SQLSERVER如何查看索引缺失及DMV使用介绍
当大家发现数据库查询性能很慢的时候,大家都会想到加索引来优化数据库查询性能,但是面对一个复杂的SQL语句,找到一个优化的索引组合对人脑来讲,真的不是一件很简单的事。
好在SQLSERVER提供了两种“自动”功能,给你建议,该怎么调整索引
第一种是使用DMV
第二种是使用DTA (database engine tuning advisor) 数据库引擎优化顾问
这篇文章主要讲第一种
从SQL2005以后,在SQLSERVER对任何一句语句做编译的时候,都会去评估一下,
这句话是不是缺少什么索引的支持,如果他认为是,他还会预估,如果有这麽一个索引
他的性能能提高多少
SQLSERVER有几个动态管理视图
sys.dm_db_missing_index_details
sys.dm_db_missing_index_groups
sys.dm_db_missing_index_group_stats
sys.dm_db_missing_index_columns(index_handle)
sys.dm_db_missing_index_details
这个DMV记录了当前数据库下所有的missing index的信息,他针对的是SQLSERVER从启动以来所有运行的语句,
而不是针对某一个查询。DBA可以看看,哪些表格SQLSERVER对他是最有“意见”的
以下是这个DMV的各个字段的解释:
1、index_handle:标识特定的缺失索引。该标识符在服务器中是唯一的。index_handle 是此表的密钥
2、database_id :标识带有缺失索引的表所驻留的数据库
3、object_id :标识索引缺失的表
4、equality_columns:构成相等谓词的列的逗号分隔列表 即哪个字段缺失了索引会在这里列出来(简单来讲就是where 后面的筛选字段),
谓词的形式如下:table.column =constant_value
5、inequality_columns :构成不等谓词的列的逗号分隔列表,例如以下形式的谓词:table.column > constant_value “=”之外的任何比较运算符都表示不相等。
6、included_columns:用于查询的涵盖列的逗号分隔列表(简单来讲就是 select 后面的字段)。
7、statement:索引缺失的表的名称
比如下面这个查询结果

CREATE INDEX idx_SalesOrderDetail_test_ProductID_IncludeIndex ON SalesOrderDetail_test(ProductID) INCLUDE(SalesOrderID)
在ProductID上创建索引,SalesOrderID作为包含性列的索引
注意事项:
由 sys.dm_db_missing_index_details 返回的信息会在查询优化器优化查询时更新,因而不是持久化的。
缺失索引信息只保留到重新启动 SQL Server 前。如果数据库管理员要在服务器回收后保留缺失索引信息,
则应定期制作缺失索引信息的备份副本
sys.dm_db_missing_index_columns(index_handle)
返回与缺少索引(不包括空间索引)的数据库表列有关的信息,sys.dm_db_missing_index_columns 是一个动态管理函数
字段解释
index_handle:唯一地标识缺失索引的整数。
sys.dm_db_missing_index_groups
返回有关特定缺失索引组中包含的缺失索引(不包括空间索引)的信息
sys.dm_db_missing_index_group_stats
返回缺失索引组的摘要信息,不包括空间索引
这个视图说白了就是预估有这麽一个索引,他的性能能提高多少
有一个字段比较重要:
avg_user_impact: 实现此缺失索引组后,用户查询可能获得的平均百分比收益。该值表示如果实现此缺失索引组,则查询成本将按此百分比平均下降。
就是说,增加了这个缺失索引,性能可以提高的百分比
--查询提供缺失索引的数据库、架构和表的名称。它还提供应该用于索引键的列的名称
USE [AdventureWorks]
GO
SELECT migs.group_handle, mid.*
FROM sys.dm_db_missing_index_group_stats AS migs
INNER JOIN sys.dm_db_missing_index_groups AS mig
