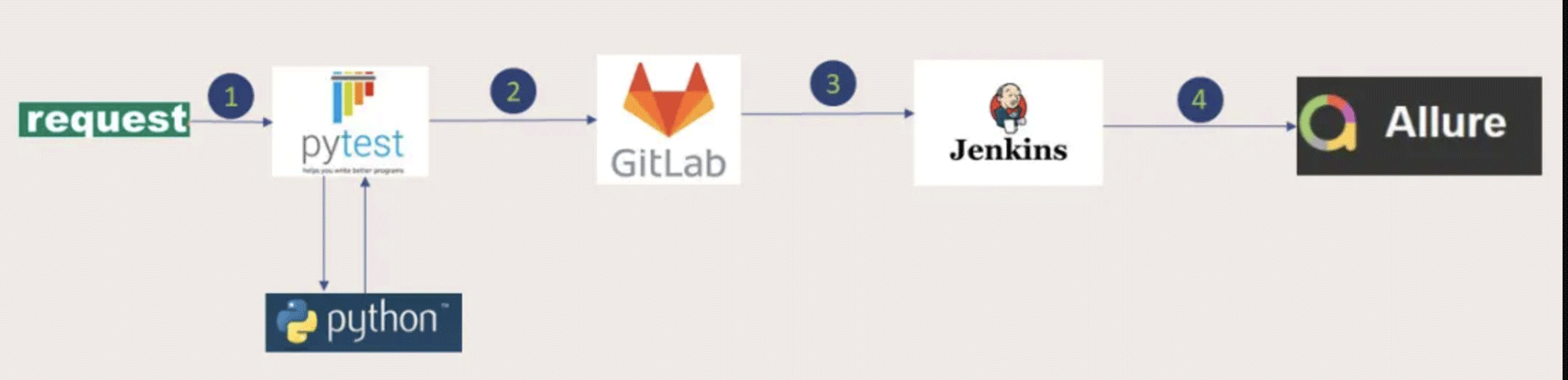
Pytest+Request+Allure+Jenkins实现接口自动化
- 利用
Pytest+Request+Allure+Jenkins实现接口自动化; - 实现一套脚本多套环境执行;
- 利用参数化数据驱动模式,实现接口与测试数据分离
- 使用
logger定制实现自动化测试日志记录
实现步骤:
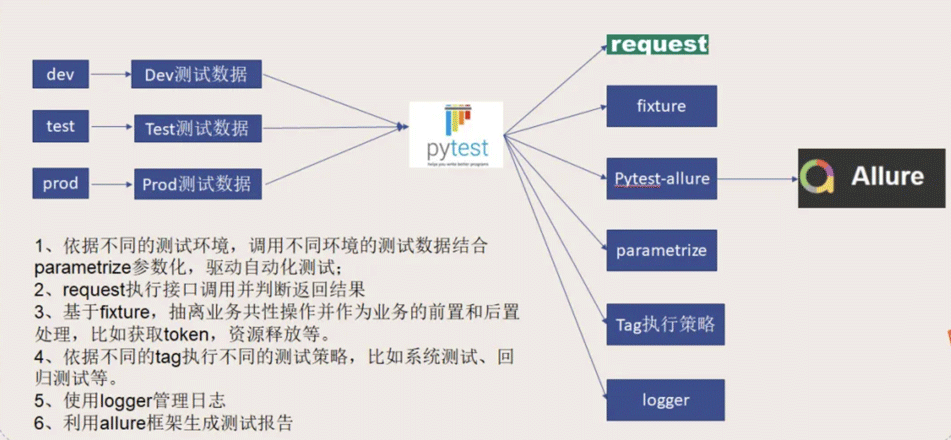
框架结构:
1、接口自动化项目代码编写(先在window实现)
1.1 项目准备
先在window安装响应的环境依赖
- 安装python3.7(要保证pip能用,一般安装python3.7会自动安装pip)
- 安装pytest框架---- pip install pytest
- 安装request库---- pip install request
- 安装openpyxl库(测试数据保存在excel中,需要依赖读取excel的库)---- pip install openpyxl
- 安装pycharm(编写python脚本工具)
注意:可能还需要一些依赖的东西,项目步骤里会依据需要进行安装
1.2 设计基于pytest的测试框架结构
在pycharm中开发构建项目结构
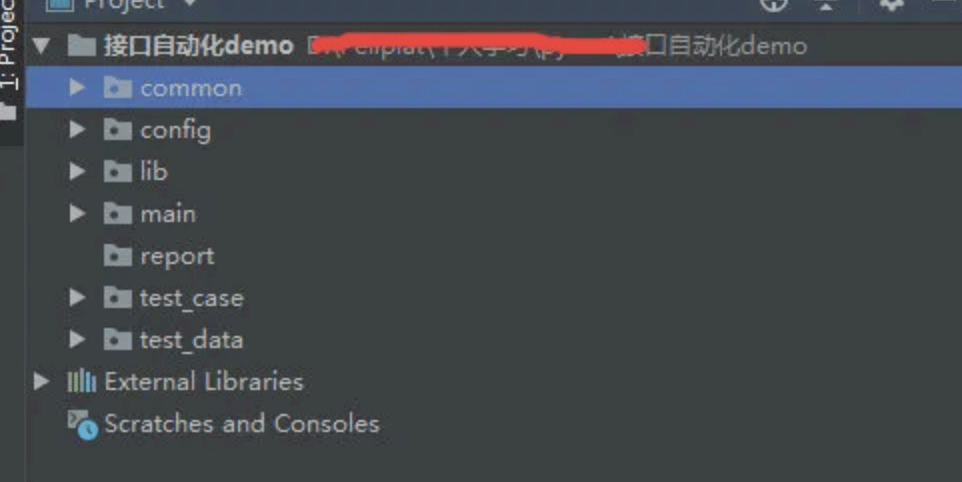
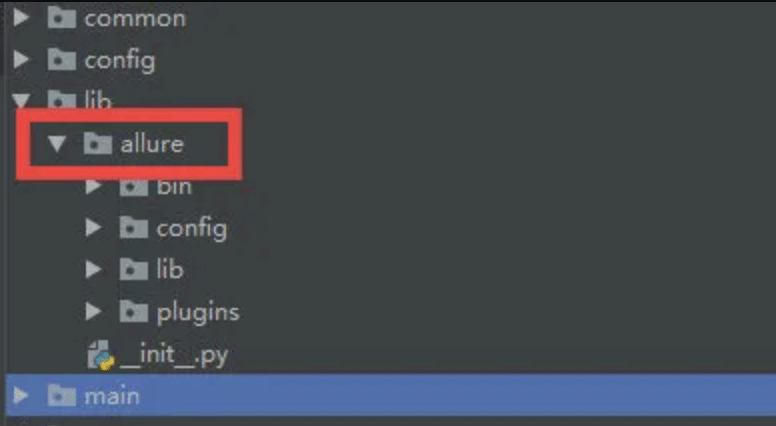
common:存放公共方法
config:存放环境配置信息
lib:存放第三方库
main:框架主入口
report:存放allure测试报告
test_case:存放测试用例
test_data:存放测试数据
1.3 实现接口公共请求发送能力
从这一步开始正式编写代码
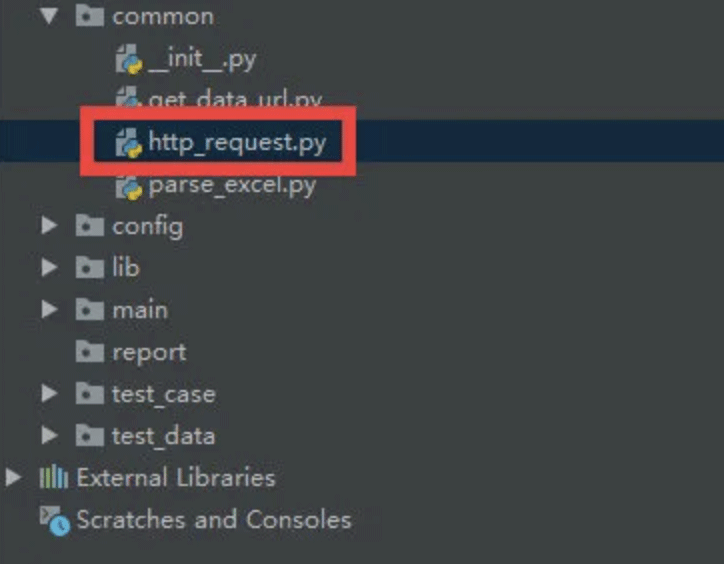
封装http请求的公共能力(封装request库,变成自己的公共处理能力),放到common目录下。
# encoding: utf-8
import requests
import urllib3
# from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings()
# 加这句不会报错(requests证书警告)
# requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
class HTTPRequests(object):
def __init__(self, url):
self.url = url
self.req = requests.session()
# 依据自己公司的请求头默认值配置
self.head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept': 'image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, '
'application/x-ms-xbap, application/vnd.ms-excel, application/vnd.ms-powerpoint, '
'application/msword, */*',
'Accept-Language': 'zh-CN'}
# 封装自己的get请求,获取资源
def get(self, uri='', params='', data='', headers=None, cookies=None, verify=False):
if headers is None:
headers = self.head
# print("请求头是:{}".format(headers))
url = self.url + uri
response = self.req.get(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)
return response
# 封装自己的post请求,获取资源
def post(self, uri='', params='', data='', headers=None, cookies=None, verify=False):
if headers is None:
headers = self.head
url = self.url + uri
response = self.req.post(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)
return response
