浅谈实时计算框架Flink集群搭建与运行机制
一、Flink概述
1.1、基础简介
主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink不仅可以运行在包括YARN、Mesos、Kubernetes在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。
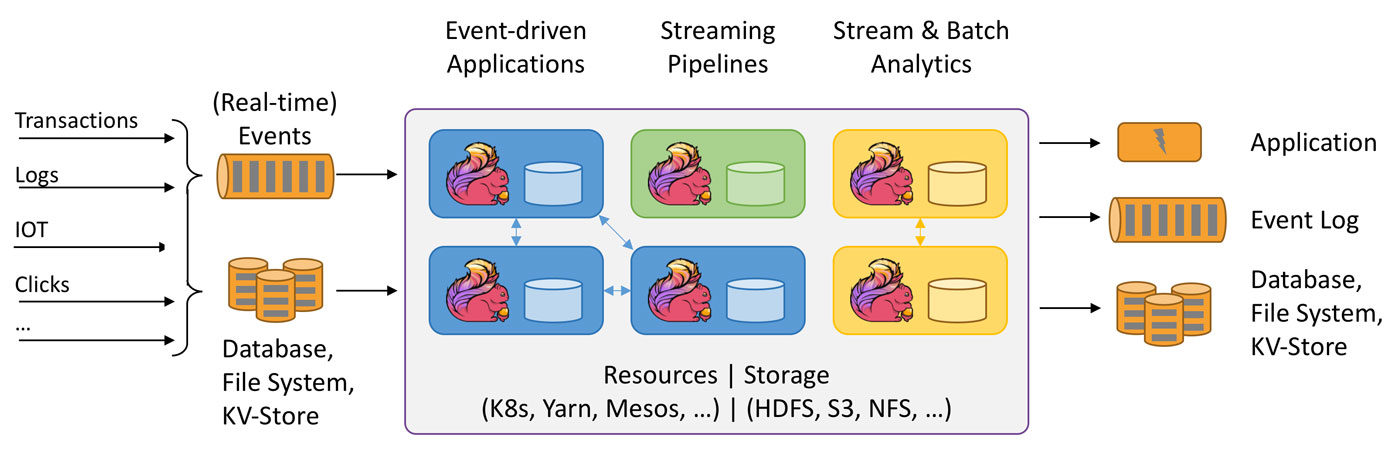
这里要说明两个概念:
- 边界:无边界和有边界数据流,可以理解为数据的聚合策略或者条件;
- 状态:即执行顺序上是否存在依赖关系,即下次执行是否依赖上次结果;
1.2、应用场景
Data Driven

事件驱动型应用无须查询远程数据库,本地数据访问使得它具有更高的吞吐和更低的延迟,以反欺诈案例来看,DataDriven把处理的规则模型写到DatastreamAPI中,然后将整个逻辑抽象到Flink引擎,当事件或者数据流入就会触发相应的规则模型,一旦触发规则中的条件后,DataDriven会快速处理并对业务应用进行通知。
Data Analytics

和批量分析相比,由于流式分析省掉了周期性的数据导入和查询过程,因此从事件中获取指标的延迟更低。不仅如此,批量查询必须处理那些由定期导入和输入有界性导致的人工数据边界,而流式查询则无须考虑该问题,Flink为持续流式分析和批量分析都提供了良好的支持,实时处理分析数据,应用较多的场景如实时大屏、实时报表。
Data Pipeline
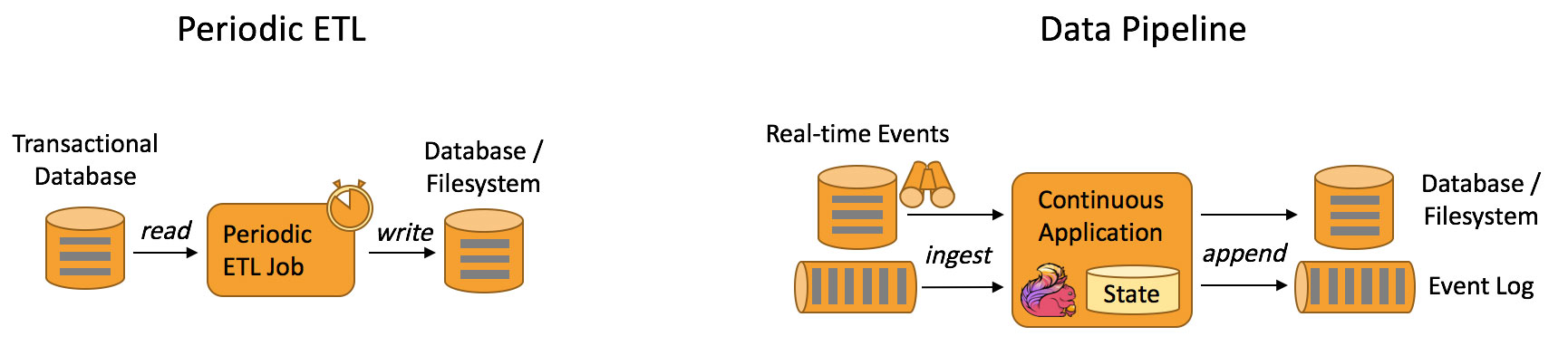
与周期性的ETL作业任务相比,持续数据管道可以明显降低将数据移动到目的端的延迟,例如基于上游的StreamETL进行实时清洗或扩展数据,可以在下游构建实时数仓,确保数据查询的时效性,形成高时效的数据查询链路,这种场景在媒体流的推荐或者搜索引擎中十分常见。
二、环境部署
2.1、安装包管理
[root@hop01 opt]# tar -zxvf flink-1.7.0-bin-hadoop27-scala_2.11.tgz
[root@hop02 opt]# mv flink-1.7.0 flink1.7
2.2、集群配置
管理节点
[root@hop01 opt]# cd /opt/flink1.7/conf
[root@hop01 conf]# vim flink-conf.yaml
jobmanager.rpc.address: hop01
分布节点
[root@hop01 conf]# vim slaves
hop02
hop03
两个配置同步到所有集群节点下面。
2.3、启动与停止
/opt/flink1.7/bin/start-cluster.sh
/opt/flink1.7/bin/stop-cluster.sh
启动日志:
[root@hop01 conf]# /opt/flink1.7/bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hop01.
Starting taskexecutor daemon on host hop02.
Starting taskexecutor daemon on host hop03.
2.4、Web界面
访问:http://hop01:8081/
三、开发入门案例
3.1、数据脚本
分发一个数据脚本到各个节点:
/var/flink/test/word.txt
3.2、引入基础依赖
这里基于Java写的基础案例。
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.7.0</version>
</dependency>
</dependencies>
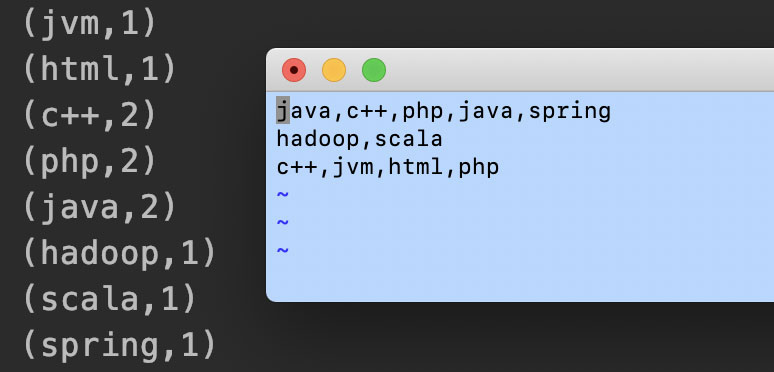
3.3、读取文件数据
这里直接读取文件中的数据,经过程序流程分析出每个单词出现的次数。
public class WordCount {
public static void main(String[] args) throws Exception {
// 读取文件数据
readFile () ;
}
public static void readFile () throws Exception {
// 1、执行环境创建
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
// 2、读取数据文件
String filePath = "/var/flink/test/word.txt" ;
DataSet<String> inputFile = environment.readTextFile(filePath);
// 3、分组并求和
DataSet<Tuple2<String, Integer>> wordDataSet = inputFile.flatMap(new WordFlatMapFunction(
)).groupBy(0).sum(1);
// 4、打印处理结果
wordDataSet.print();
}
// 数据读取个切割方式
static class WordFlatMapFunction implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector){
String[] wordArr = input.split(",");
for (String word : wordArr) {
collector.collect(new Tuple2<>(word, 1));
}
}
}
}
3.4、读取端口数据
在hop01服务上创建一个端口,并模拟一些数据发送到该端口:
[root@hop01 ~]# nc -lk 5566
c++,java
通过Flink程序读取并分析该端口的数据内容:
public class WordCount {
public static void main(String[] args) throws Exception {
// 读取端口数据
readPort ();
}
public static void readPort () throws Exception {
// 1、执行环境创建
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取Socket数据端口
DataStreamSource<String> inputStream = environment.socketTextStream("hop01", 5566);
// 3、数据读取个切割方式
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = inputStream.flatMap(
