python OpenCV图像金字塔
目录
- 1.图像金字塔理论基础
- 2.向下取样函数及使用
- 3.向上取样函数及使用
- 4.采样可逆性研究
- 5.拉普拉斯金字塔
- 6.图像轮廓介绍
- 轮廓近似

1.图像金字塔理论基础
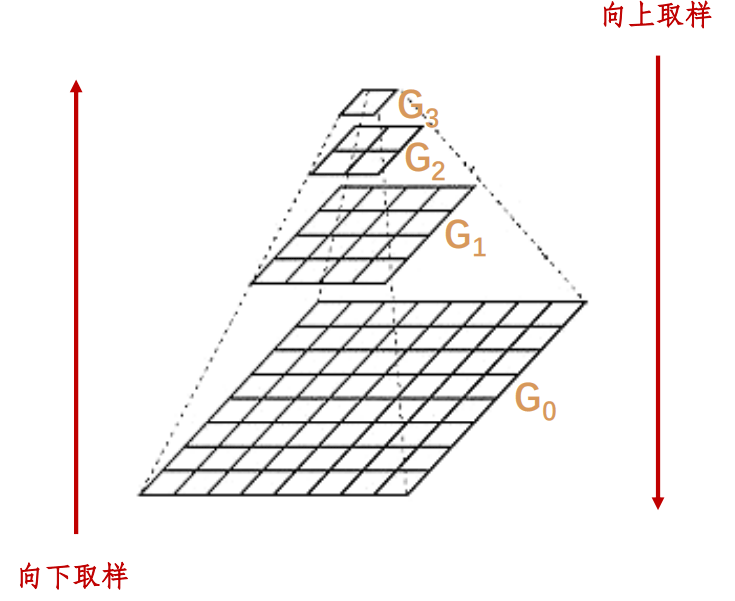
图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
那我们为什么要做图像金字塔呢?这就是因为改变像素大小有时候并不会改变它的特征,比方说给你看1000万像素的图片,你能知道里面有个人,给你看十万像素的,你也能知道里面有个人,但是对计算机而言,处理十万像素可比处理1000万像素要容易太多了。就是为了让计算机识别特征这个事变得更加简便,后期我们也会讲到识别特征这个实战项目,大概就是说比如你在高中打篮球,远远的看见你班主任出来了,你们离500米,你依然可以根据特征取认识出来你的老师,和你班主任离你2米的时候一样。

也就是说图像金字塔式同一个图像不同分辨率子图的集合。在这里我们可以举一个例子就是原始图像是一个400400的图像,那么向上取就可以是200200的一张图像然后100*100,这样分辨率降低,但是始终是同一个图像。
那么从第i层到第i+1层,他具体是怎么做的呢?
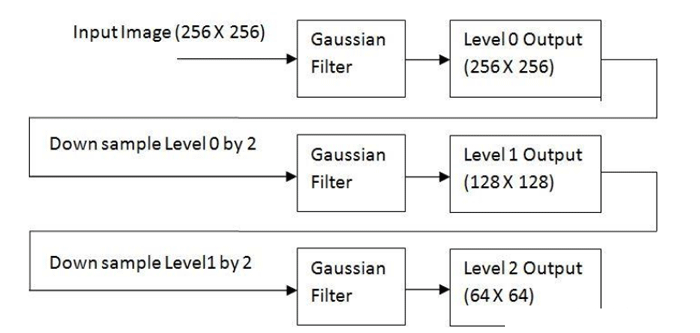
1.计算输入图像减少的分辨率的近似值。这可以通过对输入进行滤波并以2为步长进行抽样(即子抽样)。可以采用的滤波操作有很多,如邻域平均(可生成平均值金字塔),高斯低通滤波器(可生成高斯金字塔),或者不进行滤波,生成子抽样金字塔。生成近似值的质量是所选滤波器的函数。没有滤波器,在金字塔的上一层中的混淆变得很显著,子抽样点对所选取的区域没有很好的代表性。
2.对上一步的输出进行内插(因子仍为2)并进行过滤。这将生成与输入等分辨率的预测图像。由于在步骤1的输出像素之间进行插值运算,所以插入滤波器决定了预测值与步骤1的输入之间的近似程度。如果插入滤波器被忽略了,则预测值将是步骤1输出的内插形式,复制像素的块效应将变得很明显。
3.计算步骤2的预测值和步骤1的输入之间的差异。以j级预测残差进行标识的这个差异将用于原始图像的重建。在没有量化差异的情况下,预测残差金字塔可以用于生成相应的近似金字塔(包括原始图像),而没有误差。
执行上述过程P次将产生密切相关的P+1级近似值和预测残差金字塔。j-1级近似值的输出用于提供近似值金字塔,而j级预测残差的输出放在预测残差金字塔中。如果不需要预测残差金字塔,则步骤2和3、内插器、插入滤波器以及图中的加法器都可以省略。
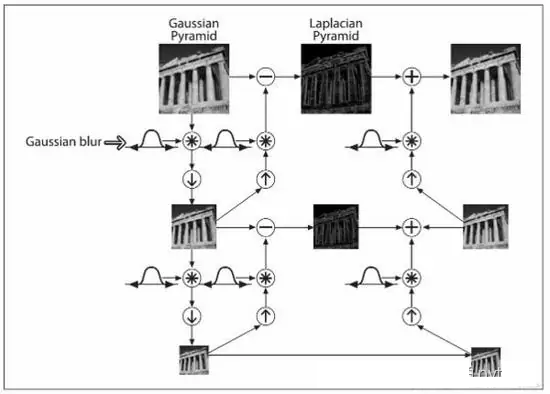