# 封装自己的put请求,获取资源
def put(self, uri='', params='', data='', headers=None, cookies=None, verify=False):
if headers is None:
headers = self.head
url = self.url + uri
response = self.req.put(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)
return response
# 封装自己的delete请求,获取资源
def delete(self, uri='', params='', data='', headers=None, cookies=None, verify=False):
if headers is None:
headers = self.head
url = self.url + uri
response = self.req.delete(url, params=params, data=data, headers=headers, cookies=cookies, verify=verify)
return response
1.4 抽离测试环境配置信息
这个步骤的目的有三个
- 为了配置三个不同环境(测试、开发、生产)的URL,每个环境接口测试的URL是不一样的,设置这样一个枚举类,方便后面的程序根据不同的环境,获取不同环境的URL,里面的URL依据自己公司的地址修改,放到config目录
- 获取token需要登录,这里可以设置一个全局的账号密码,这个账号密码获取的token可以给整个接口自动化使用
- 配置获取token的uri,这个uri三个环境的是一致的,登录的接口依据环境只是URL不同,URI还是一致的。
# encoding: utf-8
import enum
class URLConf(enum.Enum):
"""环境配置信息"""
url_mapping = {
'dev': 'https://www.dev.com',
'test': 'https://www.test.com',
'prod': 'https://www.prod.com'
}
# token固定的用户名密码,固定用"/"分割用户名和密码
email_user = {
'dev': 'dev@qq.com',
'test': 'zidonghua@qq.com/96e79218965eb72c92a549dd5a330112',
'prod': 'prod@qq.com'
}
login_uri = r'/api/auth/login/account/v1'
1.5 创建conftest.py放置一些公共的fixture
1、pytest_addoption,设置了只允许输入dev/test/prod三个参数,以区分测试、开发、生产三个环境
2、get_env的fixture,它的作用是你在命令行执行接口自动化时,可以输入--env test将对应的环境信息传入进去
3、http的fixture,这里依据--env test传入的环境信息,去枚举类里获取对应环境的URL,然后返回一个http的session,供测试案例使用
4、get_token_head,依据--env test传入的环境信息,调用获取token方法,并将token放置到请求头head里返回(token一般放在请求头里,这里依据自己公司的请求,返回对应的token信息就可以了)
# encoding: utf-8
# 代码来源:全栈测开训练营
import logging
import os
import pytest
from common.http_request import HTTPRequests
from config.url_config import URLConf
datadir = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), "test_data")
logger = logging.getLogger('conftest日志')
def pytest_addoption(parser):
# choices 只允许输入的值的范围
parser.addoption(
"--env", action="store", default='test', choices=['dev', 'test', 'prod'], help="set env"
)
# 获取命令行参数的fixture
@pytest.fixture(scope='session')
def get_env(request):