ON (migs.group_handle = mig.index_group_handle)
INNER JOIN sys.dm_db_missing_index_details AS mid
ON (mig.index_handle = mid.index_handle)
WHERE migs.group_handle = 2

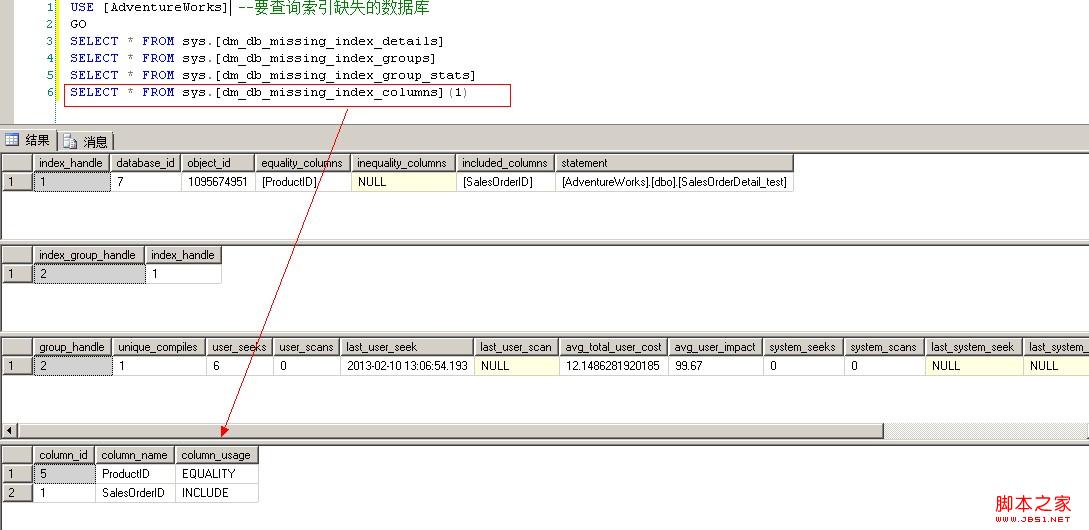
USE [AdventureWorks] --要查询索引缺失的数据库
GO
SELECT * FROM sys.[dm_db_missing_index_details]
SELECT * FROM sys.[dm_db_missing_index_groups]
SELECT * FROM sys.[dm_db_missing_index_group_stats]
SELECT * FROM sys.[dm_db_missing_index_columns](1) --1 :1是根据dm_db_missing_index_details查出来的
我估计XX大侠做的SQLSERVER索引优化器也使用了"sys.dm_db_missing_index_details" 这个DMV

刚才看了一下,好像有错别字:Total Cost不是Totol Cost
暂时不知道Total Cost跟Improvement Measure怎麽算出来的
注意:
最后大家还需要注意一下,虽然这些DMV给出的建议还是比较合理的。
但是,DBA还是需要去确认一下建议。因为这个建议完全是根据语句本身给出的,
没有考虑对其他语句的影响,也没有考虑维护索引的成本,所以是很片面的。
其准确性,也要再确认一下
上面几个DMV的字段解释,大家可以看一下MSDN,非常详细
sys.dm_db_missing_index_group_stats
msdn:http://msdn.microsoft.com/zh-cn/library/ms345421.aspx
sys.dm_db_missing_index_groups
msdn:http://msdn.microsoft.com/zh-cn/library/ms345407.aspx
sys.dm_db_missing_index_columns([sql_handle])
msdn:http://msdn.microsoft.com/zh-cn/library/ms345364.aspx
sys.dm_db_missing_index_details
msdn:http://msdn.microsoft.com/zh-cn/library/ms345434.aspx
相关推荐
-

sqlserver索引的原理及索引建立的注意事项小结
聚集索引,数据实际上是按顺序存储的,数据页就在索引页上.就好像参考手册将所有主题按顺序编排一样.一旦找到了所要搜索的数据,就完成了这次搜索,对于非聚集索引,索引是安全独立于数据本身结构的,在索引中找到了寻找的数据,然后通过指针定位到实际的数据. SQL Server中的索引使用标准的B-树来存储他们的信息,如下图所示,B-树通过查找索引中的一个关键之来提供对于数据的快速访问,B-树以相似的键记录聚合在一起,B不代表二叉(binary),而是代表balanced(平衡的),而B-树的一个核心作用就
-
详解SQL Server的聚焦过滤索引
前言 这一节我们还是继续讲讲索引知识,前面我们聚集索引.非聚集索引以及覆盖索引等,在这其中还有一个过滤索引,通过索引过滤我们也能提高查询性能,简短的内容,深入的理解. 过滤索引,在查询条件上创建非聚集索引(1) 过滤索引是SQL 2008的新特性,被应用在表中的部分行,所以利用过滤索引能够提高查询,相对于全表扫描它能减少索引维护和索引存储的代价.当我们在索引上应用WHERE条件时就是过滤索引.也就是满足如下格式: CREATE NONCLUSTERED INDEX <index name> O
-
浅析SQL Server 聚焦索引对非聚集索引的影响
前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任何意义,学习的过程必须同时也是一个思考的过程,无论是独立思考也好还是查资料也罢都是思考而非走马观花,要不然过一段时间又会健忘.简短的内容,深入的理解. 话题 非聚集索引定义:非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针.你真的理解了吗??你能举出例子吗?
