Spark简介以及与Hadoop对比分析
目录
- 1. Spark 与 Hadoop 比较
- 1.1 Haoop 的缺点
- 1.2 相较于Hadoop MR的优点
- 2. Spark 生态系统
- 2.1 大数据处理的三种类型
- 1. 复杂的批量数据处理
- 2. 基于历史数据的交互式查询
- 3. 基于实时数据流的数据处理
- 2.2 BDAS架构
- 2.3 Spark 生态系统
- 3. 基本概念与架构设计
- 3.1 基本概念
- 3.2 运行架构
- 3.3 各种概念之间的相互关系
- 4. Spark运行基本流程
- 4.1 运行流程
- 4.2 运行架构特点
- 5. Spark的部署和应用方式
- 5.1 Spark的三种部署方式
- 5.1.1 Standalone
- 5.1.2 Spark on Mesos
- 5.1.3 Spark on YARN
- 5.2 从Hadoop+Storm架构转向Spark架构
- Hadoop+Storm架构
- 用Spark架构满足批处理和流处理需求
- Spark架构的优点:
- 5.3 Hadoop和Spark的统一部署
- 不同计算框架统一运行在YARN中
1. Spark 与 Hadoop 比较
1.1 Haoop 的缺点
- 1. 表达能力有限;
- 2. 磁盘IO开销大;
- 3. 延迟高;
- 4. 任务之间的衔接涉及IO开销;
- 5. 在前一个任务执行完之前,其他任务就无法开始,难以胜任复杂、多阶段的计算任务。
1.2 相较于Hadoop MR的优点
- 1. Spark的计算模式也属于MR,但不局限于Map和Reduce操作,它还提供了多种数据集操作类型,编程模式也比Hadoop MR更灵活;
- 2. Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高;
- 3. Spark 基于DAG的任务调度执行机制,要优于Hadoop MR的迭代执行机制。
| Spark | MapReduce | |
| 数据存储结构 | 使用内存构建弹性分布式数据集RDD,对数据进行运算和cache。 | 磁盘HDFS文件系统的split |
| 编程范式 | DAG(Transformation+Action) | Map+Reduce |
| 计算中间结果的存储 | 在内存中维护,存取速度比磁盘高几个数量级 | 落到磁盘,IO及序列化、反序列化代价大 |
| Task维护方式 | 线程 | 进程 |
| 时间 | 对于小数据集读取能够达到亚秒级的延迟 | 需要数秒时间才能启动任务 |
2. Spark 生态系统
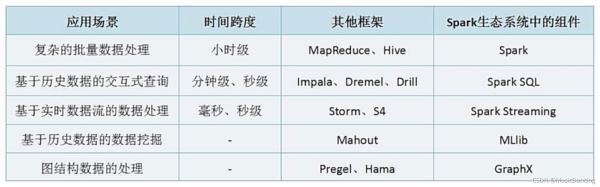
2.1 大数据处理的三种类型
1. 复杂的批量数据处理
时间跨度在数十分钟到数小时
Haoop MapReduce
2. 基于历史数据的交互式查询
时间跨度在数十秒到数分钟
Cloudera、Impala 这两者实时性均优于hive。
3. 基于实时数据流的数据处理
时间跨度在数百毫秒到数秒
Storm
2.2 BDAS架构
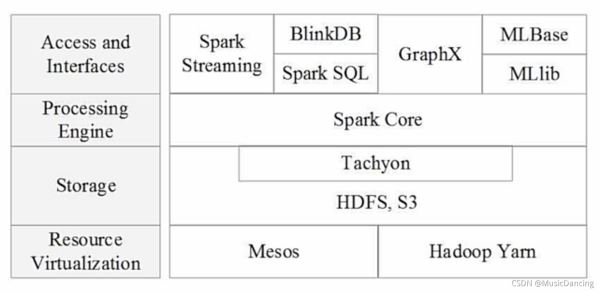
2.3 Spark 生态系统

3. 基本概念与架构设计
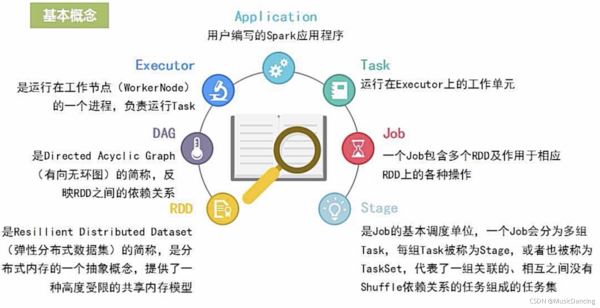
3.1 基本概念
3.2 运行架构
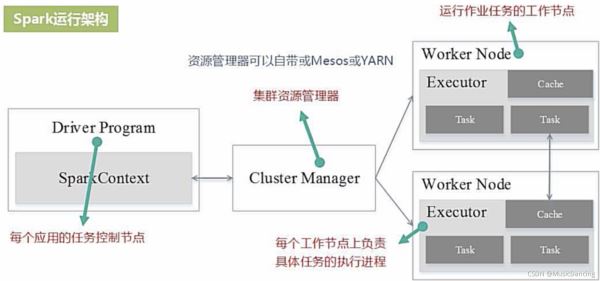
Spark采用Executor的优点:(相比于Hadoop的MR)
- 1. 利用多线程来执行具体的任务,减少任务的启动开销;
- 2. Executor中有一个BlockManager存储模块,会将内存和磁盘共同作为存储设备,有效减少IO开销。