这里面下取样表示图像的缩小。向上取样表示的是图像的增大。
1.对图像Gi进行高斯核卷积。
高斯核卷积就是我们所说的高斯滤波操纵,我们之前就已经讲过,使用一个高斯卷积核,让临近的像素值所占的权重较大,然后和目标图像做相关操作。
2.删除所有的偶数行和列。
原始图像 M * N 处理结果 M/2 * N/2。每次处理后,结果图像是原来的1/4。这个操作被称为Octave。重复执行该过程,构造图像金字塔。直至图像不能继续下分为止。这个过程会丢失图像信息。
而向上取样恰恰和向下取样相反,是在原始图像上,**在每个方向上扩大为原来的2倍,新增的行和列以0填充。使用与“向下采用”同样的卷积核乘以4,获取“新增像素”的新值。**经过向上取样后的图像会模糊。
向上采样、向下采样不是互逆操作。经过两种操作后,无法恢复原有图像。
2.向下取样函数及使用
图像金字塔向下取样函数:
dst=cv2.pyrDown(src)
import cv2
import numpy as np
o=cv2.imread("image\\man.bmp")
r1=cv2.pyrDown(o)
r2=cv2.pyrDown(r1)
r3=cv2.pyrDown(r2)
cv2.imshow("original",o)
cv2.imshow("PyrDown1",r1)
cv2.imshow("PyrDown2",r2)
cv2.imshow("PyrDown3",r3)
cv2.waitKey()
cv2.destroyAllWindows()
这里我们对图像做三次向下取样,结果为:

向下取样会丢失信息!!!
3.向上取样函数及使用
图像金字塔向上取样函数:
dst=cv2.pyrUp(src)
这里代码我们就不做介绍了。
直接看一下我们的结果:

4.采样可逆性研究
这里我们具体看一下图像进行向下取样然后进行向上取样操作后,是不是一致的。还有就是图像进行向上取样然后向下取样后,是不是一致的呢?这里我们以小女孩的图像做一下研究。
首先我们来分析一下:当图像做向下取样一次之后,图像由MN变成了M/2N/2,然后再次经过向上取样之后又变成了M*N。那么可以证明对于图片的size是不发生变化的。
import cv2
o=cv2.imread("image\\girl.bmp")
down=cv2.pyrDown(o)
up=cv2.pyrUp(down)
cv2.imshow("original",o)
cv2.imshow("down",down)
cv2.imshow("up",up)
cv2.waitKey()
cv2.destroyAllWindows()
那么我们来看一下到底发生了什么变化呢?

