Python爬虫爬取电影票房数据及图表展示操作示例
本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作。分享给大家供大家参考,具体如下:
爬虫电影历史票房排行榜 http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0
- Python爬取历史电影票房纪录
- 解析Json数据
- 横向条形图展示
- 面向对象思想
导入相关库
import requests import re from matplotlib import pyplot as plt from matplotlib import font_manager import json
类代码部分
class DYOrder(object):
#初始化
def __init__(self,page=1):
self.url = 'http://www.cbooo.cn/BoxOffice/getInland?pIndex={}&t=0'.format(page)
self.headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'}
#请求
def __to_request(self):
response = requests.get(url=self.url,headers=self.headers)
return self.__to_parse(response.content.decode('utf-8'))
#解析
def __to_parse(self,html):
#返回为JSON字符串
#首先将字符串反序列化为JSON对象
my_json = json.loads(html)
return my_json
#图表展示
def __to_show(self,data,show_type):
x = []
y = []
for value in data:
x.append(value['MovieName'])
y.append(int(value['BoxOffice']))
my_font = font_manager.FontProperties(fname='/System/Library/Fonts/PingFang.ttc',size=18)
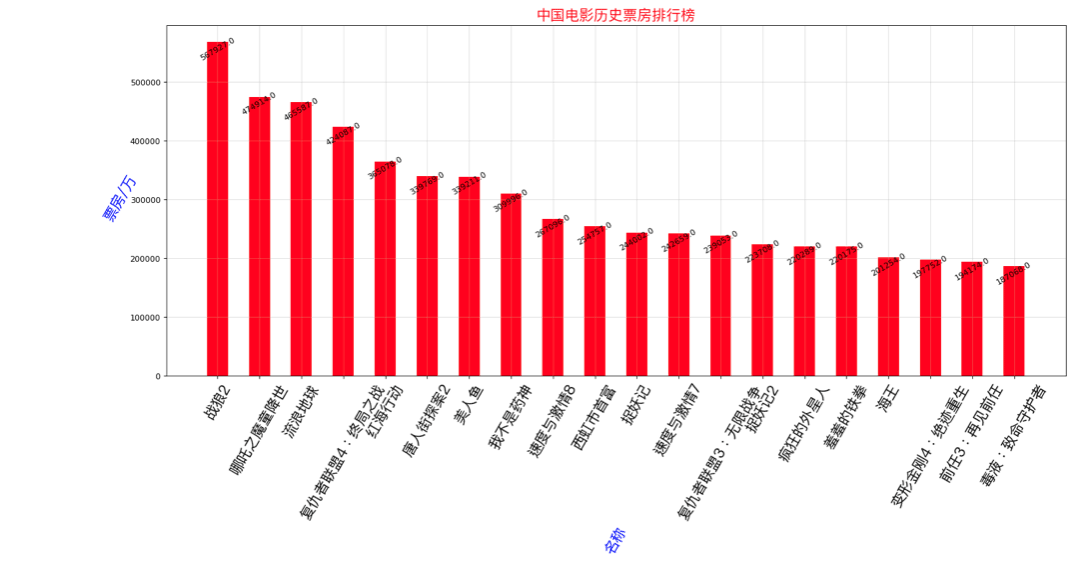
if show_type == 1:
plt.figure(figsize=(20,8),dpi=80)
rects = plt.bar(range(len(x)),[float(i) for i in y],width=0.5,color='red')
plt.xticks(range(len(x)),x,fontproperties=my_font,rotation=60)
plt.xlabel('名称',rotation=60,color='blue',fontproperties=my_font)
plt.ylabel('票房/万',rotation=60,color='blue',fontproperties=my_font)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width()/2,height+0.4,str(height),ha='center',rotation=30)
else:
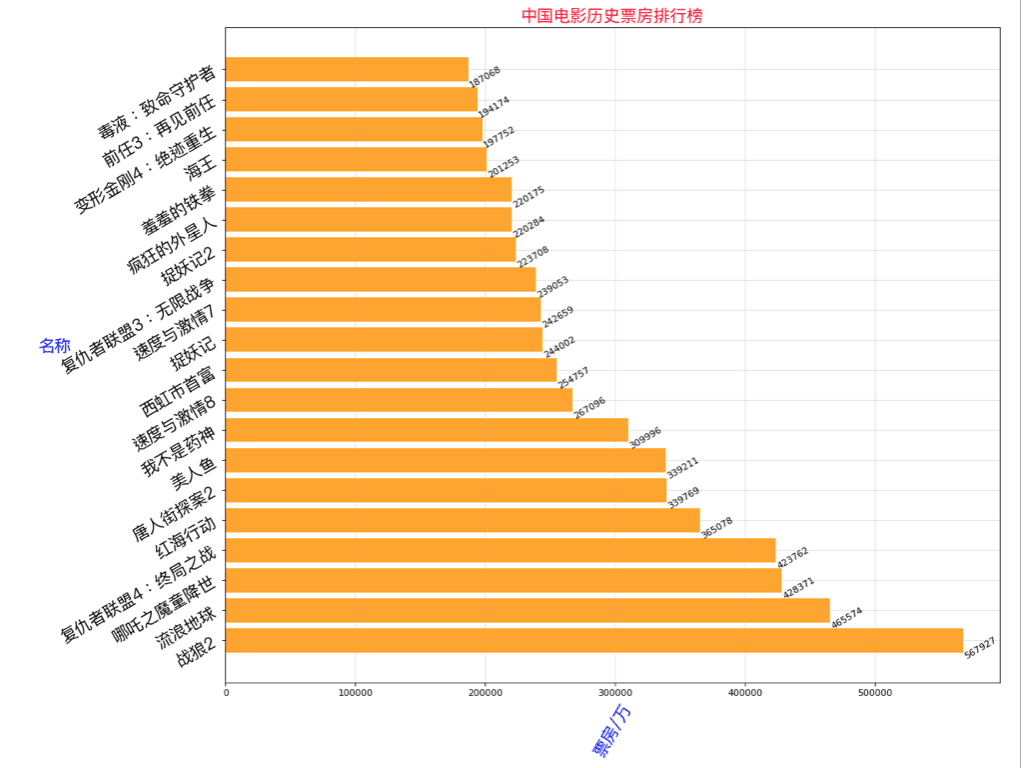
# 横向 plt.barh(y,x)
plt.figure(figsize=(15,13),dpi=80)
rects = plt.barh(range(len(x)),y,height=0.8,color='orange')
plt.yticks(range(len(x)),x,fontproperties=my_font,rotation=30)
plt.ylabel('名称',rotation=0,color='blue',fontproperties=my_font)