-
SQL Server 数据库索引其索引的小技巧
一.什么是索引 减少磁盘I/O和逻辑读次数的最佳方法之一就是使用[索引] 索引允许SQL Server在表中查找数据而不需要扫描整个表. 1.1.索引的好处: 当表没有聚集索引时,成为[堆或堆表] [堆]是一堆未加工的数据,以行标识符作为指向存储位置的指针.表数据没有顺序,也不能搜索,除非逐行遍历.这个过程称为[扫描].当存在聚集索引时,非聚集索引的指针由聚集索引所定义的值组成,所以聚集索引变得非常重要. 因为页面大小固定,所以列越少,所能存储的行就越多.由于非聚集索引通常不包含所有列,所以一般
-
详解sqlserver查询表索引
SELECT 索引名称=a.name ,表名=c.name ,索引字段名=d.name ,索引字段位置=d.colid FROM sysindexes a JOIN sysindexkeys b ON a.id=b.id AND a.indid=b.indid JOIN sysobjects c ON b.id=c.id JOIN syscolumns d ON b.id=d.id AND b.colid=d.colid WHERE a.indid NOT IN(0,255) -- and
-
SQLSERVER全文目录全文索引的使用方法和区别讲解
先介绍一下SQLSERVER中的存储类对象,哈哈,先介绍一下概念嘛,让新手老手都有一个认知SQLSERVER Management Studio将[全文目录].[分区函数]以及[分区方案]节点纳入其[对象资源管理器]的[存储]节点之中,如下图所示: 全文目录 数据库[存储]|[全文目录]节点是用于保存和管理[全文索引]的节点.全文目录通常是由同一数据库中的零个或多个数据表的全文索引构成的.需要注意的是,只能为每个数据表创建一个全文索引.因此,一旦在某个数据表上创建了全文索引,那么该数据表将只能隶
-
SQL_Server全文索引的用法解析
复制代码 代码如下: --1.为数据库启用SQL Server全文索引EXEC sp_fulltext_database 'enable' --2.创建全文目录--(此处若出错"未安装全文搜索或无法加载某一全文组件",则可能是未启动或未安装此服务)EXEC sp_fulltext_catalog 'Ask91Fable', 'create', 'D:\Data2005\Ask_91_Index' --3.指定要进行全文搜索的表--(可能出错"...全文搜索键必须是唯一的.不可
-
浅述SQL Server的聚焦强制索引查询条件和Columnstore Index
前言 本节我们再来穿插讲讲索引知识,后续再讲数据类型中的日期类型,简短的内容,深入的理解. 强制索引查询条件 前面我们也讲了一点强制索引查询的知识,本节我们再来完整的讲述下 (1)SQL Server使用默认索引 USE TSQL2012 GO SELECT * FROM Sales.Orders 上述就不用我再啰嗦了,使用默认主键创建的聚集索引来执行查询执行计划. (2)SQL Server使用强制索引 USE TSQL2012 GO SELECT custid FROM Sales.Orde
-
sqlserver2005自动创建数据表和自动添加某个字段索引
创建数据表的SQL语句如下: string tatlename = "T_useruid";//定义一个变量.用于自动创建数据表的名称,当前表名为:T_useruid string sql = "CREATE TABLE [dbo].[" + tatlename + "]([Cid] [int] IDENTITY(1,1) NOT NULL,[Uid] [nchar](32) COLLATE Chinese_PRC_CI_AS NULL,CONSTRAIN
-
SQLSERVER对索引的利用及非SARG运算符认识
写SQL语句的时候很多时候会用到filter筛选掉一些记录,SQL对筛选条件简称:SARG(search argument/SARG) 复制代码 代码如下: where amount>4000 and amount<6000上面这句就是筛选条件 当然这里不是说SQLSERVER的where子句,是说SQLSERVER对索引的利用在SQLSERVER对于没有SARG运算符的表达式,索引是没有用的,SQLSERVER对它们很难使用比较优化的做法. 意思是说,如果你的SQL语句中没有where子句包
-
SQL_Server全文索引的使用实例演示
本文示范完整的SQL SERVER数据库全文索引以pubs数据库为例首先,介绍利用系统存储过程创建全文索引的具体步骤:1) 启动数据库的全文处理功能 (sp_fulltext_database)2) 建立全文目录 (sp_fulltext_catalog)3) 在全文目录中注册需要全文索引的表 (sp_fulltext_table)4) 指出表中需要全文索引的列名 (sp_fulltext_column)5) 为表
-
浅析SQL Server的聚焦使用索引和查询执行计划
前言 上一篇<浅析SQL Server 聚焦索引对非聚集索引的影响>我们讲了聚集索引对非聚集索引的影响,对数据库一直在强调的性能优化,所以这一节我们统筹讲讲利用索引来看看查询执行计划是怎样的,简短的内容,深入的理解. 透过索引来看查询执行计划 我们首先来看看第一个例子 1.默认使用索引 USE TSQL2012 GO SELECT orderid FROM Sales.Orders SELECT * FROM Sales.Orders 上述我们看到第2个查询的所需要的开销是第1个查询开销的3倍
-
SQL SERVER 2008 R2 重建索引的方法
参考sys.dm_db_index_physical_stats 检查索引碎片情况 1.SELECT 2.OBJECT_NAME(object_id) as objectname, 3.object_id AS objectid, 4.index_id AS indexid, 5.partition_number AS partitionnum, 6.avg_fragmentation_in_percent AS fra 7.FROM sys.dm_db_index_physical_stats