Python爬虫爬取属于自己的地铁线路图
目录
- 一.高德地图数据爬取
- 1.爬取思路
- 2.python核心代码
- 二.生成shp文件并导出图片
- 1.文本点生成shp代码
- 2.Arcmap设置样式
前言:
网上找的地铁线路图大多数都不太清晰,而且有水印,对本人这种视力不好的人来说看起来是真的不方便。所以能不能制作属于自己的地铁线路图呢?好不好看无所谓,主要是高清无码,要看清楚各个站点!想了想,主要还是缺乏站点数据,有数据了图自然就有了。经过网上查询,发现高德地图上有专门的地铁线路图,但是不能导出数据或图片,只好自己想办法抓取了。下面以西安地铁线路图为例介绍方法。
一.高德地图数据爬取
1.爬取思路
首先,谷歌浏览器打开 高德地图官网 ,点击上方菜单栏 地铁 进入地铁线路网站如下,网址:http://map.amap.com/subway/index.html。
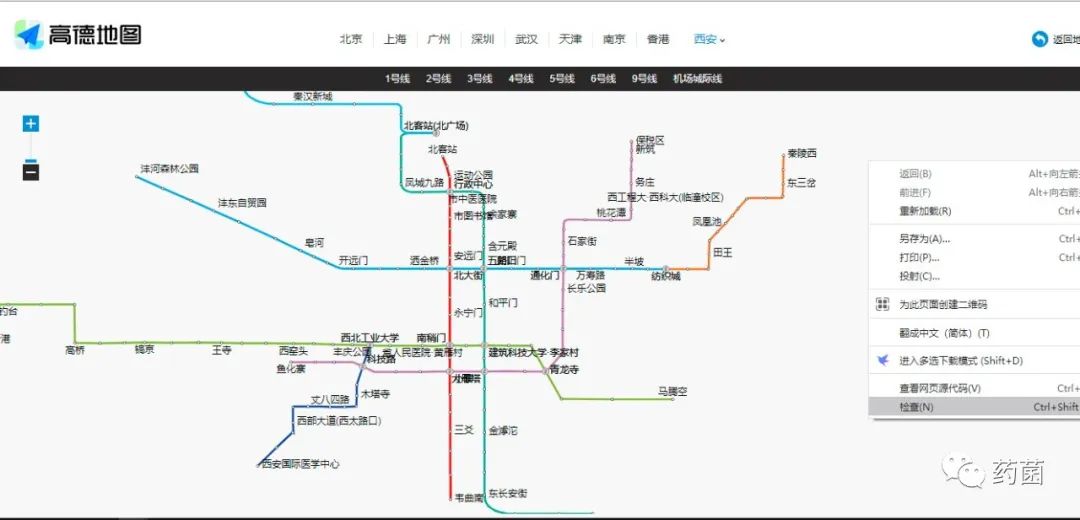
按 F12 或右击 检查 进入调试页面,点击 Network 选项。在网页上先点击 西安 ,可以发现箭头2出新增两行响应信息,鼠标左击可以发现箭头3处出现真实的请求地址等信息。
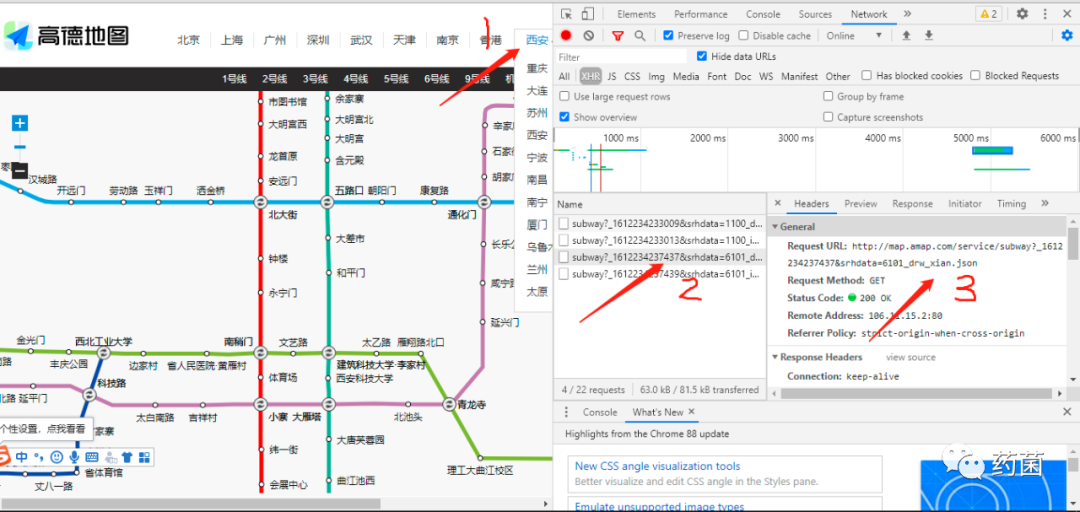
复制请求URL地址(http://map.amap.com/service/subway?_1612234237437&srhdata=6101_drw_xian.json),在浏览器新页面打开可以看见返回的是 json 数据,里面包含了各线路站点信息,正是我们想要的。

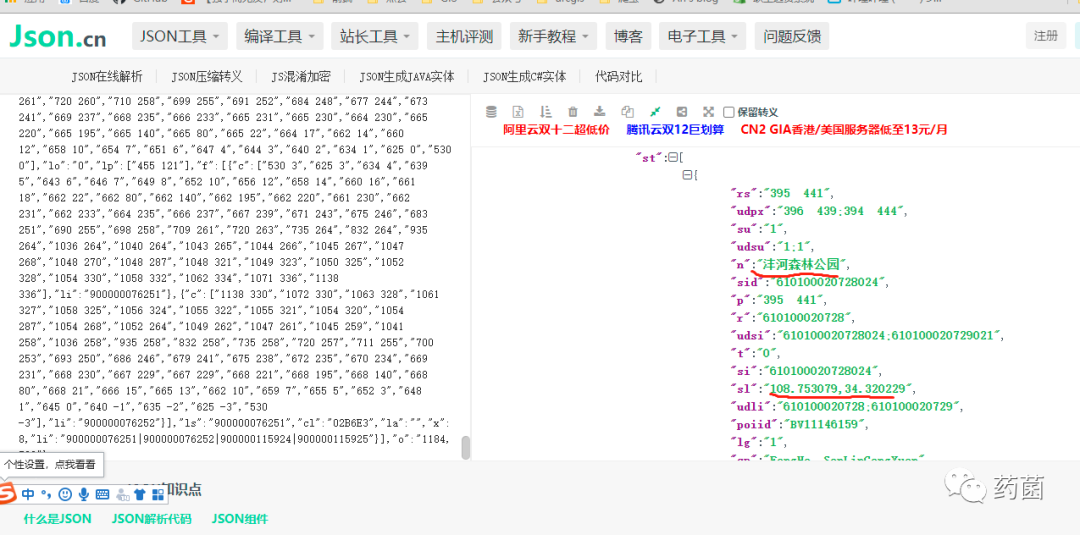
可以复制json数据在json在线验证网站上进行分析,以便于后续解析数据(网址:http://www.json.cn/#)。如下图所示,显示的是1号线沣河森林公园站的相关信息:中文名称、经纬度(应该是火星坐标系?)、拼音名称等。
我们通过python爬虫爬取各线路各站点的 名称、经纬度 信息,导出到文本文件,以供后续使用。
2.python核心代码
获取网页内容:
def getHtml(url):
user_agent = random.choice(USER_AGENTS)
headers = {
"Host":"map.amap.com",
'User-Agent': user_agent
}
try:
response = requests.get(url, headers=headers)