这里可以很清晰的看出来小女孩的照片变得模糊了,那么是为什么呢?因为我们上面说到了就是当图像变小的时候,那么就会损失一些信息,再次放大之后,由于卷积核变大了,那么图像会变模糊。所以不会和原始图像保持一致。
然后我们再来看一下先进行向上取样操作,然后进行向下取样操作会是什么样子呢?由于图像变大太大所以我们省去中间图像向上取样的图片。

那么我们用肉眼也不是特别容易发现差异,那么我们用图像减法去看一下。
import cv2
o=cv2.imread("image\\girl.bmp")
up=cv2.pyrUp(o)
down=cv2.pyrDown(up)
diff=down-o #构造diff图像,查看down与o的区别
cv2.imshow("difference",diff)
cv2.waitKey()
cv2.destroyAllWindows()

5.拉普拉斯金字塔
我们先来看一下拉普拉斯金字塔是一个什么东西:
Li = Gi - PyrUp(PyrDown(Gi))
我们根据他这个式子可以知道,拉普拉斯金字塔就是使用原始图像减去图像向下取样然后向上取样的这样一个过程。
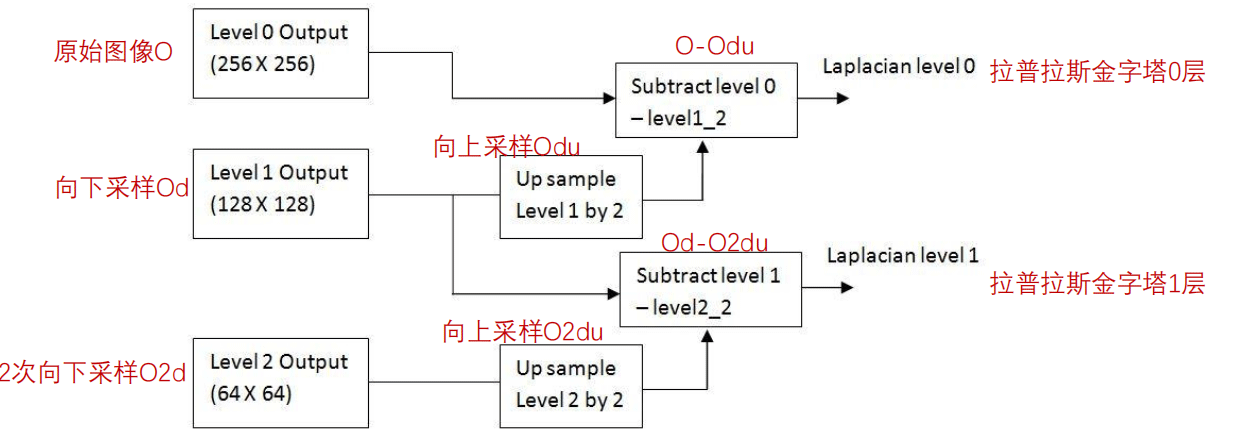
展示在图像当中就是:
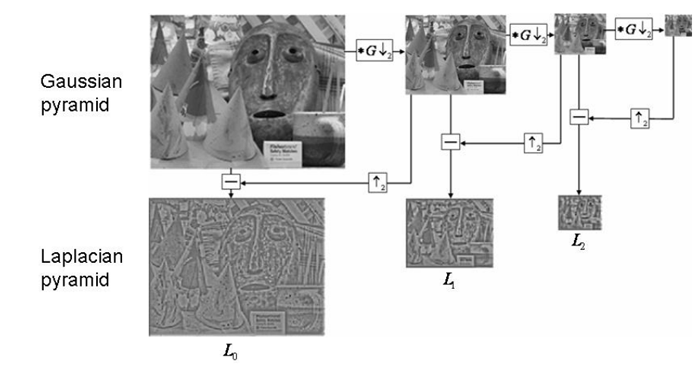
核心函数就是:
od=cv2.pyrDown(o) odu=cv2.pyrUp(od) lapPyr=o-odu
6.图像轮廓介绍
首先我们先要说明这样一个事情就是彼图像轮廓和图像的边缘是不一样的,边缘是零零散散的,但是轮廓是一个整体。

边缘检测能够测出边缘,但是边缘是不连续的。将边缘连接为一个整体,构成轮廓。
注意:
对象是二值图像。所以需要预先进行阈值分割或者边缘检测处理。查找轮廓需要更改原始图像。因此,通常使用原始图像的一份拷贝操作。在OpenCV中,是从黑色背景中查找白色对象。因此,对象必须是白色的,背景必须是黑色的。
对于图像轮廓的检测需要的函数是:
cv2.findContours( )和cv2.drawContours( )
查找图像轮廓的函数是cv2.findContours(),通过cv2.drawContours()将查找到的轮廓绘制到图像上。
对于cv2.findContours( )函数:
image, contours, hierarchy = cv2.findContours( image, mode, method)
这里需要注意在最新的版本中,查找轮廓中的返回函数只有两个即可:
contours, hierarchy = cv2.findContours( image, mode, method)
contours ,轮廓
hierarchy ,图像的拓扑信息(轮廓层次)
image ,原始图像
mode ,轮廓检索模式
method ,轮廓的近似方法
这里我们需要介绍mode:也就是轮廓检索模式:
- cv2.RETR_EXTERNAL :表示只检测外轮廓
- cv2.RETR_LIST :检测的轮廓不建立等级关系
- cv2.RETR_CCOMP :建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边 界信息。如果内孔内还有一
个连通物体,这个物体的边界也在顶层
