python简单验证码识别的实现过程
目录
- 1. 环境准备
- 1.1 安装pillow 和 pytesseract
- 1.2 安装Tesseract-OCR.exe
- 1.3 更改pytesseract.py的ocr路径
- 2. 测试识别效果
- 3. 实战案例–实现古诗文网验证码自动识别登录
- 总结
1. 环境准备
1.1 安装pillow 和 pytesseract
python模块库需要 pillow 和 pytesseract 这两个库,直接pip install 安装就好了。
pip install pillow pip install pytesseract
1.2 安装Tesseract-OCR.exe
下载地址:ocr下载地址
建议下载最新稳定版本:
tesseract-ocr-w64-setup-v5.0.0.20190623.exe。
安装过程很简单,直接点击下一步就完事了,其间可以默认安装路径,也可以自定义安装路径,装好之后,把它的安装路径添加到环境变量中即可,如我的这样:
我的安装位置:

环境变量就这样加:

1.3 更改pytesseract.py的ocr路径
我们pip install pytesseract 之后,在python解释器安装位置包里可以找到pytesseract.py文件如下:
打开之后,更改:

至此,环境准备工作算是大功告成了。
2. 测试识别效果
ocr一直默认安装,起始就可以支持数字和英文字母识别的,接下来
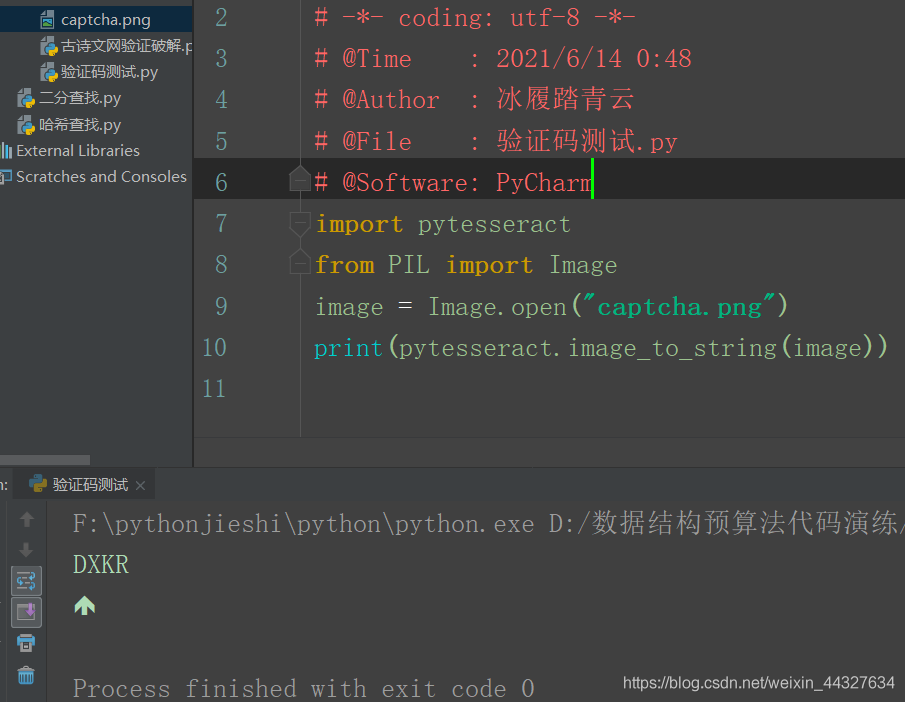
我们准备一张验证码图片:

将图片,命名为captcha.png,放到程序同一目录下
import pytesseract
from PIL import Image
image = Image.open("captcha.png")
print(pytesseract.image_to_string(image))
效果:
我们再尝试一下中文识别。
在进行识别之前我们要先下载好中文拓展语言包,
语言包地址
下载需要的的语言包,如下图,红框内为中文简体语言包:

下载后将该包直接放在ocr程序安装目录的tessdata文件夹里面即可。

找一张图片测试一下:

import pytesseract
from PIL import Image
image = Image.open("00.jpg")
print(pytesseract.image_to_string(image,lang='chi_sim'))
效果:

有时候文本识别率并不高,建议图像识别前,先对图像进行灰度化和 二值化
代码示例:
import pytesseract
from PIL import Image
file = r"00.jpg"
# 先对图像进行灰度化和 二值化
image = Image.open(file)
Img = image.convert('L') # 灰度化
#自定义灰度界限,这里可以大于这个值为黑色,小于这个值为白色。threshold可根据实际情况进行调整(最大可为255)。
threshold = 180
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
photo = Img.point(table, '1') #图片二值化
#保存处理好的图片
photo.save('01.jpg')
image = Image.open('01.jpg')
# 解析图片,lang='chi_sim'表示识别简体中文,默认为English
# 如果是只识别数字,可再加上参数config='--psm 6 --oem 3 -c tessedit_char_whitelist=0123456789'
content = pytesseract.image_to_string(image, lang='chi_sim')
print(content)
3. 实战案例–实现古诗文网验证码自动识别登录
import pytesseract
from PIL import Image
from selenium import webdriver
def save_captcha(path):
driver = webdriver.Chrome() # 创建浏览器对象
driver.maximize_window()
driver.implicitly_wait(10)
driver.get(url=url)
image = driver.find_element_by_id('imgCode')
image.screenshot(path)
return driver
def recognize_captcha(captcha_path):
captcha = Image.open(captcha_path) # 打开图片
grap = captcha.convert('L') # 对图片进行灰度化处理
data = grap.load() # 将图片对象加载成数据
w, h = captcha.size # 获取图片的大小(宽度,高度)
# 图片二值化处理
for x in range(w):
for y in range(h):
if data[x, y] < 140:
data[x, y] = 0
else:
data[x, y] = 255
code = pytesseract.image_to_string(grap) # 对图片进行识别
return code
def login(driver, code):
flag = True
email = '1242931802@qq.com' # 注册的古诗文网账号和密码
password = 'xxxx'
try:
driver.find_element_by_id('email').send_keys(email)
driver.find_element_by_id('pwd').send_keys(password)
driver.find_element_by_id('code').send_keys(code)
driver.implicitly_wait(10)
driver.find_element_by_id('denglu').click()
except Exception as ex:
flag = False
return flag
if __name__ == '__main__':
url = 'https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx'
captcha_path = './captcha.png'
count = 1
driver = save_captcha(captcha_path) # 获取驱动
code = recognize_captcha(captcha_path) # 获取验证码
print('识别验证码为:', code)
if login(driver, code):
driver.quit()
效果如下(有时候第一次可能识别失败,可以写个循环逻辑让它多识别几次,一般程序运行1-3次基本会识别成功):
总结
到此这篇关于python实现简单验证码识别的文章就介绍到这了,更多相关python验证码识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解Python验证码识别
以前写过一个刷校内网的人气的工具,Java的(以后再也不行Java程序了),里面用到了验证码识别,那段代码不是我自己写的:-) 校内的验证是完全单色没有任何干挠的验证码,识别起来比较容易,不过从那段代码中可以看到基本的验证码识别方式.这几天在写一个程序的时候需要识别验证码,因为程序是Python写的自然打算用Python进行验证码的识别. 以前没用Python处理过图像,不太了解PIL(Python Image Library)的用法,这几天看了看PIL,发现它太强大了,简直和ImageMagi
-