# print("fixutre..................")
return request.config.getoption('--env')
# 声明一个返回http请求对象的fixture,所有用例在一个session中
# @pytest.fixture(scope='module', autouse=True)
@pytest.fixture(autouse=True)
def http(request):
env = request.getfixturevalue("get_env")
url_mapping = URLConf.url_mapping.value
url = url_mapping.get(f'{env}')
http = HTTPRequests(url)
return http
@pytest.fixture(scope='session')
def get_token_head(request):
env = request.getfixturevalue("get_env")
url_mapping = URLConf.url_mapping.value
url = url_mapping.get(f'{env}')
http = HTTPRequests(url)
user = URLConf.email_user.value
user_list = user.get(f'{env}').split("/")
username = user_list[0]
password = user_list[1]
param = {'clientType': 2,
'language': 'en',
'loginId': username,
'loginPassword': password}
logger.info("请求的url=={}".format(url))
response = http.post(uri=r'/api/auth/login/account/v1', data=param)
logger.info("获取的返回值是:".format(response.text))
token = None
if response.status_code == 200:
token = response.json().get('result')['token']
else:
token = 'get token fail'
head = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Accept': 'image/gif, image/jpeg, image/pjpeg, application/x-ms-application, application/xaml+xml, '
'application/x-ms-xbap, application/vnd.ms-excel, application/vnd.ms-powerpoint, '
'application/msword, */*',
'Accept-Language': 'zh-CN',
'Authorization': token}
yield head
1.6 将测试数据放到excel中
我们的测试数据是放在excel中,注意,这里有prod\test\dev三个目录,对应三个环境的测试数据,我这里只创建了test测试环境的测试数据。这里的测试数据需要包含两部分:
- 你调用接口传入的所有参数;
- 你要断言的所有信息,因为你传的参数不同,返回的内容就不同,你断言的内容也就不相同了。

那么这时候,就需要一个读取excel的公共方法了,放到common里
# 创建解析excel的方法
import logging
from openpyxl import load_workbook
logger = logging.getLogger("读取excel")
class ParseExcel(object):
def __init__(self, excelPath, sheetName):
self.wb = load_workbook(excelPath)
self.sheet = self.wb[sheetName]