3.3 各种概念之间的相互关系
- 一个Application由一个Driver和若干个Job构成
- 一个Job由多个Stage构成
- 一个Stage由多个没有shuffle关系的Task组成

当执行一个Application时,Driver会向集群管理器申请资源,启动Executor,
并向Executor发送应用程序代码和文件,然后在Executor上执行Task,运行结束后,
执行结果会返回给Driver,或者写到HDFS或者其他数据库中。
4. Spark运行基本流程
4.1 运行流程
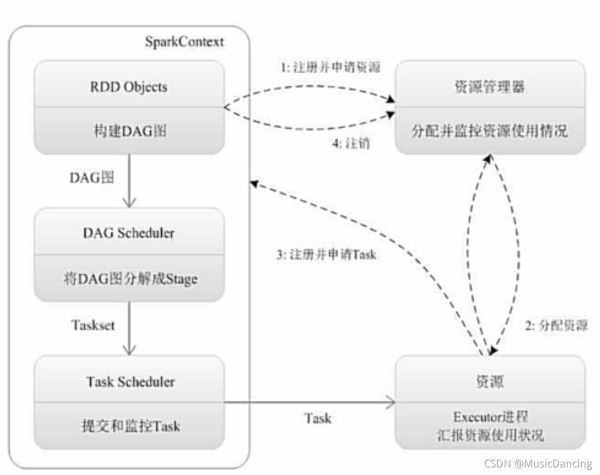
1. 为应用构建起基本的运行环境,即由Driver创建一个SparkContext进行资源的申请、任务的分配和监控。
2. 资源管理器为Executor分配资源,并启动Executor进程。
- 3.1 SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAGScheduler解析成Stage,然后把一个个TaskSet提交给底层调度器TaskScheduler处理。
- 3.2 Executor向SparkContext申请Task,TaskScheduler将Task发送给Executor运行并提供应用程序代码。
4. Task在Executor上运行把执行结果反馈给TaskScheduler,然后反馈给DAGScheduler,运行完毕后写入数据并释放所有资源。
4.2 运行架构特点
1. 每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task。
2. Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可。
3. Task采用了数据本地性和推测执行等优化机制。(计算向数据靠拢。)
5. Spark的部署和应用方式
5.1 Spark的三种部署方式
5.1.1 Standalone
类似于MR1.0,slot为资源分配单位,但性能并不好。
5.1.2 Spark on Mesos
Mesos和Spark有一定的亲缘关系。
5.1.3 Spark on YARN
mesos和yarn的联系
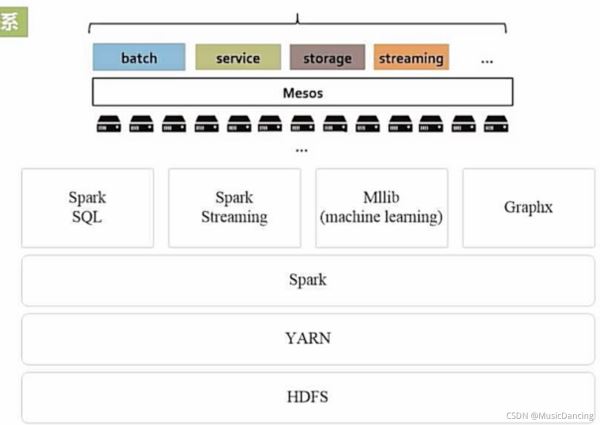
5.2 从Hadoop+Storm架构转向Spark架构
Hadoop+Storm架构
这种部署方式较为繁琐。

用Spark架构满足批处理和流处理需求

Spark用快速的小批量计算模拟流计算,并非真实的流计算。
无法实现毫秒级的流计算,对于需要毫秒级实时响应的企业应用而言,仍需采用流计算框架Storm等。
Spark架构的优点:
- 1. 实现一键式安装和配置,线程级别的任务监控和告警;
- 2. 降低硬件集群、软件维护、任务监控和应用开发的难度;
- 3. 便于做成统一的硬件、计算平台资源池。
5.3 Hadoop和Spark的统一部署
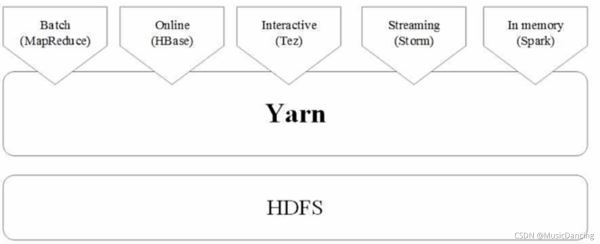
不同计算框架统一运行在YARN中
好处如下:
- 1. 计算资源按需伸缩;
- 2. 不用负载应用混搭,集群利用率高;
- 3. 共享底层存储,避免数据跨集群迁移
现状:
1. Spark目前还是无法取代Hadoop生态系统中的一些组件所实现的功能。
2. 现有的Hadoop组件开发的应用,完全迁移到Spark上需要一定的成本。
到此这篇关于Spark简介以及与Hadoop对比分析的文章就介绍到这了,更多相关Spark与Hadoop内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

linux环境不使用hadoop安装单机版spark的方法