new FlatMapFunction<String, Tuple2<String, Integer>>()
{
@Override
public void flatMap(String input, Collector<Tuple2<String, Integer>> collector) {
String[] wordArr = input.split(",");
for (String word : wordArr) {
collector.collect(new Tuple2<>(word, 1));
}
}
}).keyBy(0).sum(1);
// 4、打印分析结果
resultDataStream.print();
// 5、环境启动
environment.execute();
}
}
四、运行机制
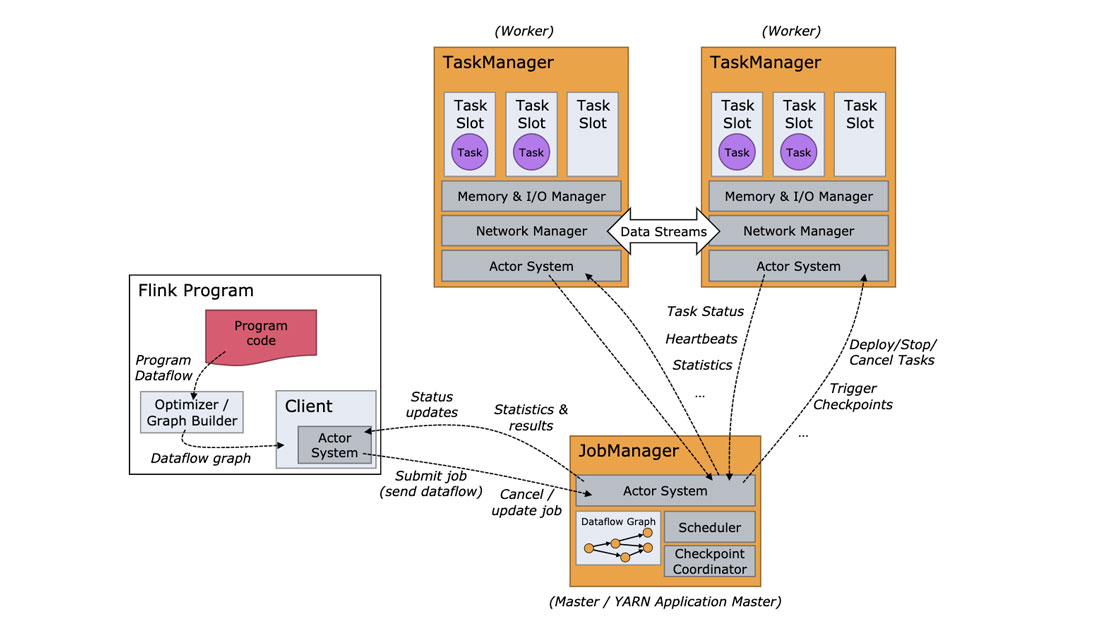
4.1、FlinkClient
客户端用来准备和发送数据流到JobManager节点,之后根据具体需求,客户端可以直接断开连接,或者维持连接状态等待任务处理结果。
4.2、JobManager
在Flink集群中,会启动一个JobManger节点和至少一个TaskManager节点,JobManager收到客户端提交的任务后,JobManager会把任务协调下发到具体的TaskManager节点去执行,TaskManager节点将心跳和处理信息发送给JobManager。
4.3、TaskManager
任务槽(slot)是TaskManager中最小的资源调度单位,在启动的时候就设置好了槽位数,每个槽位能启动一个Task,接收JobManager节点部署的任务,并进行具体的分析处理。
五、源代码地址
GitHub·地址
https://github.com/cicadasmile/big-data-parent
GitEE·地址
https://gitee.com/cicadasmile/big-data-parent
以上就是浅谈实时计算框架Flink集群搭建与运行机制的详细内容,更多关于实时计算框架 Flink集群搭建与运行机制的资料请关注我们其它相关文章!
相关推荐
-
Flink支持哪些数据类型?
一.支持的数据类型 Flink 对可以在 DataSet 或 DataStream 中的元素类型进行了一些限制.这样做的原因是系统会分析类型以确定有效的执行策略. 1.Java Tuple 和 Scala Case类: 2.Java POJO: 3.基本类型: 4.通用类: 5.值: 6.Hadoop Writables; 7.特殊类型 二.Flink之Tuple类型 Tuple类型 Tuple 是flink 一个很特殊的类型 (元组类型),是一个抽象类,共26个Tuple子类继承Tuple
-
如何使用Reactor完成类似Flink的操作
一.背景 Flink在处理流式任务的时候有很大的优势,其中windows等操作符可以很方便的完成聚合任务,但是Flink是一套独立的服务,业务流程中如果想使用需要将数据发到kafka,用Flink处理完再发到kafka,然后再做业务处理,流程很繁琐. 比如在业务代码中想要实现类似Flink的window按时间批量聚合功能,如果纯手动写代码比较繁琐,使用Flink又太重,这种场景下使用响应式编程RxJava.Reactor等的window.buffer操作符可以很方便的实现. 响应式编程框架也早已
