=dept.id;
多表查询案例

数据准备:
create table salgrade (
grade int,
losal int comment '本薪资等级的最低界限',
hisal int comment '最高界限'
) comment '薪资等级表';
insert into salgrade values (1,0,3000);
insert into salgrade values (2,3001,5000);
insert into salgrade values (3,5001,8000);
insert into salgrade values (4,8001,10000);
insert into salgrade values (5,10001,15000);
insert into salgrade values (6,15001,20000);
insert into salgrade values (7,20001,25000);
insert into salgrade values (8,025001,30000);
1.查询员工的姓名,年龄,职位,部门信息(隐式内连接)
select e.name, e.age, e.job, d.* from emp e, dept d where e.dept_id=d.id;
2.查询年龄小于30的员工的姓名、年龄、职位、部门信息(显示内连接)
select e.name,e.age,e.job,d.* from emp e inner join dept d on e.dept_id = d.id where e.age<30;
3.查询拥有员工的部门id,部门名称
select distinct d.id,d.name from emp e, dept d where d.id=e.dept_id;
4.查询所有年龄大于40的员工,及其归属部门名称,如果员工没有分配部门也要显示
select e.*,d.name from emp e left outer join dept d on e.dept_id = d.id where e.age>40;
5.查询所有员工的工资等级
select e.*,s.grade from emp e, salgrade s where e.salary between s.losal and s.hisal;
6.查询研发部所有员工的信息即工资等级
select e.*,s.grade from emp e,dept d,salgrade s where (e.dept_id=d.id) and (d.name='研发部') and (e.salary between s.losal and s.hisal);
7.查询研发部员工的平均工资
select avg(e.salary) from emp e, dept d where e.dept_id=d.id and d.name='研发部';
8.查询工资比灭绝高的员工信息
select *
from emp
where emp.salary > (
select e.salary
from emp e
where e.name='灭绝'
);
9.查询比平均薪资高的员工信息
select *
from emp
where salary> (
select avg(e.salary)
from emp e
);
10.查询低于本部门平均工资的员工信息
select *
from emp
where emp.salary<(
select avg(salary)
from emp e
where e.dept_id=emp.dept_id
);
11.查询所有部门信息,并统计部门的员工人数
select d.*, (
select count(*)
from emp
where emp.dept_id=d.id
)
from dept d;

总结
到此这篇关于MySQL数据库查询之多表查询的文章就介绍到这了,更多相关MySQL多表查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL多表查询的具体实例
一 使用SELECT子句进行多表查询 SELECT 字段名 FROM 表1,表2 - WHERE 表1.字段 = 表2.字段 AND 其它查询条件 SELECT a.id,a.name,a.address,a.date,b.math,b.english,b.chinese FROM tb_demo065_tel AS b,tb_demo065 AS a WHERE a.id=b.id 注:在上面的的代码中,以两张表的id字段信息相同作为条件建立两表关联,但在实际开发中不应该这样使用,最好用主外键
-
MySQL多表查询实例详解【链接查询、子查询等】
