elasticsearch元数据构建metadata及routing类源码分析
目录
- metadata部分
- 元数据部分主要包括
- shardRouting,继承关系
- 总结
metadata部分
虽然在刚开始源码概述时把代码分为分布式和数据两部分,但是它们的界限并不明显。之前这几篇可以说是这两部分的衔接。我们在快速接近数据(index)部分。本篇分析一下之前分析cluster遗留下的问题:Metadata与routing,虽然这两部分的代码在cluster中,但是却直接和index相关。
metadata部分主要是和索引相关的一些元数据构建和操作。
元数据部分主要包括
别名元数据(AliasMetaData):索引别名相关,将索引通过别名映射到相关的路由上;
索引元数据(IndexMetaData):索引相关的,如shard数目replica数目, 创建时间等;
索引模板元数据(IndexTemplateMetaData):模板相关,如预设的mapping, aliases等 ;
mapping元数据(MappingMetadata):mapping相关的元数据,如id,routing等;
以及RestoreMetadata和 SnapshortMetadata等。这些metadata囊括了索引相关的所有元数据,这些元数据都是集群级别,我个人认为这也是这部分放到cluster的原因。
metadata是相关功能集群级别的配置信息,它们大都类似于数据类本身的逻辑并不复杂,都是由field和一些对field的set和get方法组成,但是它的有些field本身又是类。而且有些metadata类提供了更加复杂的数据操作方法,如MappingMetadata会有build及对于一些数据格式分析的方法。这里简单分析两个进行说明。
下图是IndexMetadata的部分fields:

可以看到就是一些index相关的元数据,很多都是使用中必须解除到的。如Mapping等。方法上也大多是get与set,并没有太多复杂的逻辑。不同于IndexMetadata,MappingMetaData的filed则多数是内部分类,如下图所示:
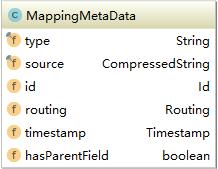
这里的id,routing和timestamp字段都是内部类,因为这些字段还包含其它逻辑,无法通过基本数据类型实现。而Mapping中的关键部分内容字段映射则是一个压缩字符串(source),这是一个json格式的字符串。因此MappingMetadata则包含了很多更复杂的方法用来解析source。
其它的metadata类跟着两个非常类似就不再一一说明,有兴趣的话请参考相关源码。最后来看一下MetaData相关的service,这些service对外提供了对相关MetaData读取和操作的接口。这里以MappingMetaDataService为例做个简单的说明,它的类图如下所示:

MappingMetaDataService对外提供了MappingMetaData的更新,移除等相关操作,这些方法涉及到了索引的相关操作,这里就不展开,在后面索引的分析中会有涉及。
以上就metadata的相关分析,这一部分自身不涉及太复杂的逻辑,复杂的逻辑都在service中,但是因为service的方法会牵扯到Index的操作,因此这里就先简单分析,后面索引的相关分析中再来仔细说明相关方法。
同MetaData类似,routing这一部分主要是集群中索引的路由的相关元数据,但和MetaData不同的是,这一部分有层次结构。ShardRouting是最基本元素,由它构成index的
IndexRoutingTable,最后由IndexRoutingTable构成集群的RoutingTable。
shardRouting,继承关系
如下图所示:

一个Routing本质上是一个可以序列化的XContent,ImmutableShardRount中是Routing中不可变的字段及他们的set和get方法如id, version等。MutableShardRouting中主要是相关的shard操作,如重分配,primaryshard的变动等。一个shard的primary和所有的replica组成一个shardRoutingTable,它的部分代码如下所示:
public class IndexShardRoutingTable implements Iterable<ShardRouting> {
final ShardShuffler shuffler;
final ShardId shardId;
final ShardRouting primary;
final ImmutableList<ShardRouting> primaryAsList;
final ImmutableList<ShardRouting> replicas;
final ImmutableList<ShardRouting> shards;
final ImmutableList<ShardRouting> activeShards;
final ImmutableList<ShardRouting> assignedShards;
......
}
ShardRoutingTable中记录着一个shard所有状态的replica。index由多个shard组成,因此IndexRoutingTable由ShardRoutingTable组成,代码如下所示:
public class IndexRoutingTable implements Iterable<IndexShardRoutingTable> {
private final String index;
private final ShardShuffler shuffler;
// note, we assume that when the index routing is created, ShardRoutings are created for all possible number of
// shards with state set to UNASSIGNED
private final ImmutableOpenIntMap<IndexShardRoutingTable> shards;
private final ImmutableList<ShardRouting> allShards;
private final ImmutableList<ShardRouting> allActiveShards;
.......