plt.xlabel('票房/万',rotation=60,color='blue',fontproperties=my_font)
for rect in rects:
width = rect.get_width()
plt.text(width, rect.get_y()+0.3/2,str(width),va='center',rotation=30)
plt.grid(alpha=0.4)
plt.title('中国电影历史票房排行榜',color='red',size=18,fontproperties=my_font)
plt.show()
#所有操作
def to_run(self,show_type=1):
result = self.__to_request()
self.__to_show(result,show_type)
调用类并展示
if __name__ == '__main__': dy_order = DYOrder(1) # type 1 竖向条形图 2 横向 dy_order.to_run(2)
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-
Python爬虫爬取杭州24时温度并展示操作示例
本文实例讲述了Python爬虫爬取杭州24时温度并展示操作.分享给大家供大家参考,具体如下: 散点图 爬虫杭州今日24时温度 https://www.baidutianqi.com/today/58457.htm 利用正则表达式爬取杭州温度 面向对象编程 图表展示(散点图 / 折线图) 导入相关库 import requests import re from matplotlib import pyplot as plt from matplotlib import font_manager i
-
python 爬虫 实现增量去重和定时爬取实例
前言: 在爬虫过程中,我们可能需要重复的爬取同一个网站,为了避免重复的数据存入我们的数据库中 通过实现增量去重 去解决这一问题 本文还针对了那些需要实时更新的网站 增加了一个定时爬取的功能: 本文作者同开源中国(殊途同归_): 解决思路: 1.获取目标url 2.解析网页 3.存入数据库(增量去重) 4.异常处理 5.实时更新(定时爬取) 下面为数据库的配置 mysql_congif.py: import pymysql def insert_db(db_table, issue, time_s
-
python爬虫爬取监控教务系统的思路详解
这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本. 设计思路: 设计思路很简单,首先对已有的成绩进行处理,变为list集合,然后定时爬取教务系统查成绩的页面,对爬取的成绩也处理成list集合,如果newList的长度增加了,就找出增加的部分,并通过邮件通知我. 脚本运行效果: 服务器: 发送邮件通知: 代码如下: import datetime import time from email.header import Header impor
-

python爬虫 爬取58同城上所有城市的租房信息详解
代码如下 from fake_useragent import UserAgent from lxml import etree import requests, os import time, re, datetime import base64, json, pymysql from fontTools.ttLib import TTFont ua = UserAgent() class CustomException(Exception): def __init__(self, statu
-
python爬虫 2019中国好声音评论爬取过程解析
2019中国好声音火热开播,作为一名"假粉丝",这一季每一期都刷过了,尤其刚播出的第六期开始正式的battle.视频视频看完了,那看下大家都是怎样评论的. 1.网页分析部分 本文爬取的是腾讯视频评论,第六期的评论地址是:http://coral.qq.com/4093121984 每页有10条评论,点击"查看更多评论",可将新的评论加载进来,通过多次加载,可以发现我们要找的评论就在以v2开头的js类型的响应中. 请求为GET请求,地址是http://coral.qq