本文实例讲述了MySQL多表查询.分享给大家供大家参考,具体如下: 准备工作:准备两张表,部门表(department).员工表(employee) create table department( id int, name varchar(20) ); create table employee( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'ma
-
MySQL 多表查询实现分析
我们继续使用前面的例子.前面建立的表中包含了员工的一些基本信息,如姓名.性别.出生日期.出生地.我们再创建一个表,该表用于描述员工所发表的文章,内容包括作者姓名.文章标题.发表日期. 1.查看第一个表 mytable 的内容: mysql> select * from mytable; +----------+------+------------+-----------+ | name | sex | birth | birthaddr | +----------+------+-------
-

MySQL 四种连接和多表查询详解
目录 MySQL 内连接.左连接.右连接.外连接.多表查询 构建环境: 一.INNER JION 内连接 ( A ∩ B ) 二.LEFT JOIN 左外连接( A 全有 ) 三.RIGHT JOIN 右外连接 (B 全有) 四.FULL JOIN 全外连接( A + B) 五.LEFT Excluding JOIN ( A - B 即 A 表独有)+ 六.RIGHT Excluding JOIN ( B - A 即 B表独有) 七.OUTER Excluding JOIN (A 与 B 各自独
-
MySQL数据库高级查询和多表查询
MySQL多表查询 添加练习表 -- 用户表(user) CREATE TABLE `user`( `id` INT AUTO_INCREMENT PRIMARY KEY COMMENT '用户id(主键)', `username` VARCHAR(50) COMMENT '用户姓名', `age` CHAR(3) COMMENT '用户年龄' ); -- 订单表(orders) CREATE TABLE `orders`( `id` INT AUTO_INCREMENT PRIMARY KEY
-
mysql多表查询的几种分类详细
目录 分类1:等值连接vs非等值连接 1.等值连接 2.非等值连接 分类2:自连接vs非自连接 分类3:内连接vs外连接 总结: 多表查询分类 分类1:等值连接 vs 非等值连接 1. 等值连接 SELECT employees.employee_id, employees.last_name, employees.department_id, departments.department_id, departments.location_id FROM employees, departmen
-
解析Mysql多表查询的实现
查询是数据库的核心,下面就为您介绍Mysql多表查询时如何实现的,如果您在Mysql多表查询方面遇到过问题,不妨一看.Mysql多表查询: 复制代码 代码如下: CREATE TABLE IF NOT EXISTS contact( contact_id int(11) NOT NULL AUTO_INCREMENT, user_name varchar(255), nom varchar(255), prenom varchar(255), mail varchar(64), passcode
-
MySQL多表查询详解上
时光在不经意间,总是过得出奇的快.小暑已过,进入中暑,太阳更加热烈的绽放着ta的光芒,...在外面被太阳照顾的人们啊,你们都是勤劳与可爱的人啊.在房子里已各种姿势看我这篇这章的你,既然点了进来,那就由我继续带你回顾MySql的知识吧! 回顾练习资料girls库以及两张表的脚本: 链接: https://pan.baidu.com/s/1bgFrP7dBBwk3Ao755pU4Qg 提取码: ihg7 引题:笛卡尔现象,先来观看一下两张表. SELECT * FROM boys; SELECT *
-
MySQL数据库查询之多表查询总结
目录 多表关系 表与表之间的联系: 一对多(多对一) 多对多 一对一 多表查询 多表查询的分类 1.连接查询: 2.子查询 内连接 外连接 自连接 联合查询 子查询 标量子查询 列子查询 行子查询 表子查询 多表查询案例 总结 多表关系 在进行数据库表结构的设计时,会根据业务的需求和业务模块之间的关系,分析设计表结构,由于业务之间相互关联,所以各个表结构之间也存在各种联系 表与表之间的联系: 1.一对多(多对一) 2.多对多 3.一对一 一对多(多对一) 例如,一个员工对应一个部门,一个部门可以
-
Mysql数据库性能优化之子查询