}
最后所有的IndexRoutingTable组成了集群的RoutingTable:
public class RoutingTable implements Iterable<IndexRoutingTable> {
public static final RoutingTable EMPTY_ROUTING_TABLE = builder().build();
private final long version;
// index to IndexRoutingTable map
private final ImmutableMap<String, IndexRoutingTable> indicesRouting;
.........
}
这是indexRoutingTable这条线,另外还有一条RoutingTable,那就是nodeRoutingTable,这条RoutingTable线记录了每个节点上的shard的路由信息,由shardRouting构成nodeRoutingTable,然由NodeRoutingTable构成NodesRoutingTable(集群shardRouting)。
同所有是其它模块一样,这些Routing的相关操作也是由service对外提供,另外这一部分还有以下shard操作的相关类如ShardIterator,ShardShuffle等。
总结
本篇从结构上对metadata和Routing部分进行了简单说明,这两部分连接着cluster和index。这里的说明并没有深入到方法层面,一则这里的逻辑大部分很简单,另外这些方法在后面的数据(index)部分的分析中会有涉及。
以上就是elasticsearch元数据构建metadata routing源码分析的详细内容,更多关于elasticsearch元数据构建metadata routing的资料请关注我们其它相关文章!
相关推荐
-

elasticsearch构造Client实现java客户端调用接口示例分析
目录 client的继承关系 方法实现上 以index方法为例 execute方法代码 总结: elasticsearch通过构造一个client对外提供了一套丰富的java调用接口.总体来说client分为两类cluster信息方面的client及数据(index)方面的client.这两个大类由可以分为通用操作和admin操作两类. client的继承关系 (1.5版本,其它版本可能不一样): 通过这个继承关系图可以很清楚的了解client的实现,及功能.总共有三类即client, indi
-
elasticsearch集群发现zendiscovery的Ping机制分析
目录 zenDiscovery实现机制 广播的过程 nodeping处理代码 ping请求的发送策略 总结 zenDiscovery实现机制 ping是集群发现的基本手段,通过在网络上广播或者指定ping某些节点获取集群信息,从而可以找到集群的master加入集群.zenDiscovery实现了两种ping机制:广播与单播.本篇将详细分析一些这MulticastZenPing机制的实现为后面的集群发现和master选举做好铺垫. 广播的过程 首先看一下广播(MulticastZenPing),广
-
elasticsearch java客户端action的实现简单分析
上一篇介绍了elasticsearch的client结构,client只是一个门面,在每个方法后面都有一个action来承接相应的功能.但是action也并非是真正的功能实现者,它只是一个代理,它的真正实现者是transportAction.本篇就对action及transportAction的实现做一个简单的分析, elasticsearch中的绝大部分操作都是通过相应的action,这些action在action包中.它的结构如下图所示: 上图是action包的部分截图,这里面对应着各个功能
-
elasticsearch集群cluster discovery可配式模块示例分析
目录 前言 Discovery模块的概述 cluster节点探测 MasterFaultDetection的启动代码 master连接失败的逻辑 MasterPing的关键代码 前言 elasticsearch cluster实现了自己发现机制zen.Discovery功能主要包括以下几部分内容:master选举,master错误探测,集群中其它节点探测,单播多播ping.本篇会首先概述以下Discovery这一部分的功能,然后介绍节点检测.其它内容会在接下来介绍. Discovery模块的概述
-
elasticsearch数据信息索引操作action support示例分析
目录 抽象类分析 doExecute方法 performOperation代码 master的相关操作 总结 抽象类分析 Action这一部分主要是数据(索引)的操作和部分集群信息操作. 所有的请求通过client转发到对应的action上然后再由对应的TransportAction来执行相关请求.如果请求能在本机上执行则在本机上执行,否则使用Transport进行转发到对应的节点.action support部分是对action的抽象,所有的具体action都继承了support action
-
elasticsearch源码分析index action实现方式
目录 action的作用 TransportAction的类图 OperationTransportHandler的代码 primary操作的方法 总结 action的作用 上一篇从结构上分析了action的,本篇将以index action为例仔分析一下action的实现方式. 再概括一下action的作用:对于每种功能(如index)action都会包括两个基本的类*action(IndexAction)和Transport*action(TransportIndexAction),前者类中
