爬虫进阶-JS自动渲染之Scrapy_splash组件的使用
目录
- 1. 什么是scrapy_splash?
- 2. scrapy_splash的作用
- 3. scrapy_splash的环境安装
- 3.1 使用splash的docker镜像
- 3.2 在python虚拟环境中安装scrapy-splash包
- 4. 在scrapy中使用splash
- 4.1 创建项目创建爬虫
- 4.2 完善settings.py配置文件
- 4.3 不使用splash
- 4.4 使用splash
- 4.5 分别运行俩个爬虫,并观察现象
- 4.6 结论
- 5. 了解更多
- 6. 小结
1. 什么是scrapy_splash?
scrapy_splash是scrapy的一个组件
- scrapy-splash加载js数据是基于Splash来实现的。
- Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python和Lua语言实现的,基于Twisted和QT等模块构建。
- 使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后的网页源代码。
splash官方文档
https://splash.readthedocs.io/en/stable/
2. scrapy_splash的作用
scrapy-splash能够模拟浏览器加载js,并返回js运行后的数据
3. scrapy_splash的环境安装
3.1 使用splash的docker镜像
splash的dockerfile
https://github.com/scrapinghub/splash/blob/master/Dockerfile
观察发现splash依赖环境略微复杂,所以我们可以直接使用splash的docker镜像
如果不使用docker镜像请参考splash官方文档 安装相应的依赖环境
3.1.1 安装并启动docker服务
安装参考 https://www.jb51.net/article/213611.htm
3.1.2 获取splash的镜像
在正确安装docker的基础上pull取splash的镜像
sudo docker pull scrapinghub/splash
3.1.3 验证是否安装成功
运行splash的docker服务,并通过浏览器访问8050端口验证安装是否成功
- 前台运行
sudo docker run -p 8050:8050 scrapinghub/splash - 后台运行
sudo docker run -d -p 8050:8050 scrapinghub/splash
访问http://127.0.0.1:8050 看到如下截图内容则表示成功

3.1.4 解决获取镜像超时:修改docker的镜像源
以ubuntu18.04为例
1.创建并编辑docker的配置文件
sudo vi /etc/docker/daemon.json
2.写入国内docker-cn.com的镜像地址配置后保存退出
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
3.重启电脑或docker服务后重新获取splash镜像
4.这时如果还慢,请使用手机热点(流量orz)
3.1.5 关闭splash服务
需要先关闭容器后,再删除容器
sudo docker ps -a sudo docker stop CONTAINER_ID sudo docker rm CONTAINER_ID
3.2 在python虚拟环境中安装scrapy-splash包
pip install scrapy-splash
4. 在scrapy中使用splash
以baidu为例
4.1 创建项目创建爬虫
scrapy startproject test_splash cd test_splash scrapy genspider no_splash baidu.com scrapy genspider with_splash baidu.com
4.2 完善settings.py配置文件
在settings.py文件中添加splash的配置以及修改robots协议
# 渲染服务的url
SPLASH_URL = 'http://127.0.0.1:8050'
# 下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
4.3 不使用splash
在spiders/no_splash.py中完善
import scrapy
class NoSplashSpider(scrapy.Spider):
name = 'no_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=13161933309']
def parse(self, response):
with open('no_splash.html', 'w') as f:
f.write(response.body.decode())