self.maxRowNum = self.sheet.max_row
# 依据传入的数字,决定获取几列excel数据
def getDataFromSheet(self, num):
dataList = []
for line in self.sheet.rows:
tmplist = []
for i in range(num):
tmplist.append(line[i].value)
dataList.append(tmplist)
print("dadddddd:{}".format(dataList))
return dataList[2:]
这里,还需要再test_data中,创建一个文件,为了获取前面test_data依据环境创建的dev/test或prod文件目录
1.7 开始编写自动化测试案例了
测试案例中有几个点,需要解释一下:
1、authBaseDir,这个就是根据test_data/test拼接出来的获取测试数据的目录
2、allure.feature,在测试报告中,会展现这个接口名称,这个名称最好与你公司的开发写的接口模块保持一致,方便后续查找问题
3、allure.story 这里也要与开发写的具体某个接口的名称保持一致。
4、pytest.mark.parametrize,这里就是运用的DDT数据驱动的模式,从excel中一条一条的获取数据,然后执行同一条接口测试用例,excel中比如有3条数据,那么就表示这个案例依据每一条数据的参数,总共执行了三次
# encoding: utf-8
"""
Account Api模块
"""
import logging
import os
import allure
import pytest
from common.get_data_url import get_data_url
from common.parse_excel import ParseExcel
datadir = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), "test_data")
data_url = get_data_url()
# 获取到test_data\test的目录,如果是prod环境,那么就是获取test_data\prod目录
authBaseDir = os.path.join(datadir, data_url)
logger = logging.getLogger("Account Api模块日志")
@allure.feature("AccountApi模块")
@pytest.mark.webtest
class TestAccountApi(object):
"""Query Related Achievements: /api/auth/account/achievement/related/query/v1
"""
Query_Related_Achievements_dir = os.path.join(authBaseDir, 'Query_Related_Achievements.xlsx')
logger.info("Query_Related_Achievements测试数据的路径是:{}".format(Query_Related_Achievements_dir))
parse = ParseExcel(Query_Related_Achievements_dir, 'Sheet1')
Query_Related_Achievements_params = parse.getDataFromSheet(5)
@allure.story("Query Related Achievements(查询用户成就信息)")
@pytest.mark.parametrize("clientType,language,retCode,istoken,result", Query_Related_Achievements_params)
def test_001_Query_Related_Achievements(self, get_token_head, http, clientType, language, retCode, istoken, result):