- cv2.RETR_TREE :建立一个等级树结构的轮廓。
然后我们介绍一下method ,轮廓的近似方法:
- cv2.CHAIN_APPROX_NONE :存储所有的轮廓点,相邻的两个点的像素位置差不超过1, 即max(abs(x1-x2),abs(y2-y1))==1
- cv2.CHAIN_APPROX_SIMPLE:压缩水平方向,垂直方向,对角线方向的元素, 只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息
- cv2.CHAIN_APPROX_TC89_L1:使用teh-Chinl chain 近似算法
- cv2.CHAIN_APPROX_TC89_KCOS:使用teh-Chinl chain 近似算法
比如对一个矩形做轮廓检测,使用cv2.CHAIN_APPROX_NONE和cv2.CHAIN_APPROX_SIMPLE得结果是这样:
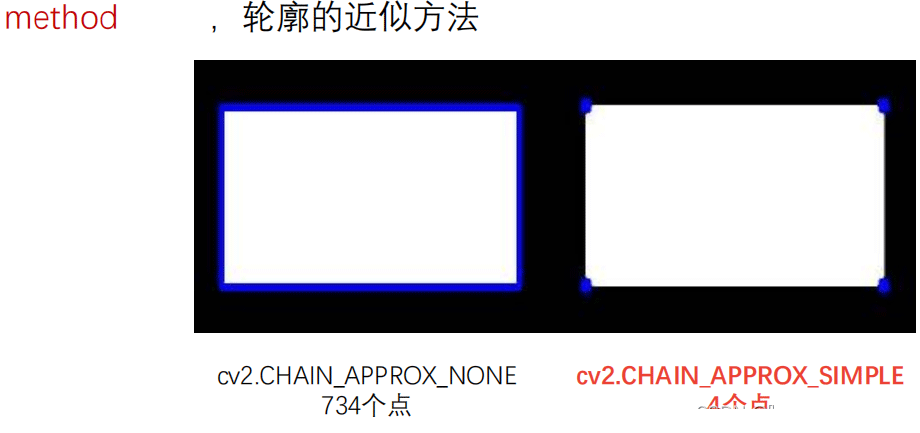
可以看出后者省出来很多计算空间。
对于cv2.drawContours( ):
r=cv2.drawContours(o, contours, contourIdx, color[, thickness])
- r :目标图像,直接修改目标的像素点,实现绘制。
- o :原始图像
- contours :需要绘制的边缘数组。
- contourIdx :需要绘制的边缘索引,如果全部绘制则为 -1。
- color :绘制的颜色,为 BGR 格式的 Scalar 。
- thickness :可选,绘制的密度,即描绘轮廓时所用的画笔粗细。
import cv2
import numpy as np
o = cv2.imread('image\\boyun.png')
gray = cv2.cvtColor(o,cv2.COLOR_BGR2GRAY)
ret, binary = cv2.threshold(gray,127,255,cv2.THRESH_BINARY)
image,contours, hierarchy =cv2.findContours(binary,cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
co=o.copy()
r=cv2.drawContours(co,contours,-1,(0,0,255),1)
cv2.imshow("original",o)
cv2.imshow("result",r)
cv2.waitKey()
cv2.destroyAllWindows()

对于多个轮廓,我们也可以指定画哪一个轮廓。
gray = cv2.cvtColor(o,cv2.COLOR_BGR2GRAY) ret, binary = cv2.threshold(gray,127,255,cv2.THRESH_BINARY) image,contours, hierarchy = cv2.findContours(binary,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE) co=o.copy() r=cv2.drawContours(co,contours,0,(0,0,255),6)

如果设置成-1,那么就是全部显示!!!