#print(response.url)
text = response.content
return text
except:
print("爬取失败!")
解析json数据:
def parse_page(text):
lines_list = json.loads(text).get('l')
# 地铁线路信息表
lineInfo_list = []
for line in lines_list:
#每条线的信息集合
lineInfo = {}
lineInfo['ln'] = line.get('ln')
print(lineInfo['ln'])
#线路站点列表
station_list = []
st_list = line.get('st')
for st in st_list:
station_dict = {}
station_dict['name'] = st.get('n')
coord = st.get('sl')
station_dict['lat'] = coord.split(',')[0]
station_dict['lon'] = coord.split(',')[-1]
print("站名称:", station_dict['name'])
print("经度:", station_dict['lat'])
print("纬度:", station_dict['lon'])
station_list.append(station_dict)
#pass
print('-----------------------------------')
lineInfo['st'] = station_list
lineInfo['kn'] = line.get('kn')
lineInfo['ls'] = line.get('ls')
lineInfo['cl'] = line.get('cl')
lineInfo_list.append(lineInfo)
#返回各线路信息列表
return lineInfo_list
保存站点数据(站名称、经纬度):
def save_file(filename, lineInfo):
#print("开始写入文件......")
with open(filename, 'a', encoding='utf-8') as f:
for st in lineInfo['st']:
f.write(st['name'] + " " + st['lat'] + " " + st['lon'] + "\n")
#print("写入文件完成!")