uri = '/api/auth/account/achievement/related/query/v1'
params = {"clientType": clientType, "language": language}
if istoken == 'yes':
header = get_token_head
response = http.get(uri=uri, params=params, headers=header)
json_req = response.json()
logger.info("Query_Related_Achievements有token的返回值是:{}".format(json_req))
assert json_req.get('retCode') == 200
assert json_req.get('result')[0]['smallImg'] == result
else:
response = http.get(uri=uri, params=params)
json_req = response.json()
logger.info("Query_Related_Achievements没有token的返回值是:{}".format(json_req))
assert json_req.get('retCode') == 401
assert json_req.get('message') == result
1.8 集成allure
写到这里,是不是发现前面的allure.feature是不是用不了呢?这是因为我们还没有集成allure进去。
1、下载allure,放到lib目录下,使你的工程具备allure的能力。
2、pip install allure-pytest安装pytest对应的allure包
1.9 这时候就可以创建一些执行策略了
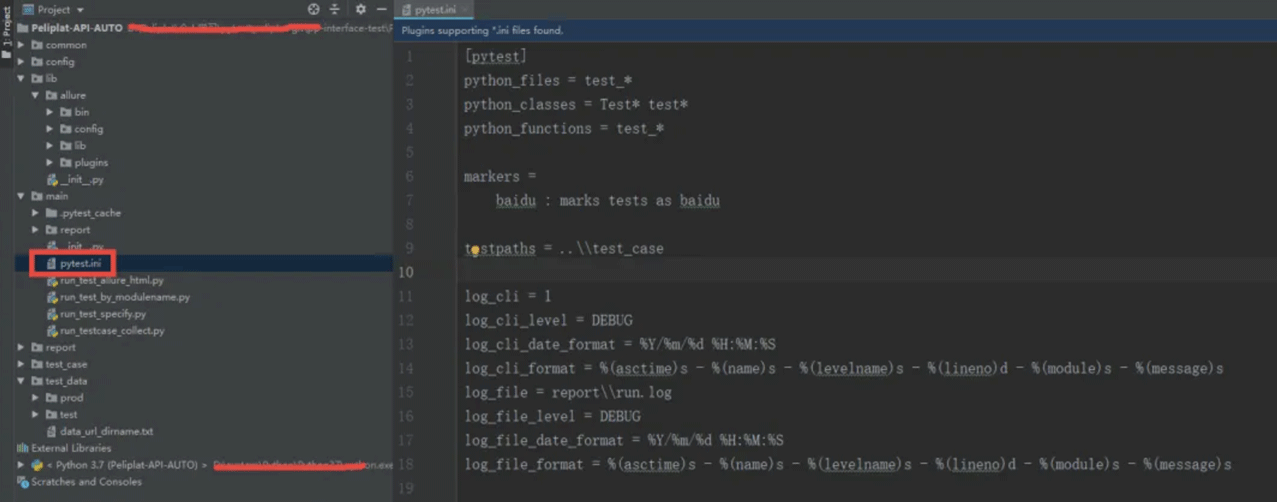
1、先在main中创建一个pytest.ini文件,设置一些执行参数
2、在main中创建执行策略
- 先在run_pytest方法中,执行案例并生成allure的json格式的报告文件,这里可以带--env prod将对应环境信息传入,这里没有传是因为默认是test环境,不传入的话就是执行的test环境测试数据
- general_report方法时将生成的json格式的报告,最终生成html文件放置到report下面的目录中
- 创建一个线程,先执行run_pytest,再执行general_report,避免json文件没有生成,这样生成html文件的报告数据可能不全,甚至没有。

# encoding: utf-8
"""
所有案例执行并生成allure测试报告的执行策略
"""
import os
import sys
import threading
import pytest
sys.path.append(os.path.dirname(os.path.abspath(__file__)) + '/../')
from common.report import Report
project_root = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
report_dir = os.path.join(project_root, 'report')
# 存放测试结果的目录,会生成一推json文件
result_dir = os.path.join(report_dir, 'allure_result')
allure_report = os.path.join(report_dir, 'allure_report')
report = Report()
# 定义搜索条件,搜索所有以test开头的用例
tag = 'test'
def run_pytest():