轮廓近似
当轮廓有毛刺的时候,我们希望能够做轮廓近似,将毛刺去掉,大体思想是将曲线用直线代替,但是有个长度的阈值需要自己设定。

我们还可以做额外的操作,比如外接矩形,外接圆,外界椭圆等等。
img = cv2.imread('contours.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
binary, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
cnt = contours[0]
x,y,w,h = cv2.boundingRect(cnt)
img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2)
cv_show(img,'img')
area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
rect_area = w * h
extent = float(area) / rect_area
print ('轮廓面积与边界矩形比',extent)
外接圆
(x,y),radius = cv2.minEnclosingCircle(cnt)
center = (int(x),int(y))
radius = int(radius)
img = cv2.circle(img,center,radius,(0,255,0),2)
cv_show(img,'img')
模板匹配和卷积原理很像,模板在原图像上从原点开始滑动,计算模板与(图像被模板覆盖的地方)的差别程度,这个差别程度的计算方法在opencv里有六种,然后将每次计算的结果放入一个矩阵里,作为结果输出。假如原图形是AXB大小,而模板是axb大小,则输出结果的矩阵是(A-a+1)x(B-b+1)。
- TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
- TM_CCORR:计算相关性,计算出来的值越大,越相关
- TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
- TM_SQDIFF_NORMED:计算归一化平方不同,计算出来的值越接近0,越相关
- TM_CCORR_NORMED:计算归一化相关性,计算出来的值越接近1,越相关
- TM_CCOEFF_NORMED:计算归一化相关系数,计算出来的值越接近1,越相关
到此这篇关于python OpenCV图像金字塔的文章就介绍到这了,更多相关python OpenCV金字塔内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

OpenCV图像分割之分水岭算法与图像金字塔算法详解
目录 前言 一.使用分水岭算法分割图像 1.cv2.distanceTransform()函数 2.cv2.connectedComponents()函数 3.cv2.watershed()函数 二.图像金字塔 1.高斯金字塔向下采样 2.高斯金字塔向上采样 3.拉普拉斯金字塔 4.应用图像金字塔实现图像的分割和融合 前言 主要介绍OpenCV中的分水岭算法.图像金字塔对图像进行分割的方法. 一.使用分水岭算法分割图像 分水岭算法的基本原理为:将任意的灰度图像视为地形图表面,其中灰度值高的部分表
-
C++ OpenCV学习之图像金字塔与图像融合详解
目录 1金字塔 2什么是图像金字塔? 3图像金字塔有什么用? 4OpenCV实战图像金字塔 1 金字塔 平时你听到.见到的金字塔是什么样的? 这样? 还是这样? 实际上除了这些,还有图像金字塔 图像金字塔有什么用?为什么要称作图像金字塔?本文带你研究这些问题. 2 什么是图像金字塔? 正如生物视觉系统会处理分层次的尺寸一样,计算机视觉系统实现多分辨率图像处理的基础是图像金字塔. 考虑这样一个场景:输入系统一幅图像来检测人脸.由于事先并不知道人脸在这张图片中可能的尺寸,所以需要根据输入生成一个
-
OpenCV 图像金字塔的实现示例