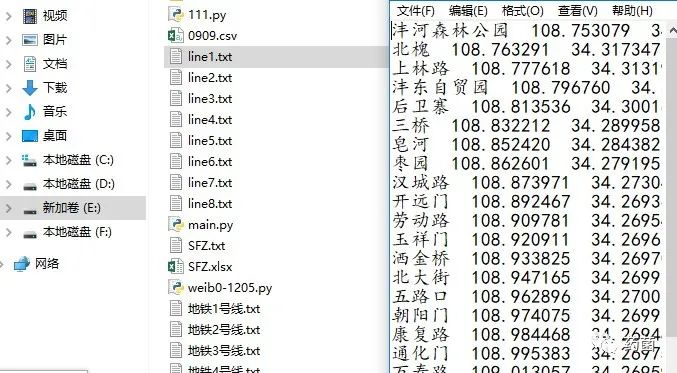
爬取完成后,生成的数据如下:
二.生成shp文件并导出图片
主要思路:调用Arcpy函数生成shp文件-——>点转线——>设置符号样式——>导出图片。
1.文本点生成shp代码
def create_shp(text,dirpath):
point_shpname = text.split('.')[0] + "_point.shp"
line_shpname = text.split('.')[0] + "_line.shp"
f = open(text, 'r')
lines = f.readlines()
spatRef = arcpy.SpatialReference(4326)
createFC = arcpy.CreateFeatureclass_management(dirpath, point_shpname, "POINT", "", "", "",spatRef)
arcpy.AddField_management(createFC, "name", "TEXT")
arcpy.AddField_management(createFC, "lat", "DOUBLE")
arcpy.AddField_management(createFC, "lon", "DOUBLE")
cur = arcpy.InsertCursor(createFC)
for line in lines:
info = line.strip().split(" ")
row = cur.newRow()
name = info[0]
point = arcpy.Point()
point.X = float(info[1])
point.Y = float(info[2])
pointGeometry = arcpy.PointGeometry(point)
row.shape = pointGeometry
row.name = name
row.lon = point.X
row.lat = point.Y
cur.insertRow(row)
#站点生成线
arcpy.PointsToLine_management(point_shpname, line_shpname)
2.Arcmap设置样式
将生成的点shp与线shp矢量文件加载到arcmap当中设置样式与符号大小,然后导出地图为图片。记得导出地图时图片分辨率选择为300dpi。