大数据持续升温, 不熟悉几个大数据组件, 连装逼的口头禅都没有. 最起码, 你要会说个hadoop, hdfs, mapreduce, yarn, kafka, spark, zookeeper, neo4j吧, 这些都是装逼的必备技能. 关于spark的详细介绍, 网上一大堆, 搜搜便是, 下面, 我们来说单机版的spark的安装和简要使用. 0. 安装jdk, 由于我的机器上之前已经有了jdk, 所以这一步我可以省掉. jdk已经是很俗气的老生常谈了, 不多说, 用java/scala的
-
浅谈七种常见的Hadoop和Spark项目案例
有一句古老的格言是这样说的,如果你向某人提供你的全部支持和金融支持去做一些不同的和创新的事情,他们最终却会做别人正在做的事情.如比较火爆的Hadoop.Spark和Storm,每个人都认为他们正在做一些与这些新的大数据技术相关的事情,但它不需要很长的时间遇到相同的模式.具体的实施可能有所不同,但根据我的经验,它们是最常见的七种项目. 项目一:数据整合 称之为"企业级数据中心"或"数据湖",这个想法是你有不同的数据源,你想对它们进行数据分析.这类项目包括从所有来源获得
-
Spark简介以及与Hadoop对比分析
目录 1. Spark 与 Hadoop 比较 1.1 Haoop 的缺点 1.2 相较于Hadoop MR的优点 2. Spark 生态系统 2.1 大数据处理的三种类型 1. 复杂的批量数据处理 2. 基于历史数据的交互式查询 3. 基于实时数据流的数据处理 2.2 BDAS架构 2.3 Spark 生态系统 3. 基本概念与架构设计 3.1 基本概念 3.2 运行架构 3.3 各种概念之间的相互关系 4. Spark运行基本流程 4.1 运行流程 4.2 运行架构特点 5. Spark的部
-
hibernate和mybatis对比分析
第一章 Hibernate与MyBatis Hibernate 是当前最流行的O/R mapping框架,它出身于sf.net,现在已经成为Jboss的一部分. Mybatis 是另外一种优秀的O/R mapping框架.目前属于apache的一个子项目. MyBatis 参考资料官网:http://www.mybatis.org/core/zh/index.html Hibernate参考资料: http://docs.jboss.org/hibernate/core/3.6/refe
-
java原生序列化和Kryo序列化性能实例对比分析
简介 最近几年,各种新的高效序列化方式层出不穷,不断刷新序列化性能的上限,最典型的包括: 专门针对Java语言的:Kryo,FST等等 跨语言的:Protostuff,ProtoBuf,Thrift,Avro,MsgPack等等 这些序列化方式的性能多数都显著优于hessian2(甚至包括尚未成熟的dubbo序列化).有鉴于此,我们为dubbo引入Kryo和FST这 两种高效Java序列化实现,来逐步取代hessian2.其中,Kryo是一种非常成熟的序列化实现,已经在Twitter.Group
-
爬虫框架 Feapder 和 Scrapy 的对比分析
目录 一.scrapy 分析 1. 解析函数或数据入库出错,不会重试,会造成一定的数据丢失 2. 运行方式,需借助命令行,不方便调试 3. 入库 pipeline,不能批量入库 二.scrapy-redis 分析 1. redis 中的任务可读性不好 2. 取任务时直接弹出,会造成任务丢失 3. 去重耗内存 三.feapder 分析 四.三种爬虫简介 1. AirSpider 2. Spider 3. BatchSpider 五.feapder 项目结构 1. feapder 部署 六.采集效率
-
AngularJS下对数组的对比分析