4.4 使用splash
import scrapy
from scrapy_splash import SplashRequest # 使用scrapy_splash包提供的request对象
class WithSplashSpider(scrapy.Spider):
name = 'with_splash'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?wd=13161933309']
def start_requests(self):
yield SplashRequest(self.start_urls[0],
callback=self.parse_splash,
args={'wait': 10}, # 最大超时时间,单位:秒
endpoint='render.html') # 使用splash服务的固定参数
def parse_splash(self, response):
with open('with_splash.html', 'w') as f:
f.write(response.body.decode())
4.5 分别运行俩个爬虫,并观察现象
4.5.1 分别运行俩个爬虫
scrapy crawl no_splash scrapy crawl with_splash
4.5.2 观察获取的俩个html文件
不使用splash
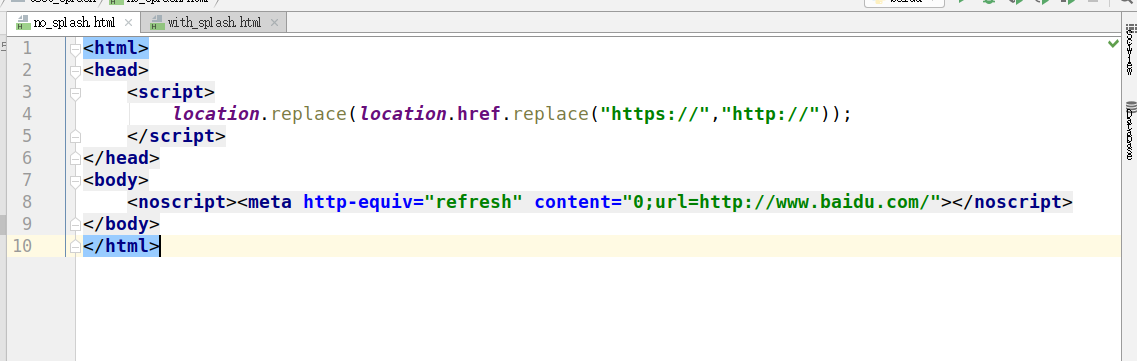
使用splash

4.6 结论
- splash类似selenium,能够像浏览器一样访问请求对象中的url地址
- 能够按照该url对应的响应内容依次发送请求
- 并将多次请求对应的多次响应内容进行渲染
- 最终返回渲染后的response响应对象
5. 了解更多
关于splash https://www.jb51.net/article/219166.htm
关于scrapy_splash(截屏,get_cookies等)
https://www.e-learn.cn/content/qita/800748
6. 小结
1.scrapy_splash组件的作用
- splash类似selenium,能够像浏览器一样访问请求对象中的url地址
- 能够按照该url对应的响应内容依次发送请求
- 并将多次请求对应的多次响应内容进行渲染
- 最终返回渲染后的response响应对象
2.scrapy_splash组件的使用
- 需要splash服务作为支撑
- 构造的request对象变为splash.SplashRequest
- 以下载中间件的形式使用
- 需要scrapy_splash特定配置
3.scrapy_splash的特定配置
SPLASH_URL = 'http://127.0.0.1:8050'
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
到此这篇关于爬虫进阶-JS自动渲染之Scrapy_splash组件的使用的文章就介绍到这了,更多相关js Scrapy_splash组件使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

scrapy-splash简单使用详解
1.scrapy_splash是scrapy的一个组件 scrapy_splash加载js数据基于Splash来实现的 Splash是一个Javascrapy渲染服务,它是一个实现HTTP API的轻量级浏览器,Splash是用Python和Lua语言实现的,基于Twisted和QT等模块构建 使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后的网页源代码 2.scrapy_splash的作用 scrpay_splash能够模拟浏览器加载js,并返回js运行
-
爬虫进阶-JS自动渲染之Scrapy_splash组件的使用
目录 1. 什么是scrapy_splash? 2. scrapy_splash的作用 3. scrapy_splash的环境安装 3.1 使用splash的docker镜像 3.2 在python虚拟环境中安装scrapy-splash包 4. 在scrapy中使用splash 4.1 创建项目创建爬虫 4.2 完善settings.py配置文件 4.3 不使用splash 4.4 使用splash 4.5 分别运行俩个爬虫,并观察现象 4.6 结论 5. 了解更多 6. 小结 1. 什么是s
-
scrapy爬虫遇到js动态渲染问题
目录 一.传统爬虫的问题 1.实际案例 二.scrapy解决动态网页渲染问题的策略 三.安装使用scrapy-splash 1.安装Docker 2.安装splash镜像 3.安装scrapy-splash 四.项目实践 五.总结与思考 一.传统爬虫的问题 scrapy爬虫与传统爬虫一样,都是通过访问服务器端的网页,获取网页内容,最终都是通过对于网页内容的分析来获取数据,这样的弊端就在于他更适用于静态网页的爬取,而面对js渲染的动态网页就有点力不从心了,因为通过js渲染出来的动态网页的内容与网页