# --clean-alluredir
# pytest.main(['-vv', '-s', '-m', 'webtest', f'--alluredir={result_dir}', '--clean-alluredir'])
# 执行前清除allure_result数据,避免生成报告时,会把上次执行的数据带进去
pytest.main(['-vv', '-s', '-k', f'{tag}', f'--alluredir={result_dir}', '--clean-alluredir'])
def general_report():
# 调用cmd方法 report.allure,根据windows或linux环境判断
# 然后执行生成报告的方法generate
# --clean 覆盖路径,将上次的结果覆盖掉
cmd = "{} generate {} -o {} --clean".format(report.allure, result_dir, allure_report)
# 执行命令行命令,并通过read()方法将命令的结果返回
print(os.popen(cmd).read())
if __name__ == '__main__':
# 创建两个线程,分别执行两个方法
run = threading.Thread(target=run_pytest)
gen = threading.Thread(target=general_report)
run.start()
# 先执行第一个线程,这个线程执行完才会执行下面的线程和主线程
run.join()
gen.start()
gen.join()
1.10 自动化执行生成结果
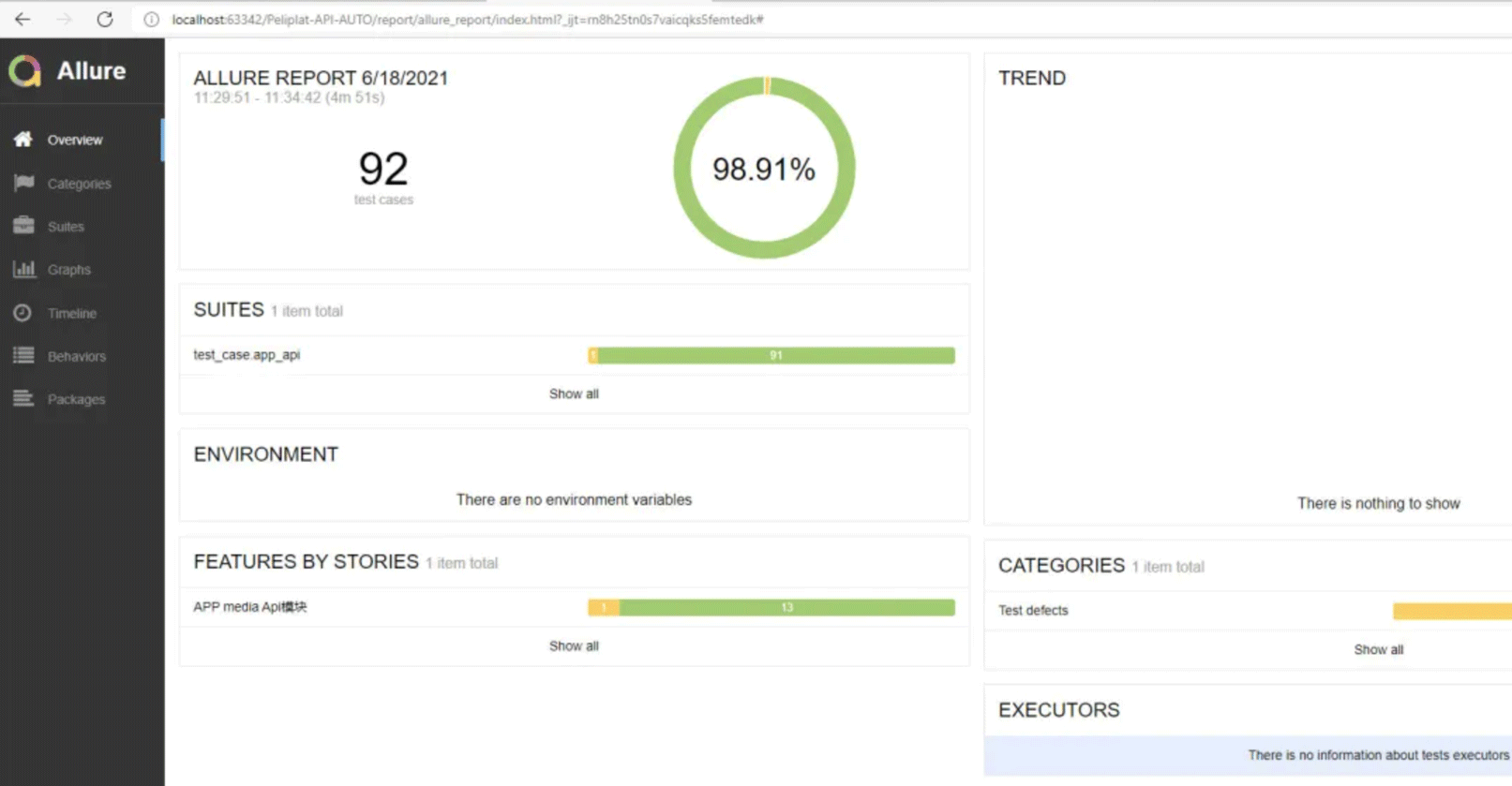
在windows下,右键执行main下面的run_test_allure_html.py(就是上一个步骤的python文件),然后打开report/allure_report/index.html看看报告是否生成成功
2. jenkins环境搭建(linux环境)
好了,到这一步,在windows下我们已经执行成功,现在我们要集成到jenkins环境去,并搭建在linux环境下。
1、将代码上传到公司的git(没有git的自己搭建一套吧)
2、找一台linux机器(自己去自己公司找资源)
3、在linux下安装jenkins(我是放到tomcat中)、python3、pytest、allure、openpyxl(这些步骤在网上可以搜索到,这里不赘述了)
4、启动linux下的tomcat,然后在window下打开jenkins的服务地址
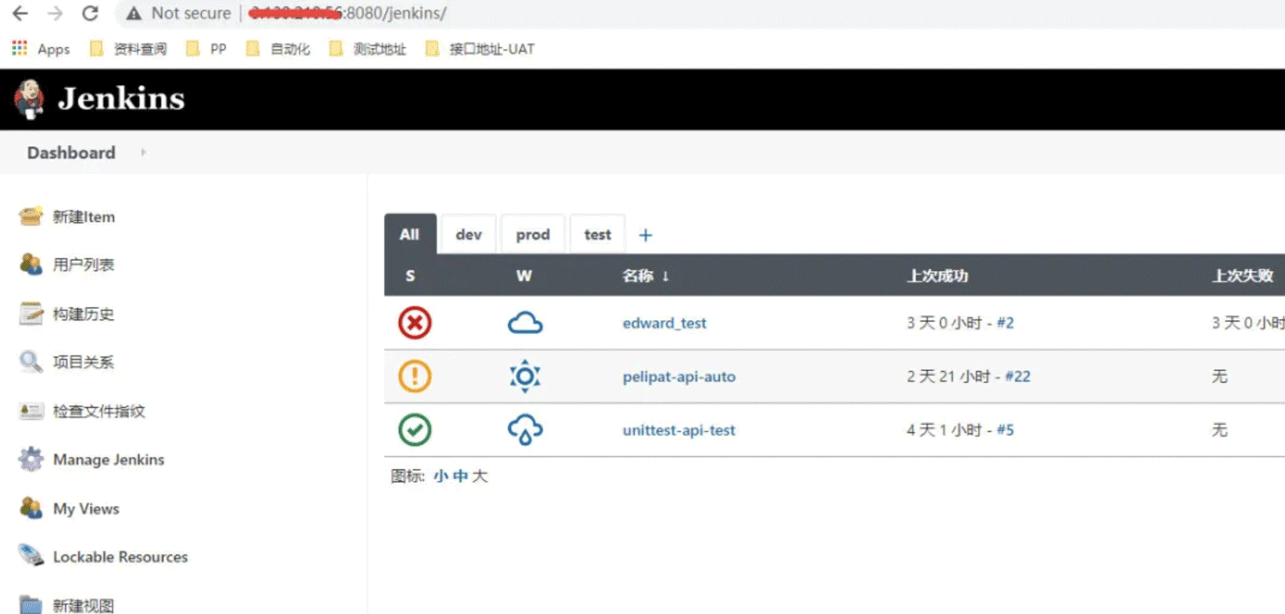
5、创建一个自由风格的job
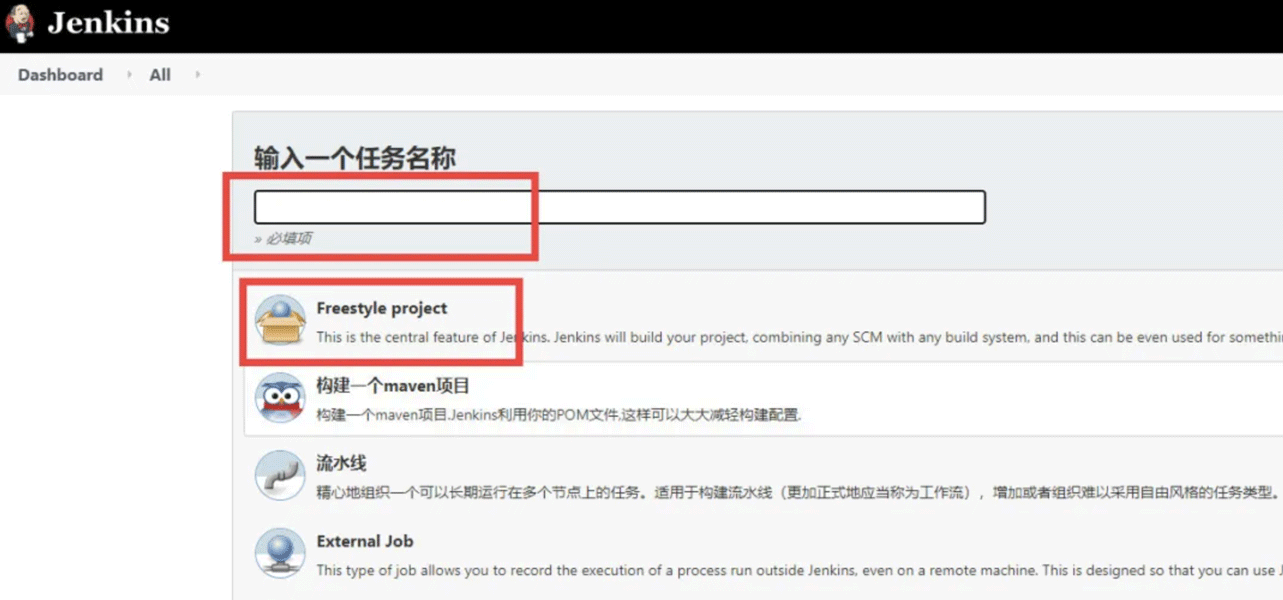
6、Job需要填写的具体内容有:
A、选择丢弃旧的构建(保留的构建天数依据自己的情况选择)

B、“限制项目的运行节点”依据自己的情况选择(我这里给我的jenkins主服务器取了一个叫linux的标签,我的机器也是linux机器)

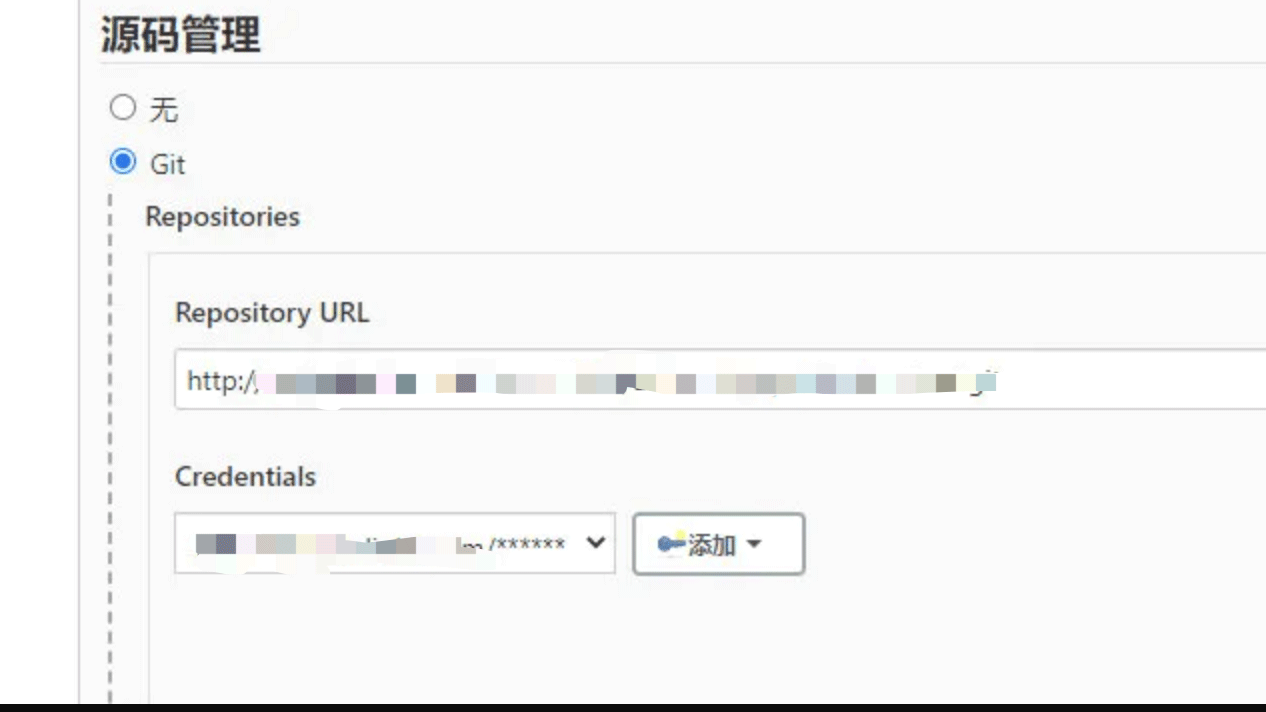
C、git--将git上的代码拉下来
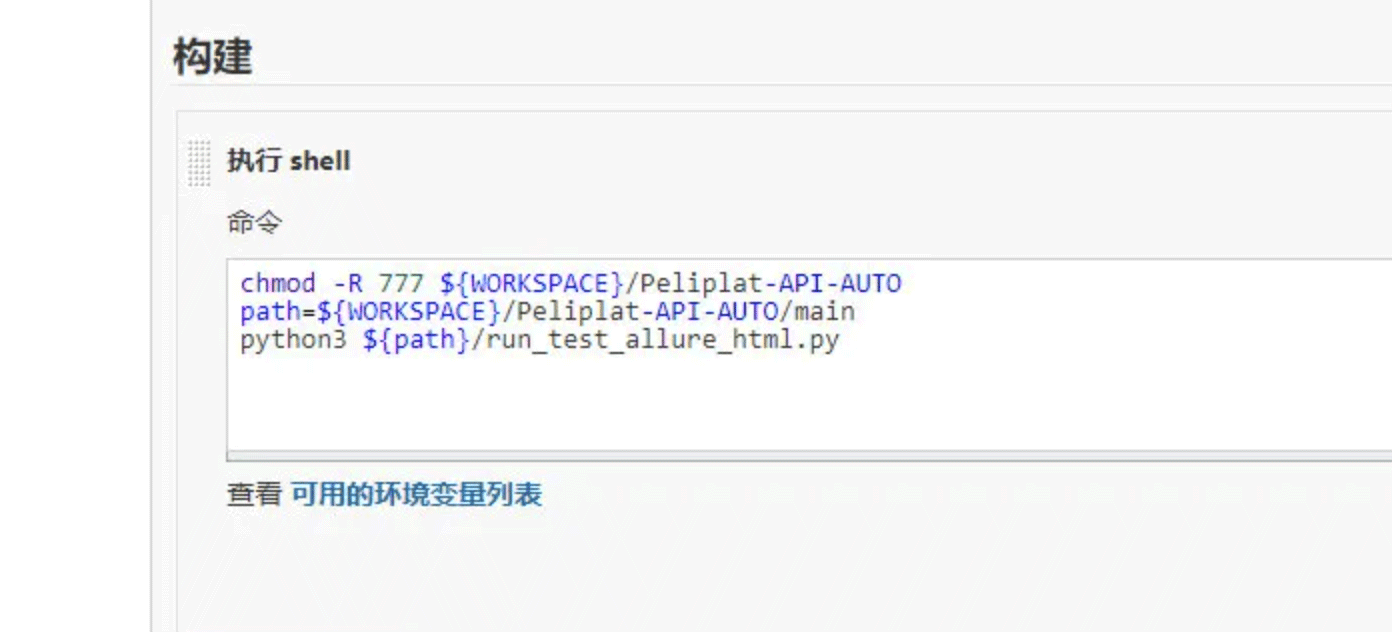
D、“执行shell”,这里把代码从git拉到了jenkins的执行目录里,一般在linux下的root/.jenkins里,在执行shell时,最好chmod修改下整个工程的目录权限,因为有可能因权限问题执行不了
E、构建后的操作:这里需要再jenkins里安装allure插件才能看到allure Report,第一个Path,这里写的是allure生成的json文件的目录,所以是report/allure_result,第二个Report path指的是生成的index.html文件的目录,所以是report/allure_report
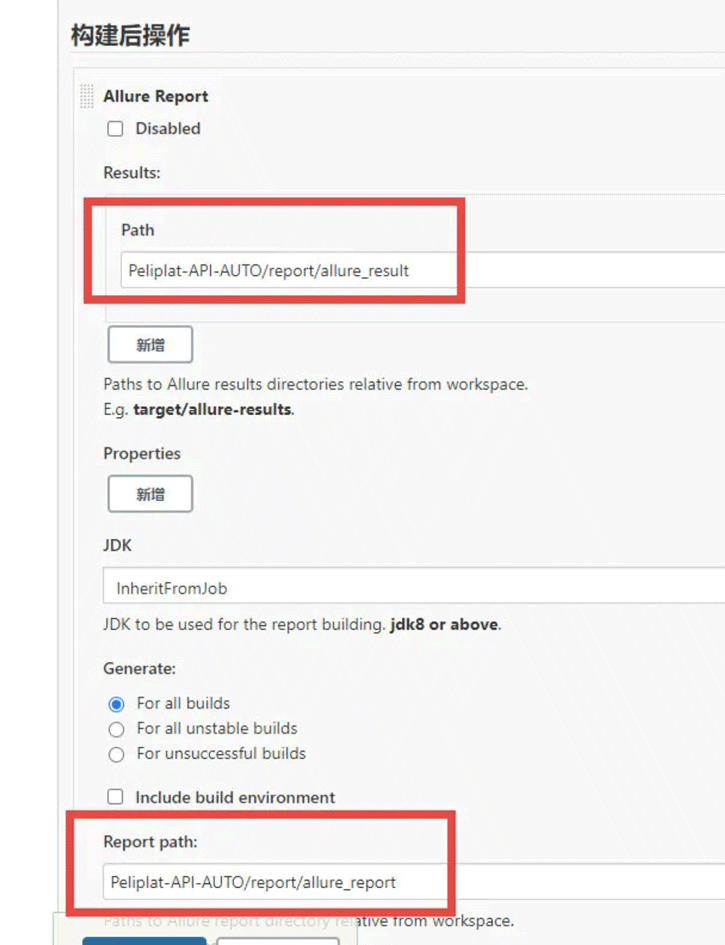
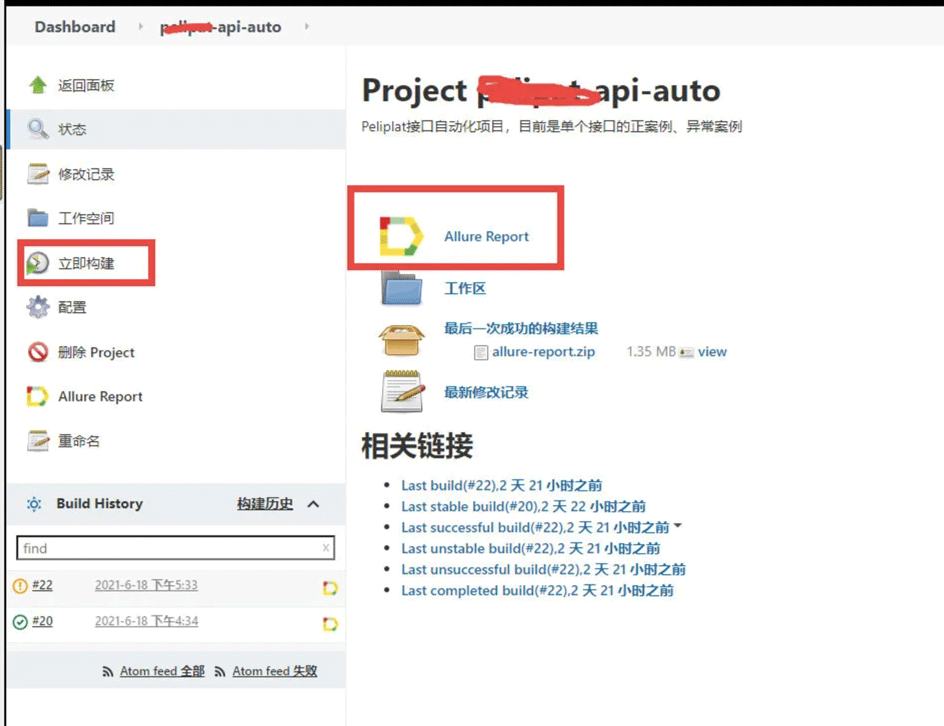
立即构建并查看报告
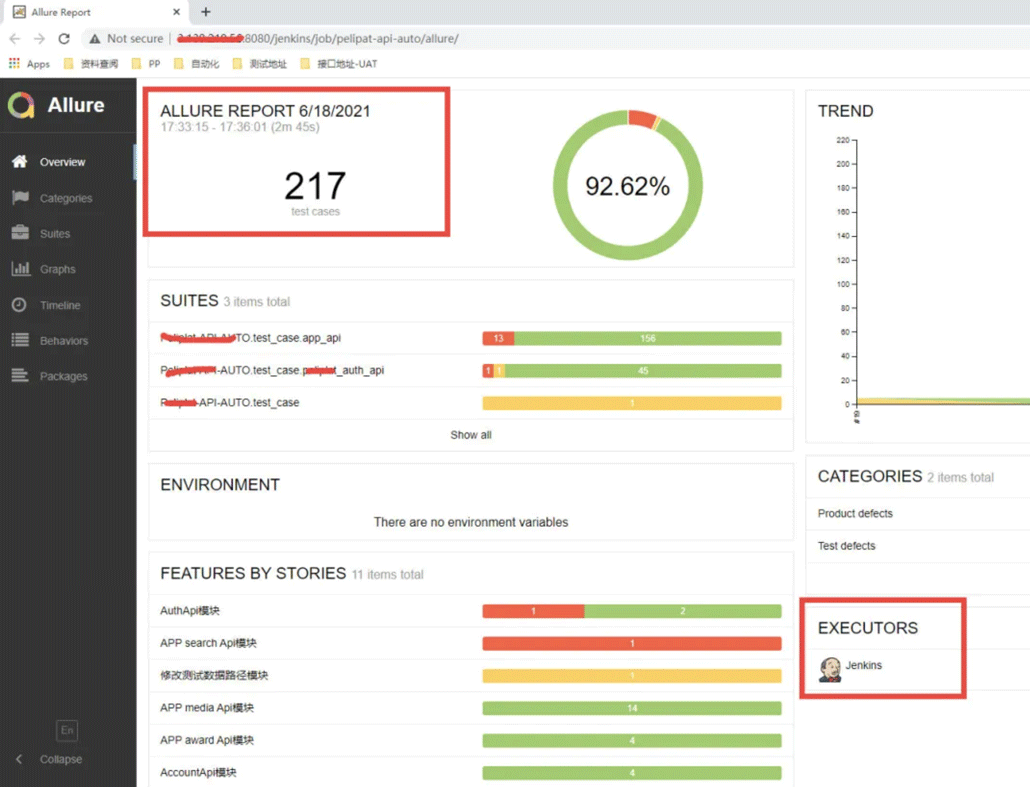