-
Java lambda表达式实现Flink WordCount过程解析
这篇文章主要介绍了Java lambda表达式实现Flink WordCount过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 本篇我们将使用Java语言来实现Flink的单词统计. 代码开发 环境准备 导入Flink 1.9 pom依赖 <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>
-
Apache Flink 任意 Jar 包上传导致远程代码执行漏洞复现问题(漏洞预警)
漏洞描述 Apache Flink是一个用于分布式流和批处理数据的开放源码平台.Flink的核心是一个流数据流引擎,它为数据流上的分布式计算提供数据分发.通信和容错功能.Flink在流引擎之上构建批处理,覆盖本地迭代支持.托管内存和程序优化.近日有安全研究人员发现apache flink允许上传任意的jar包从而导致远程代码执行. 漏洞级别 高危 影响范围 Apache Flink <=1.9.1 漏洞复现 首先下载Apache Flink 1.9.1安装包并进行解压,之后进入bin文件夹内运行
-
大数据HelloWorld-Flink实现WordCount
所有的语言开篇都是Hello Word,数据处理引擎也有Hello Word.那就是Word Count.MR,Spark,Flink以来开篇第一个程序都是Word Count.那么今天Flink开始目标就是在本地调试出Word Count. 单机安装Flink 开始Flink之前先在本机尝试安装一下Flink,当然FLink正常情况下是部署的集群方式.作者比较穷,机器配置太低开不了几个虚拟机.所以只能先演示个单机的安装. Apache Flink需要在Java1.8+以上的环境中运行 . 所以
-

详解大数据处理引擎Flink内存管理
内存模型 Flink可以使用堆内和堆外内存,内存模型如图所示: flink使用内存划分为堆内内存和堆外内存.按照用途可以划分为task所用内存,network memory.managed memory.以及framework所用内存,其中task network managed所用内存计入slot内存.framework为taskmanager公用. 堆内内存包含用户代码所用内存.heapstatebackend.框架执行所用内存. 堆外内存是未经jvm虚拟化的内存,直接映射到操作系统的内存地
-
Apache FlinkCEP 实现超时状态监控的步骤详解
CEP - Complex Event Processing复杂事件处理. 订单下单后超过一定时间还未进行支付确认. 打车订单生成后超过一定时间没有确认上车. 外卖超过预定送达时间一定时限还没有确认送达. Apache FlinkCEP API CEPTimeoutEventJob FlinkCEP源码简析 DataStream和PatternStream DataStream 一般由相同类型事件或元素组成,一个DataStream可以通过一系列的转换操作如Filter.Map等转换为另一个Da
-
Flink开发IDEA环境搭建与测试的方法
一.IDEA开发环境 1.pom文件设置 <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.11.12</scala.version>