Javascript不能直接用==或者===来判断两个数组是否相等,无论是相等还是全等都不行,以下两行JS代码都会返回false <script type="text/javascript"> alert([]==[]); alert([]===[]); </script> 要判断JS中的两个数组是否相同,需要先将数组转换为字符串,再作比较.以下两行代码将返回true <script type="text/javascript">
-
Perl与JS的对比分析(数组、哈希)
上一篇列出了Perl中定义数组,对象的方式与JS的异同.这里继续补充数组,哈希的相关操作. 一.数组 可以对数组进行增删,插入.与JS不同的是这些函数都是全局的,JS则是挂在Array.prototype上. 1,对数组尾部的操作pop(删除最后的元素).push(在尾部添加) @goods = qw/pen pencil/; pop(@goods); # @goods 变成 (pen) push(@goods, 'brush'); # @goods 变为 (pen, brush) 在Perl中
-
浅谈MySQL和Lucene索引的对比分析
MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr.ElasticSearch)的核心类库.两者的索引(index)有什么区别呢?以前写过一篇<Solr与MySQL查询性能对比>,只是简单的对比了下查询性能,对于内部原理却没有解释,本文简单分析下两者的索引区别. MySQL索引实现 在MySQL中,索引属于存储引擎级别的概念,不同存储引擎对索引的实现方式是不同的,本文主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式. M
-
Oracle不同数据库间对比分析脚本
正在看的ORACLE教程是:Oracle不同数据库间对比分析脚本. Oracle数据库开发应用中经常对数据库管理员有这样的需求,对比两个不同实例间某模式下对象的差异或者对比两个不同实例某模式下表定义的差异性,这在涉及到数据库软件的开发应用中是经常遇到的.一般数据库软件的开发都是首先在开发数据库上进行,开发到一定程度后,系统投入运行,此时软件处于维护阶段.针对在系统运行中遇到的错误.bug等,还有应用系统的升级,经常需要调整后台程序,数据库开发人员经常遇到这样一种尴尬的事情,维护到一定时期,开发库
-
对比分析Django的Q查询及AngularJS的Datatables分页插件
使用Q查询,首先要导入Q模块: from django.db.models import Q 可以组合使用&,|操作符用于多个Q的对象,产生一个新的Q对象,Q对象也可以用~操作符放在前面表示否定,如下例所示: if search: keywords_list = search.split(' ') query_list = [Q(status__icontains=get_success_fail_status(keyword)) if get_success_fail_keyword_stat
-
php中随机函数mt_rand()与rand()性能对比分析
本文实例对比分析了php中随机函数mt_rand()与rand()性能问题.分享给大家供大家参考.具体分析如下: 在php中mt_rand()和rand()函数都是可以随机生成一个纯数字的,他们都是需要我们设置好种子数据然后生成,那么mt_rand()和rand()那个性能会好一些呢,下面我们带着疑问来测试一下. 例子1. mt_rand() 范例,代码如下: 复制代码 代码如下: <?php echo mt_rand() . "n"; echo mt_rand() . &quo