上面的job建成后,就可以点击立即构建,执行了。执行完后,点击allure Report查看最终的报告。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python+pytest接口自动化之日志管理模块loguru简介
目录 安装 简单示例 add()常用参数说明 使用 python自带日志管理模块logging,使用时可进行模块化配置,详细可参考博文Python日志采集(详细). 但logging配置起来比较繁琐,且在多进行多线程等场景下使用时,如果不经过特殊处理,则容易出现日志丢失或记录错乱的情况. python中有一个用起来非常简便的第三方日志管理模块--loguru,不仅可以避免logging的繁琐配置,而且可以很简单地避免在logging中多进程多线程记录日志时出现的问题,甚至还可以自定义控制台输出的
-
python+pytest接口自动化之token关联登录的实现
目录 一. 什么是token 二. token场景处理 这里介绍如下两种处理思路. 1. 思路一 2. 思路二 三. 总结 在PC端登录公司的后台管理系统或在手机上登录某个APP时,经常会发现登录成功后,返回参数中会包含token,它的值为一段较长的字符串,而后续去请求的请求头中都需要带上这个token作为参数,否则就提示需要先登录. 这其实就是状态或会话保持的第三种方式token. 一. 什么是token token 由服务端产生,是客户端用于请求的身份令牌.第一次登录成功时,服务端会生成一个
-
Pytest+request+Allure实现接口自动化框架
目录 前言: 一.简单介绍 二.代码结构与框架流程 三.详细功能和使用说明 四.Allure报告及Email 五.后续优化 前言: 接口自动化是指模拟程序接口层面的自动化,由于接口不易变更,维护成本更小,所以深受各大公司的喜爱. 接口自动化包含2个部分,功能性的接口自动化测试和并发接口自动化测试. 本次文章着重介绍第一种,功能性的接口自动化框架. 一.简单介绍 环境:Mac.Python 3,Pytest,Allure,Request pytest==3.6.0 pytest-allure-ad
-
python+pytest接口自动化之session会话保持的实现
目录 前言 一.session(会话) 二.会话保持 三.python进行session会话保持 总结 前言 在接口测试的过程中,经常会遇到有些接口需要在登录的状态下才能请求,否则会提示请登录,那么怎样解决呢?我们可以通过Cookie绕过登录,其实这就是保持登录状态的方法之一.那么今天笔者想讲通过session进行会话保持. 一.session(会话) session,即会话.那么什么又是会话?我们来看一下会话的生存周期就能大致明白,如下: 开始:客户端(通常是浏览器)-->发送第一个请求-->
-
python+requests+pytest接口自动化的实现示例
1.发送get请求 #导包 import requests #定义一个url url = "http://xxxxxxx" #传递参数 payload="{\"head\":{\"accessToken\":\"\",\"lastnotice\":0,\"msgid\":\"\"},\"body\":{\"user_name\&
-
Pytest+Yaml+Excel 接口自动化测试框架的实现示例
目录 一.框架架构 二.项目目录结构 三.框架功能说明 四.核心逻辑说明 配置文件 输出目录 请求工具类 代码编写case 程序主入口 执行记录 一.框架架构 二.项目目录结构 三.框架功能说明 解决痛点: 通过session会话方式,解决了登录之后cookie关联处理 框架天然支持接口动态传参.关联灵活处理 支持Excel.Yaml文件格式编写接口用例,通过简单配置框架自动读取并执行 执行环境一键切换,解决多环境相互影响问题 支持http/https协议各种请求.传参类型接口 响应数据格式支持
-
Pytest接口自动化测试框架搭建模板
auto_api_test 开发环境: Pycharm 开发语言&版本: python3.7.8 测试框架: Pytest.测试报告: Allure 项目源码Git地址 项目目录结构 api – 模仿PO模式, 抽象出页面类, 页面类内包含页面所包含所有接口, 并封装成方法可供其他模块直接调用 config – 配置文件目录 data – 测试数据目录 doc – 文档存放目录 log – 日志 report – 测试报告 scripts – 测试脚本存放目录 tools – 工具类目录 .gi