-
IDEA上运行Flink任务的实战教程
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS等: IDEA是常用的IDE,我们编写的flink任务代码如果能直接在IDEA运行,会给学习和开发带来很大便利,例如改完代码立即运行不用部署.断点.单步调试等: 环境信息 电脑:2019版13寸MacBook Pro,2.3 GHz 四核Intel Core i5,8 GB 2133 MHz LPD
-
浅谈实时计算框架Flink集群搭建与运行机制
一.Flink概述 1.1.基础简介 主要特性包括:批流一体化.精密的状态管理.事件时间支持以及精确一次的状态一致性保障等.Flink不仅可以运行在包括YARN.Mesos.Kubernetes在内的多种资源管理框架上,还支持在裸机集群上独立部署.在启用高可用选项的情况下,它不存在单点失效问题. 这里要说明两个概念: 边界:无边界和有边界数据流,可以理解为数据的聚合策略或者条件: 状态:即执行顺序上是否存在依赖关系,即下次执行是否依赖上次结果: 1.2.应用场景 Data Driven 事件驱动
-
浅谈node中的cluster集群
结论 虽然平常通过设置为CPU进程数的工作进程,但是可以超过这个数,并且并不是主进程先创建 if (cluster.isMaster) { // 循环 fork 任务 CPU i5-7300HQ 四核四进程 for (let i = 0; i < 6; i++) { cluster.fork() } console.log(chalk.green(`主进程运行在${process.pid}`)) } else { app.listen(1314) // export app 一个 Koa 服务器
-
浅谈减少Hyperf框架的扫描时间
原因 Hyperf框架为了防止用户更新组件后,代理缓存没有更新导致启动报错.增加了以下钩子. { "scripts": { "post-autoload-dump": [ "init-proxy.sh" ] } } 而init-proxy.sh脚本,会执行php bin/hyperf.php di:init-proxy命令清理代理缓存,并重新生成. $ composer init-proxy > init-proxy.sh ../../ R
-
浅谈Python flask框架
目录 1. flask 框架概述 1.1flask 框架优势 1.2flask 框架获取 1.3flask 框架使用 2. flask demo步骤 3. flask 基础功能 3.1路由功能 3.2模版提供 4.总结 前言: Python 面向对象的高级编程语言,以其语法简单.免费开源.免编译扩展性高,同时也可以嵌入到C/C++程序和丰富的第三方库,Python运用到大数据分析.人工智能.web后端等应用场景上. Python 目前主要流行的web框架:flask.Django.Tornad
-
浅谈基于Pytest框架的自动化测试开发实践
目录 01 - Pytest核心功能 02 - 创建测试项目 03 - 编写测试用例 04 - 执行测试用例 05 - 数据与脚本分离 06 - 参数化 07 - 测试配置管理 08 - 测试的准备与收尾 09 - 标记与分组 10 - 并发执行 11 - 测试报告 12 - 总结 参考资料 Pytest是Python的一种易用.高效和灵活的单元测试框架,可以支持单元测试和功能测试.本文不以介绍Pytest工具本身为目的,而是以一个实际的API测试项目为例,将Pytest的功能应用到实际的测试工