-
elasticsearch元数据构建metadata及routing类源码分析
目录 metadata部分 元数据部分主要包括 shardRouting,继承关系 总结 metadata部分 虽然在刚开始源码概述时把代码分为分布式和数据两部分,但是它们的界限并不明显.之前这几篇可以说是这两部分的衔接.我们在快速接近数据(index)部分.本篇分析一下之前分析cluster遗留下的问题:Metadata与routing,虽然这两部分的代码在cluster中,但是却直接和index相关. metadata部分主要是和索引相关的一些元数据构建和操作. 元数据部分主要包括 别名元数
-
java.lang.Void类源码解析
在一次源码查看ThreadGroup的时候,看到一段代码,为以下: /* * @throws NullPointerException if the parent argument is {@code null} * @throws SecurityException if the current thread cannot create a * thread in the specified thread group. */ private static Void checkParentAcc
-
MyBatis 源码分析 之SqlSession接口和Executor类
mybatis框架在操作数据的时候,离不开SqlSession接口实例类的作用.可以说SqlSession接口实例是开发过程中打交道最多的一个类.即是DefaultSqlSession类.如果笔者记得没有错的话,早期是没有什么getMapper方法的.增删改查各志有对应的方法进行操作.虽然现在改进了很多,但是也保留了很多.我们依旧可以看到类似于selectList这样子的方法.源码的例子里面就可以找到.如下 SqlSession session = sqlMapper.openSession(T
-
PHP通过反射动态加载第三方类和获得类源码的实例
使用反射动态加载第三方类 用反射加载第三方类用处在于: 使用XML或其他配文件配置要加载的类,从而和系统源代码分离. 对加载的类进行类检查,是加载的类符合自己定义的结构. <?php abstract class Module { #核心Module类库 function baseFunc() { echo "I am baseFunc"; } abstract function execute(); } class ModuleRunner { private $configD
-
Java并发之ReentrantLock类源码解析
ReentrantLock内部由Sync类实例实现. Sync类定义于ReentrantLock内部. Sync继承于AbstractQueuedSynchronizer. AbstractQueuedSynchronizer继承于AbstractOwnableSynchronizer. AbstractOwnableSynchronizer类中只定义了一个exclusiveOwnerThread变量,表示当前拥有的线程. 除了Sync类,ReentrantLock内部还定义了两个实现类. No
-
易语言地下城与勇士辅助顺图类源码
DNF辅助顺图类源码 仅供学习参考,禁止商业用途 .版本 2 .程序集 顺图 .子程序 顺图结构 .参数 方向ID, 整数型 .局部变量 一级偏移, 整数型 .局部变量 二级偏移, 整数型 .局部变量 临时数据, 整数型 .局部变量 坐标结构, 整数型 .局部变量 x, 整数型 .局部变量 y, 整数型 .局部变量 xF, 整数型 .局部变量 yF, 整数型 .局部变量 cx, 整数型 .局部变量 cy, 整数型 一级偏移 = 汇编_读整数型 (#人物基址) 二级偏移 = 汇编_读整数型 (一级
-
易语言地下城与勇士辅助剧情类源码
DNF辅助剧情类源码 仅供学习参考,禁止商业用途 .版本 2 .支持库 EThread .程序集 剧情 .子程序 跳过call .局部变量 任务地址, 整数型 .局部变量 跳过CALL, 整数型 任务地址 = #任务基址 跳过CALL = #跳过CALL 置入代码 ({ 139, 77, 252, 139, 9, 106, 255, 106, 1, 255, 85, 248 }) .子程序 匹配副本 .局部变量 角色等级, 整数型 角色等级 = 汇编_读整数型 (#角色等级) .判断开始 (角色
-
Java并发编程学习之Unsafe类与LockSupport类源码详析
一.Unsafe类的源码分析 JDK的rt.jar包中的Unsafe类提供了硬件级别的原子操作,Unsafe里面的方法都是native方法,通过使用JNI的方式来访问本地C++实现库. rt.jar 中 Unsafe 类主要函数讲解, Unsafe 类提供了硬件级别的原子操作,可以安全的直接操作内存变量,其在 JUC 源码中被广泛的使用,了解其原理为研究 JUC 源码奠定了基础. 首先我们先了解Unsafe类中主要方法的使用,如下: 1.long objectFieldOffset(Field
-
详细解读AbstractStringBuilder类源码
因为看StringBuffer 和 StringBuilder 的源码时发现两者都继承了AbstractStringBuilder,并且很多方法都是直接super的父类AbstractStringBuilder的方法,所以还是决定先看AbstractStringBuilder的源码,然后再看StringBuffer 和 StringBuilder. 位置:java.lang包中 声明: abstract class AbstractStringBuilderimplements Appendab