-
python+pytest接口自动化参数关联
目录 前言 一.什么是参数关联? 二.有哪些场景? 三.参数关联场景 四.脚本编写 1.在用例中按顺序调用 2. 使用Fixture函数 五. 总结 前言 今天呢,笔者想和大家来聊聊python+pytest接口自动化测试的参数关联,笔者这边就不多说废话了,咱们直接进入正题. 一.什么是参数关联? 参数关联,也叫接口关联,即接口之间存在参数的联系或依赖.在完成某一功能业务时,有时需要按顺序请求多个接口,此时在某些接口之间可能会存在关联关系.比如:B接口的某个或某些请求参数是通过调用A接口获取的,
-
python使用pytest接口自动化测试的使用
简单的设计思路 利用pytest对一个接口进行各种场景测试并且断言验证 配置文件独立开来(conf文件),实现不同环境下只需要改环境配置即可 测试的场景读取excle的测试用例,可支持全量执行或者自定义哪条用例执行(用例内带加密变量): 接口入参还包含了加密的逻辑,所以需加一层加密处理 用例的样例: 应用的库包含: import pytest import time, json import base64, hmac import hashlib, uuid, re import request
-
Pytest+Request+Allure+Jenkins实现接口自动化
利用Pytest+Request+Allure+Jenkins实现接口自动化: 实现一套脚本多套环境执行: 利用参数化数据驱动模式,实现接口与测试数据分离 使用logger定制实现自动化测试日志记录 实现步骤: 框架结构: 1.接口自动化项目代码编写(先在window实现) 1.1 项目准备 先在window安装响应的环境依赖 安装python3.7(要保证pip能用,一般安装python3.7会自动安装pip) 安装pytest框架---- pip install pytest 安装reque
-
Python+Requests+PyTest+Excel+Allure 接口自动化测试实战
Unittest是Python标准库中自带的单元测试框架,Unittest有时候也被称为PyUnit,就像JUnit是Java语言的标准单元测试框架一样,Unittest则是Python语言的标准单元测试框架. Pytest是Python的另一个第三方单元测试库.它的目的是让单元测试变得更容易,并且也能扩展到支持应用层面复杂的功能测试. 两者对比: Pytest项目实战: 第一步.搭建项目框架(创建Gwyc_Api_Script_Pytest项目目录) 依次创建子目录如下:base:存放一些最底
-
Python接口自动化之request请求封装源码分析
目录 1. 源码分析 2. requests请求封装 3. 总结 前言: 我们在做自动化测试的时候,大家都是希望自己写的代码越简洁越好,代码重复量越少越好.那么,我们可以考虑将request的请求类型(如:Get.Post.Delect请求)都封装起来.这样,我们在编写用例的时候就可以直接进行请求了. 1. 源码分析 我们先来看一下Get.Post.Delect等请求的源码,看一下它们都有什么特点. (1)Get请求源码 def get(self, url, **kwargs): r""
-
python接口自动化(十六)--参数关联接口后传(详解)
简介 大家对前边的自动化新建任务之后,接着对这个新建任务操作了解之后,希望带小伙伴进一步巩固胜利的果实,夯实基础.因此再在沙场实例演练一下博客园的相关接口.我们用自动化发随笔之后,要想接着对这篇随笔操作,不用说就需 要用参数关联了,发随笔之后会有一个随笔的 id,获取到这个 id,继续操作传这个随笔 id 就可以了(博客园的登录机制已经变了,不能用账号和密码登录了,这里用 cookie 登录) 大致流程步骤:web界面操作登录抓包查看cookie->代码模拟cookie登录->web界面操作新