python脚本实现验证码识别
最近在折腾验证码识别.最终的脚本的识别率在92%左右,9000张验证码大概能识别出八千三四百张左右.好吧,其实是验证码太简单.下面就是要识别的验证码. 我主要用的是Python中的PIL库. 首先进行二值化处理.由于图片中的噪点颜色比较浅,所以可以设定一个阈值直接过滤掉.这里我设置的阈值是150,像素大于150的赋值为1,小于的赋为0. def set_table(a): table = [] for i in range(256): if i < a: table.append(0) else
-
python验证码识别教程之利用滴水算法分割图片
滴水算法概述 滴水算法是一种用于分割手写粘连字符的算法,与以往的直线式地分割不同 ,它模拟水滴的滚动,通过水滴的滚动路径来分割字符,可以解决直线切割造成的过分分割问题. 引言 之前提过对于有粘连的字符可以使用滴水算法来解决分割,但智商捉急的我实在是领悟不了这个算法的精髓,幸好有小伙伴已经实现相关代码. 我对上面的代码进行了一些小修改,同时升级为python3的代码. 还是以这张图片为例: 在以前的我们已经知道这种简单的粘连可以通过控制阈值来实现分割,这里我们使用滴水算法. 首先使用之前文章中介绍
-
python简单验证码识别的实现方法
利用SVM向量机进行4位数字验证码识别 主要是思路和步骤如下: 一,素材收集 检查环境是否包含有相应的库: 1.在cmd中,通过 pip list命令查看安装的库 2.再使用pip installRequests 安装Requests库 3.再次使用pip list 命令 4.利用python获取验证码资源 编写代码:_DownloadPic.py #!/usr/bin/nev python3 #利用python从站点下载验证码图片 import requests ## 1.在 http://w
-
Python验证码识别处理实例
一.准备工作与代码实例 (1)安装PIL:下载后是一个exe,直接双击安装,它会自动安装到C:\Python27\Lib\site-packages中去, (2)pytesser:下载解压后直接放C:\Python27\Lib\site-packages(根据你安装的Python路径而不同),同时,新建一个pytheeer.pth,内容就写pytesser,注意这里的内容一定要和pytesser这个文件夹同名,意思就是pytesser文件夹,pytesser.pth,及内容都要一样! (3)Te
-
python验证码识别的实例详解
其实关于验证码识别涉及很多方面的内容,入手难度大,但是入手后,可拓展性又非常广泛,可玩性极强,成就感也很足,对这感兴趣的朋友们下面跟着小编一起来学习学习吧. 依赖 sudo apt-get install python-imaging sudo apt-get install tesseract-ocr pip install pytesseract 利用google ocr来识别验证码 from PIL import Image import pytesseract image = Image
-
用Python进行简单图像识别(验证码)
这是一个最简单的图像识别,将图片加载后直接利用Python的一个识别引擎进行识别 将图片中的数字通过 pytesseract.image_to_string(image)识别后将结果存入到本地的txt文件中 #-*-encoding:utf-8-*- import pytesseract from PIL import Image class GetImageDate(object): def m(self): image = Image.open(u"C:\\a.png") text
-
python爬虫之验证码篇3-滑动验证码识别技术
滑动验证码介绍 本篇涉及到的验证码为滑动验证码,不同于极验证,本验证码难度略低,需要的将滑块拖动到矩形区域右侧即可完成. 这类验证码不常见了,官方介绍地址为:https://promotion.aliyun.com/ntms/act/captchaIntroAndDemo.html 使用起来肯定是非常安全的了,不是很好通过机器检测 如何判断验证码类型 这个验证码的标识一般比较明显,在页面源码中一般存在一个 nc.js 基本可以判定是阿里云的验证码了 <script type="text/j
-
python入门教程之识别验证码
前言 验证码?我也能破解? 关于验证码的介绍就不多说了,各种各样的验证码在人们生活中时不时就会冒出来,身为学生日常接触最多的就是教务处系统的验证码了,比如如下的验证码: 识别办法 模拟登陆有着复杂的步骤,在这里咱们不管其他操作,只负责根据输入的一张验证码图片返回一个答案字符串. 我们知道验证码为了制作干扰,会把图片弄成五颜六色的样子,而我们首先就是要去除这些干扰,这一步就需要不断试验了,增强图片色彩,加大对比度等等都可以产生帮助. 在经过各种对图片的操作之后,终于找到了比较完美的去除干扰方案.可
-
Python验证码识别的方法
本文实例讲述了Python验证码识别的方法.分享给大家供大家参考.具体实现方法如下: #encoding=utf-8 import Image,ImageEnhance,ImageFilter import sys image_name = "./22.jpeg" #去处 干扰点 im = Image.open(image_name) im = im.filter(ImageFilter.MedianFilter()) enhancer = ImageEnhance.Contrast(