记得在做项目的时候, 听到过一句话, 尽量不要使用子查询, 那么这一篇就来看一下, 这句话是否是正确的. 那在这之前, 需要介绍一些概念性东西和mysql对语句的大致处理. 当Mysql Server的连接线程接收到Client发送过来的SQL请求后, 会经过一系列的分解Parse, 进行相应的分析, 然后Mysql会通过查询优化器模块, 根据该Sql所涉及到的数据表的相关统计信息进行计算分析. 然后在得出一个Mysql自认为最合理最优化的数据访问方式, 也就是我们常说的"执行计划",
-
MySQL 数据库 like 语句通配符模糊查询小结
MySQL 报错:Parameter index out of range (1 > number of parameters, which is 0)--MySQL 数据库 like 语句通配符模糊查询小结 前言 今天在使用MySQL语句执行增删改查操作时,控制台报出了以下错误:Parameter index out of range (1 > number of parameters, which is 0).翻译过来意思就是:查到结果数据为1,真实值应为0,参数越界,产生错误.如此也就明
-
MySQL数据库优化之分表分库操作实例详解
本文实例讲述了MySQL数据库优化之分表分库操作.分享给大家供大家参考,具体如下: 分表分库 垂直拆分 垂直拆分就是要把表按模块划分到不同数据库表中(当然原则还是不破坏第三范式),这种拆分在大型网站的演变过程中是很常见的.当一个网站还在很小的时候,只有小量的人来开发和维护,各模块和表都在一起,当网站不断丰富和壮大的时候,也会变成多个子系统来支撑,这时就有按模块和功能把表划分出来的需求.其实,相对于垂直切分更进一步的是服务化改造,说得简单就是要把原来强耦合的系统拆分成多个弱耦合的服务,通过服务间的
-
Mysql数据库分库和分表方式(常用)
本文主要给大家介绍Mysql数据库分库和分表方式(常用),涉及到mysql数据库相关知识,对mysql数据库分库分表相关知识感兴趣的朋友一起学习吧 1 分库 1.1 按照功能分库 按照功能进行分库.常见的分成6大库: 1 用户类库:用于保存了用户的相关信息.例如:db_user,db_system,db_company等. 2 业务类库:用于保存主要业务的信息.比如主要业务是笑话,用这个库保存笑话业务.例如:db_joke,db_temp_joke等. 3 内存类库:主要用Mysql的内存引擎.
-
解决MySQL数据库意外崩溃导致表数据文件损坏无法启动的问题
问题故障: MySQL数据库意外崩溃,一直无法启动数据库. 报错日志: 启动报错:service mysqld restart ERROR! MySQL server PID file could not be found! Starting MySQL. ERROR! The server quit without updating PID file (/www/wdlinux/mysql/var/iZ2358oz5deZ.pid). 数据库error日志: 200719 22:07:43 I
-
MySQL数据库线上修改表结构的方法
目录 一.MDL元数据锁 1.什么是MDL锁 2.MDL锁的问题 二.如何线上修改MySQL表结构 一.MDL元数据锁 在修改表结构之前,先来看下可能存在的问题. 1.什么是MDL锁 MySQL有一个把锁,叫做MDL元数据锁,当对表修改的时候,会自动给表加上这把锁,也就是不需要自己显式使用. 当对表做增删改查的时候,加的是MDL读锁 当对表结构做变更修改的时候,加的是MDL写锁 读与读之间不互斥,读与写,写与写之间互斥,因此 当有一个线程对表执行增删盖茶的时候,会阻塞掉别的线程对表结构修改的请求
-
一文理解MySQL数据库的约束与表的设计
目录 1.数据库约束 1.1 约束类型 1.2 null 约束 1.3 unique 唯一的约束 1.4 default 默认值约束 1.5 primary key 主键约束 1.6 primary key auto_increment 自增主键 1.7 foreign key 外键约束 2.表的设计 2.1 一对一 2.2 一对多 2.3 多对多 总结 1.数据库约束 约束是关系型数据库提供的一种校验数据合法性的机制. 1.1 约束类型 约束类型 说明 示例 null 使用not null 指
-
MYSQL数据库中的现有表增加新字段(列)
复制代码 代码如下: ALTER TABLE `数据库名`.`表名` ADD COLUMN `PROCID` VARCHAR(6) DEFAULT '' AFTER `PPIDChanged`; --在MYSQL中,如果是表名,数据库名,列名,在你增加,修改,更新的时候都需要使用ESC键盘下的重音符号,才可以添加,相应的列名或者更新修改. 当然现在大多都是用phpmyadmin或mysql图形化操作工具,更方法,这样的是临时使用的,或没有图形界面的方法.大家可以使用上述的图形化工具操作. 下面推