目录 1.高斯金字塔 2.拉普拉斯金字塔 本文主要介绍了OpenCV 图像金字塔,具有一定的参考价值,感兴趣的可以了解一下 高斯金字塔reduce void cv::pyrDown() expand void cv::pyrUp() 1.高斯金字塔 图像金字塔是对一张输入图像先模糊再下采样为原来的高.宽的1/2,不断重复模糊与下采样的过程就得到了不同分辨率的输出图像,叠加在一起就形成了图像金字塔. 高斯金字塔便是先进行高斯模糊,再进行reduce和expand操作.高斯金字塔中的较高级别(低分辨
-
Android基于OpenCV实现图像金字塔
目录 图像金字塔 高斯金字塔 拉普拉斯金字塔 API 下采样 上采样 操作 操作 效果 源码 图像金字塔 图像金字塔是图像中多尺度表达的一种,最主要用于图像的分割,是一种以多分辨率来解释图像的有效但概念简单的结构. 图像金字塔最初用于机器视觉和图像压缩,一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合.其通过梯次向下采样获得,直到达到某个终止条件才停止采样. 金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似. 我们将一层一层的图像比喻成金字塔
-
python 用opencv实现图像修复和图像金字塔
我们将学习如何通过一种称为修复的方法去除旧照片中的小噪音,笔画等.基本思路很简单:用相邻像素替换那些坏标记,使其看起来像邻域. cv2.inpaint() cv2.INPAINT_TELEA cv2.INPAINT_NS import numpy as np import cv2 as cv img = cv.imread('messi_2.jpg') mask = cv.imread('mask2.png',0) dst = cv.inpaint(img,mask,3,cv.INPAINT_T
-
OpenCV半小时掌握基本操作之图像金字塔
目录 概述 图像金字塔 高斯金字塔 拉布拉斯金字塔 [OpenCV]⚠️高手勿入! 半小时学会基本操作 ⚠️ 图像金字塔 概述 OpenCV 是一个跨平台的计算机视觉库, 支持多语言, 功能强大. 今天小白就带大家一起携手走进 OpenCV 的世界. 图像金字塔 高斯金字塔 高斯金字塔 (Gaussian Pyramid) 是最基本的图像塔. 对图像进行高斯滤波, 然后去除偶数行和列. 对图像放大形成上采样. 下采样: 例子: # 读取图片 img = cv2.imread("person.jp
-
python计算机视觉opencv图像金字塔轮廓及模板匹配
目录 1.图像金字塔 ①高斯金字塔 ②拉普拉斯金字塔 2.图像轮廓 ①寻找轮廓 ②轮廓特征 ③轮廓绘制 3.模板匹配 ①模板匹配 ②匹配框线绘制 ③多对象匹配 4.直方图统计 ①直方图绘制 ②直方图统计 ③直方图的mask操作 ④直方图均衡化 5.傅里叶变换 1.图像金字塔 ①高斯金字塔 向下采样,数据会越来越少,减少的方式是:将偶数行和列删除 向上采样,数据会越来越多,将图像在每个方向上扩大为原来的两倍,新增的行和列用0来填充.使用先前同样的内核与放大后的图像卷积,获得近似值. 上采样之后,图
-
python OpenCV图像金字塔
目录 1.图像金字塔理论基础 2.向下取样函数及使用 3.向上取样函数及使用 4.采样可逆性研究 5.拉普拉斯金字塔 6.图像轮廓介绍 轮廓近似 1.图像金字塔理论基础 图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构.一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合.其通过梯次向下采样获得,直到达到某个终止条件才停止采样.我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低.那我们为什么要做图像金字塔呢?这
-
Python OpenCV高斯金字塔与拉普拉斯金字塔的实现