-
利用node.js实现自动生成前端项目组件的方法详解
本文主要给大家介绍了关于利用node.js实现自动生成前端项目组件的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍: 脚本编写背景 写这个小脚本的初衷是,项目本身添加一个组件太繁琐了,比如我想要去建立一个login的组件,那么我需要手动去IDE中,创建index.js(组件出口文件),login.js(业务文件),login.html,login.less这四个文件.因为每个组件都有一些输出的代码,还要把之前组件的那几行拷贝过来,这种作业真的烦,于是乎写了一个小脚本去自动
-
Vue.js每天必学之组件与组件间的通信
什么是组件? 组件(Component)是 Vue.js 最强大的功能之一.组件可以扩展 HTML 元素,封装可重用的代码.在较高层面上,组件是自定义元素,Vue.js 的编译器为它添加特殊功能.在有些情况下,组件也可以是原生 HTML 元素的形式,以 is 特性扩展. 使用组件 注册 之前说过,我们可以用 Vue.extend() 创建一个组件构造器: var MyComponent = Vue.extend({ // 选项... }) 要把这个构造器用作组件,需要用 `Vue.compone
-
Python爬虫进阶Scrapy框架精文讲解
目录 一.前情提要 为什么要使用Scrapy 框架? 二.Scrapy框架的概念 三.Scrapy安装 四.Scrapy实战运用 这一串代码干了什么? 五.Scrapy的css选择器教学 按标签名选择 按 class 选择 按 id 选择 按层级关系选择 取元素中的文本 取元素的属性 一.前情提要 为什么要使用Scrapy 框架? 前两篇深造篇介绍了多线程这个概念和实战 多线程网页爬取 多线程爬取网页项目实战 经过之前的学习,我们基本掌握了分析页面.分析动态请求.抓取内容,也学会使用多线程来并发
-
vue.js,ajax渲染页面的实例
关于上次说的用vue.js,zepto,node.js,webpack等技术重构CNode.这是一个比较入门的项目,一般你学完vue就可以上手了,CNode网站有公开的API所以你可以获取这个网站的所有数据接口,然后渲染到页面上,用CSS等加工一下就可以了.起初,我一直感觉好难好难好难,虽然说不出难在哪里,就感觉好难好难好难.让我细说,不就是用ajax获取数据,然后传到组件上渲染吗,再模仿着写样式不就好了吗.是不难啊,可是为什么我心里天然觉得很难呢? CNode是给了我们数据接口,ajax也就那
-
详解Next.js页面渲染的优化方案
在过去一年的工作中我所使用的js框架是Next.js,尽管这个框架在前后端同构方面有着绝佳的体验,但是当页面js文件过大以及preload过多的时候还是会出现页面跳转卡顿和渲染阻塞等比较糟糕的用户体验问题.由于我之前既不知道这个框架的工作原理,自然也就不知道如何去优化它.乘着农历春节前工地活少所以稍微研究一下. 第一个问题:宣称前后台同构的Next.js为何会出现卡顿现象? Next.js 中的特有生命周期hook 函数 getInitialProps会在页面渲染的时候判断浏览器是否为首次渲染,
-
解决vue.js 数据渲染成功仍报错的问题
最近在做一个vue项目,用的是官方推荐的axios请求数据,数据结构是一级对象嵌套二级对象,发现一级对象数据渲染不报错,二级数据渲染报错.很是郁闷!data函数如下 export default { name: 'hello', data() { return { card:{} } } } 返回的数据如下: { "object":{ "subObject":"123", ... } } 报错的原因是在data函数return的card里没有二级
-
Vue.js桌面端自定义滚动条组件之美化滚动条VScroll
前言 前段时间有给大家分享一个vue桌面端弹框组件,今天再分享最近开发的一个vue pc端自定义滚动条组件. vscroll 一款基于vue2.x开发的网页端轻量级超小巧自定义美化滚动条组件.支持是否原生滚动条.鼠标移出是否自动隐藏.自定义滚动条尺寸及颜色等功能. 组件在设计开发之初借鉴了 el-scrollbar 及 vuebar 等组件设计思想. 通过简单的标签写法<v-scroll>...</v-scroll> 即可快速生成一个漂亮的替换原生滚动条. 参数配置 props:
-
Python爬虫进阶之爬取某视频并下载的实现
这几天在家闲得无聊,意外的挖掘到了一个资源网站(你懂得),但是网速慢广告多下载不了种种原因让我突然萌生了爬虫的想法. 下面说说流程: 一.网站分析 首先进入网站,F12检查,本来以为这种低端网站很好爬取,是我太低估了web主.可以看到我刷新网页之后,出现了很多js文件,并且响应获取的代码与源代码不一样,这就不难猜到这个网站是动态加载页面. 目前我知道的动态网页爬取的方法只有这两种:1.从网页响应中找到JS脚本返回的JSON数据:2.使用Selenium对网页进行模拟访问.源代码问题好解决,重要的