-
Python爬虫爬取Bilibili弹幕过程解析
先来思考一个问题,B站一个视频的弹幕最多会有多少? 比较多的会有2000条吧,这么多数据,B站肯定是不会直接把弹幕和这个视频绑在一起的. 也就是说,有一个视频地址为https://www.bilibili.com/video/av67946325,你如果直接去requests.get这个地址,里面是不会有弹幕的,回想第一篇说到的携程异步加载数据的方式,B站的弹幕也一定是先加载当前视频的界面,然后再异步填充弹幕的. 接下来我们就可以打开火狐浏览器(平常可以火狐谷歌控制台都使用,因为谷歌里面因为插件
-
Python爬虫爬取、解析数据操作示例
本文实例讲述了Python爬虫爬取.解析数据操作.分享给大家供大家参考,具体如下: 爬虫 当当网 http://search.dangdang.com/?key=python&act=input&page_index=1 获取书籍相关信息 面向对象思想 利用不同解析方式和存储方式 引用相关库 import requests import re import csv import pymysql from bs4 import BeautifulSoup from lxml import e
-
python爬虫开发之使用python爬虫库requests,urllib与今日头条搜索功能爬取搜索内容实例
使用python爬虫库requests,urllib爬取今日头条街拍美图 代码均有注释 import re,json,requests,os from hashlib import md5 from urllib.parse import urlencode from requests.exceptions import RequestException from bs4 import BeautifulSoup from multiprocessing import Pool #请求索引页 d
-
python爬虫爬取笔趣网小说网站过程图解
首先:文章用到的解析库介绍 BeautifulSoup: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能. 它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序. Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码. 你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了.然后,你仅仅
-
Python爬虫实现使用beautifulSoup4爬取名言网功能案例
本文实例讲述了Python爬虫实现使用beautifulSoup4爬取名言网功能.分享给大家供大家参考,具体如下: 爬取名言网top10标签对应的名言,并存储到mysql中,字段(名言,作者,标签) #! /usr/bin/python3 # -*- coding:utf-8 -*- from urllib.request import urlopen as open from bs4 import BeautifulSoup import re import pymysql def find_
-
python爬虫之爬取百度音乐的实现方法
在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法.对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同.在上次爬虫中,每一类数据都要从其父类(包括其父节点的父节点)上往下寻找ROI数据所在的子节点,这样就会使爬虫很臃肿,因为很多数据有相同的父节点,每次都要重复的找到这个父节点.这样的爬虫效率很低. 因此,笔者在上次的基础上,改进了一下爬取的策略,笔者以