-
redis 分片集群搭建与使用教程
目录 前言 搭建集群架构图 前置准备 搭建步骤 创建集群 Redis散列插槽说明 集群伸缩(添加节点) 故障转移 使用redistemplate访问分片集群 前言 redis可以说在实际项目开发中使用的非常频繁,在redis常用集群中,我们聊到了redis常用的几种集群方案,不同的集群对应着不同的场景,并且详细说明了各种集群的优劣,本篇将以redis 分片集群为切入点,从redis 分片集群的搭建开始,详细说说redis 分片集群相关的技术点: 单点故障: 单机写(高并发写)瓶颈: 单机存储数据
-
redis集群搭建_动力节点Java学院整理
现在项目上用redis的话,很少说不用集群的情况,毕竟如果生产上只有一台redis会有极大的风险,比如机器挂掉,或者内存爆掉,就比如我们生产环境曾今也遭遇到这种情况,导致redis内存不够挂掉的情况,当然这些都是我们及其不能容忍的,第一个必须要做到高可靠,其次才是高性能,好了,下面我来逐一搭建一下. 一:Redis集群搭建 1. 下载 首先去官网下载较新的3.2.0版本,下载方式还是非常简单的,比如官网介绍的这样. $ wget http://download.redis.io/releases
-
使用集群搭建SSH的作用及这些命令的含义
阅读本文可以带着下面问题: 1.你是否了解$ ssh user@host 'mkdir -p .ssh的作用? 2.cat >> .ssh/authorized_keys' < ~/.ssh/id_rsa.pub的作用是什么? 3.什么是SSH? 4.如何将远程主机目录下面的所有文件,复制到用户的当前目录? authorized_keys文件 远程主机将用户的公钥,保存在登录后的用户主目录的$HOME/.ssh/authorized_keys文件中.公钥就是一段字符串,只要把它追加在au
-
fastdfs+nginx集群搭建的实现
一.简介fastdfs 1.什么是fastdfs fastdfs是一个轻量级的开源分布式文件系统: fastdfs主要解决了大容量的文件存储和高并发访问的问题,文件存取时实现了负载均衡: fastdfs实现了软件方式的RAID,可以使用廉价的IDE硬盘进行存储支持存储服务器在线扩容支持相同内容的文件只保存一份,节约磁盘空间: fastdfs只能通过Client API访问,不支持POSIX访问方式: fastdfs特别适合大中型网站使用,用来存储资源文件(如:图片.文档.音频.视频等等). 2.
-
MySQL之PXC集群搭建的方法步骤
一.PXC 介绍 1.1 PXC 简介 PXC是一套 MySQL 高可用集群解决方案,与传统的基于主从复制模式的集群架构相比 PXC 最突出特点就是解决了诟病已久的数据复制延迟问题,基本上可以达到实时同步.而且节点与节点之间,他们相互的关系是对等的.PXC 最关注的是数据的一致性,对待事物的行为时,要么在所有节点上执行,要么都不执行,它的实现机制决定了它对待一致性的行为非常严格,这也能非常完美的保证 MySQL 集群的数据一致性: 1.2 PXC特性和优点 完全兼容 MySQL. 同步复制,事务