基础知识铺垫 学习图像金字塔,发现网上的资料比较多,检索起来比较轻松. 图像金字塔是一张图像多尺度的表达,或者可以理解成一张图像不同分辨率展示. 金字塔越底层的图片,像素越高,越向上,像素逐步降低,分辨率逐步降低. 高斯金字塔 我们依旧不对概念做过多解释,第一遍学习应用,应用,毕竟 365 天的周期,时间长,后面补充理论知识. 高斯金字塔用于向下采样,同时它也是最基本的图像塔. 在互联网检索原理,得到最简单的说明如下: 将图像的最底层(高斯金字塔的第 0 层),例如高斯核(5x5)对其进行卷积操
-
python opencv 图像尺寸变换方法
利用Python OpenCV中的 cv.Resize(源,目标,变换方法)就可以实现变换为想要的尺寸了 源文件:就不用说了 目标:你可以对图像进行倍数的放大和缩小 也可以直接的输入尺寸大小 变换的方法: CV_INTER_NN - 最近邻插值, CV_INTER_LINEAR - 双线性插值 (缺省使用) CV_INTER_AREA - 使用象素关系重采样.当图像缩小时候,该方法可以避免波纹出现.当图像放大时,类似于 CV_INTER_NN 方法.. CV_INTER_CUBIC - 立方插值
-
python opencv 图像边框(填充)添加及图像混合的实现方法(末尾实现类似幻灯片渐变的效果)
图像边框的实现 图像边框设计的主要函数 cv.copyMakeBorder()--实现边框填充 主要参数如下: 参数一:源图像--如:读取的img 参数二--参数五分别是:上下左右边的宽度--单位:像素 参数六:边框类型: cv.BORDER_CONSTANT--cv.BORDER_REPLICATE--cv.BORDER_REFLECT--cv.BORDER_WRAP--cv.BORDER_REFLECT_101--cv.BORDER_TRANSPARENT--cv.BORDER_REFLEC
-
Python OpenCV 图像区域轮廓标记(框选各种小纸条)
学在前面 上篇 OpenCV 博客原计划完成一个 识别银行卡号的项目,但是写的过程中发现,技术储备不足,我无法在下述图片中,提取出卡号区域,也就无法进行后续的识别了,再次意识到了自己技术还不达标,继续学习.完不成,就实现其它学习项目. 轮廓识别实战 先看一下最终实现的效果,针对一张图片(该图片前景色和背景色差异较大),进行轮廓标记. 图片基本处理 import cv2 as cv src = cv.imread("./demo.jpg") gray = cv.cvtColor(src,
-
Python OpenCV 图像平移的实现示例
每次学习新东西的时候,橡皮擦都是去海量检索,然后找到适合自己理解的部分. 再将其拼凑成一个小的系统,争取对该内容有初步理解. 今天这 1 个小时,核心要学习的是图像的平移,在电脑上随便打开一张图片,实现移动都非常简单,但是在代码中,出现了一些新的概念. 检索 OpenCV 图像平移相关资料时,碰到的第一个新概念是就是 仿射变换. 每次看到这样子的数学名字,必然心中一凉,做为一个数学小白,又要瑟瑟发抖了. 百度一下,看看百科中是如何介绍的. 看过上图中的一些相关简介之后,对于这个概念也并没有太深刻
-
详解python opencv图像混合算术运算
目录 图片相加 cv2.add() 按位运算 图片相加 cv2.add() 要叠加两张图片,可以用 cv2.add() 函数,相加两幅图片的形状(高度 / 宽度 / 通道数)必须相同. numpy中可以直接用res = img + img1相加,但这两者的结果并不相同(看下边代码): add()两个图片进行加和,大于255的使用255计数. numpy会对结果取256(相当于255+1)的模: import numpy as np import c
-
Python+OpenCV 图像边缘检测四种实现方法
目录 1.Sobel算子 2.Schaar算子(更能体现细节) 3.Laplacian算子(基于零穿越的,二阶导数的0值点) 4.Canny边缘检测(被认为是最优的边缘检测算法) 总结 import cv2 as cv import numpy as np import matplotlib.pyplot as plt # 设置兼容中文 plt.rcParams['font.family'] = ['sans-serif'] plt.rcParams['font.sans-serif'] = [