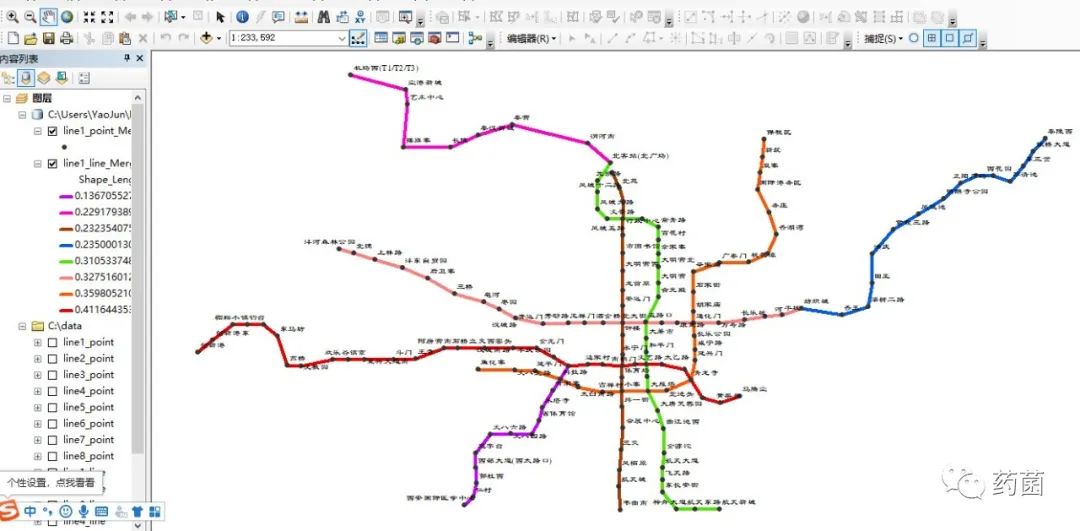
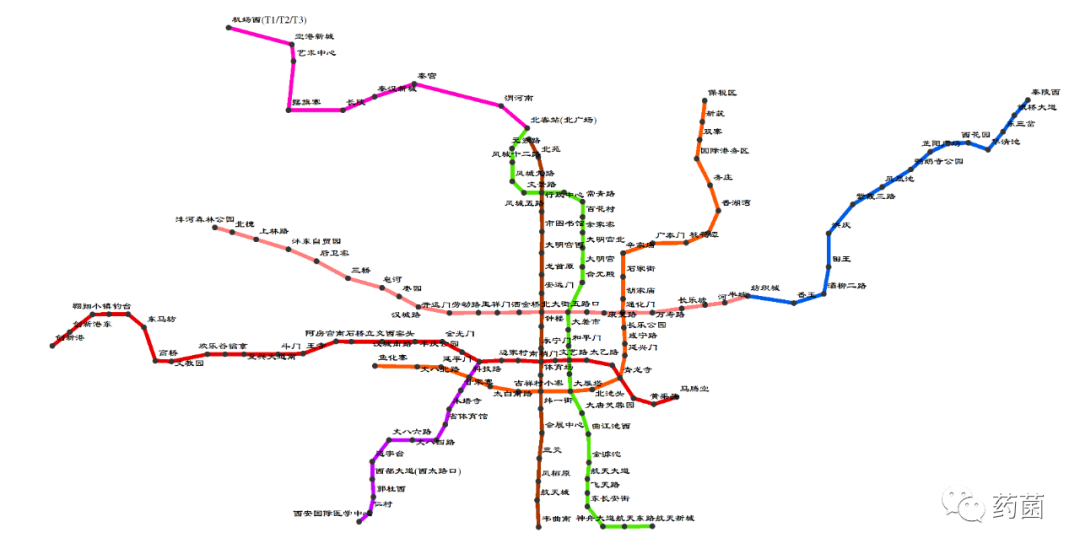
最终,如下图所示属于自己的地铁线路图就制作完成了。图片估计上传到微信上就不是原图了,又会变模糊,但是实际看起来还是比较清楚的。
到此这篇关于Python爬虫爬取属于自己的地铁线路图的文章就介绍到这了,更多相关Python爬取地铁线路图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫爬取属于自己的地铁线路图
目录 一.高德地图数据爬取 1.爬取思路 2.python核心代码 二.生成shp文件并导出图片 1.文本点生成shp代码 2.Arcmap设置样式 前言: 网上找的地铁线路图大多数都不太清晰,而且有水印,对本人这种视力不好的人来说看起来是真的不方便.所以能不能制作属于自己的地铁线路图呢?好不好看无所谓,主要是高清无码,要看清楚各个站点!想了想,主要还是缺乏站点数据,有数据了图自然就有了.经过网上查询,发现高德地图上有专门的地铁线路图,但是不能导出数据或图片,只好自己想办法抓取了.下面以西安地铁
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
Python爬虫爬取新浪微博内容示例【基于代理IP】
本文实例讲述了Python爬虫爬取新浪微博内容.分享给大家供大家参考,具体如下: 用Python编写爬虫,爬取微博大V的微博内容,本文以女神的微博为例(爬新浪m站:https://m.weibo.cn/u/1259110474) 一般做爬虫爬取网站,首选的都是m站,其次是wap站,最后考虑PC站.当然,这不是绝对的,有的时候PC站的信息最全,而你又恰好需要全部的信息,那么PC站是你的首选.一般m站都以m开头后接域名, 所以本文开搞的网址就是 m.weibo.cn. 前期准备 1.代理IP 网上有
-
Python爬虫爬取煎蛋网图片代码实例
这篇文章主要介绍了Python爬虫爬取煎蛋网图片代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 今天,试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代码: import urllib.request import os def url_open(url): req = urllib.reques