深入浅析hbase的优点
hbase是运行在Hadoop上的NoSQL数据库,它是一个分布式的和可扩展的大数据仓库,也就是说HBase能够利用HDFS的分布式处理模式,并从Hadoop的MapReduce程序模型中获益。这意味着在一组商业硬件上存储许多具有数十亿行和上百万列的大表。除去Hadoop的优势,HBase本身就是十分强大的数据库,它能够融合key/value存储模式带来实时查询的能力,以及通过MapReduce进行离线处理或者批处理的能力。总的来说,Hbase能够让你在大量的数据中查询记录,也可以从中获得综合分析报告。
谷歌曾经面对过一个挑战的问题:如何能在整个互联网上提供实时的搜索结果?答案是它本质上需要将互联网缓存,并重新定义在这样庞大的缓存上快速查找的新方法。为了达到这个目的,定义如下技术:
·谷歌文件系统GFS:可扩展分布式文件系统,用于大型的、分布式的、数据密集型的应用程序。
·BigTable:分布式存储系统,用于管理被设计成规模很大的结构化数据:来自数以千计商用服务器的PB级别的数据。
·MapReduce:一个程序模型,用于处理和生成大数据集的相关实现。
在谷歌发布这些技术的文档之后,不久以后我们就看到了它们的开源实现版本,就在2007年,MikeCafarella发布了BigTable开源实现的代码,他称其为HBase,自此,HBase成为Apache的顶级项目,并运行在Facebook,Twitter,Adobe……仅举几个例子。
HBase不是一个关系型数据库,它需要不同的方法定义你的数据模型,HBase实际上定义了一个四维数据模型,下面就是每一维度的定义:
·行键:每行都有唯一的行键,行键没有数据类型,它内部被认为是一个字节数组。
·列簇:数据在行中被组织成列簇,每行有相同的列簇,但是在行之间,相同的列簇不需要有相同的列修饰符。在引擎中,HBase将列簇存储在它自己的数据文件中,所以,它们需要事先被定义,此外,改变列簇并不容易。
·列修饰符:列簇定义真实的列,被称之为列修饰符,你可以认为列修饰符就是列本身。
·版本:每列都可以有一个可配置的版本数量,你可以通过列修饰符的制定版本获取数据。
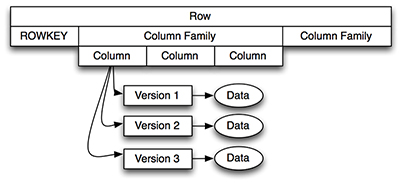
Figure1.HBaseFour-Dimensional Data Model
如图1中所示,通过行键获取一个指定的行,它由一个或多个列簇构成,每个列簇有一个或多个列修饰符(图1中称为列),每列又可以有一个或多个版本。为了获取指定数据,你需要知道它的行键、列簇、列修饰符以及版本。当设计HBase数据模型时,对考虑数据是如何被获取是十分有帮助的。你可以通过以下两种方式获得HBase数据:
·通过他们的行键,或者一系列行键的表扫描。
·使用map-reduce进行批操作
这种双重获取数据的方法使得HBase变得十分强大,典型地,在Hadoop中存储数据意味着它对离线或批处理方式分析是有益的(尤其是批处理分析),但是,对实时获取是不必要的。HBase通过key/value存储来支持实时分析,以及通过map-reduce支持批处理分析。让我们首先来看实时数据获取,作为key/value存储,key是行键,value是列簇的集合,如图2所示。
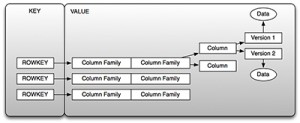
Figure2.HBaseas a Key/Value Store
如你在图2中看到的,key是我们所提到过的行键,value是列簇的集合。你可以通过key检索到value,或者换句话说,你可以通过行键“得到”行,或者你能通过给定起始和终止行键检索一系列行,这就是前面提到的表扫描。你不能实时的查询一个列的值,这就引出了一个重要的话题:行键的设计。
有两个原因令行键的设计十分重要:
·表扫描是对行键的操作,所以,行键的设计控制着你能够通过HBase执行的实时/直接获取量。
·当在生产环境中运行HBase时,它在HDFS上部运行,数据基于行键通过HDFS,如果你所有的行键都是以user-开头,那么很有可能你大部分数据都被分配一个节点上(违背了分布式数据的初衷),因此,你的行键应该是有足够的差异性以便分布式地通过整个部署。
你定义行键的方式取决于你想怎样存取那些行。如果你想以用户为基础存储数据,那么一个策略是利用字节队列在HBase中存储行键,所以我们可以创建一个用户ID的哈希(例如MD5或SHA-1),然后在哈希后面附上时间(long类型)。使用哈希有两个重点:(1)是它能够将value分散开,数据能够分布式地通过簇,(2)是它确保key的长度是一致的,以更加容易在表扫描中使用。
讲了足够多的理论,下面部分向你展示如何搭建HBase环境,并如何通过命令行使用。
你可以从Apache网站下载HBase,在写本文时,最新的版本是0.98.5,HBase团队推荐你在UNIX/Linux环境下安装HBase,如果你想在Windows下运行,你需要先安装Cygwin,并在这上运行HBase。当你下载完这些文件,解压到硬盘上。此外,你还需要安装Java环境,如果你还没有,从Oracle网站下载Java环境。在环境配置中添加名为HBASE_HOME的变量,值为你解压HBase文件的根目录,随后,执行bin文件夹下的start-hbase.sh脚本,它会在下面目录输出日志文件:
$HBASE_HOME/logs/
你可以在浏览器中输入下面URL测试是否安装正确:
http://localhost:60010
如果安装正确,你应该看到下面界面。
Figure3.HBaseManagement Screen
让我们开始用命令行操作HBase,在HBasebin目录下执行下面命令:
./hbase shell
你应该看到如下类似的输出:
HBase Shell; enter'help' for list of supported commands. Type "exit" toleave the HBase Shell Version0.98.5-hadoop2, rUnknown, MonAug4 23:58:06 PDT2014 hbase(main):001:0>
创建一个名为PageViews的表,并具有名为info的列簇:
hbase(main):002:0> create'PageViews', 'info' 0 row(s) in 5.3160seconds => Hbase::Table- PageViews
每张表至少要有一个列簇,因此我们创建了info,现在,看看我们的表,执行下面list命令:
hbase(main):002:0>list TABLE PageViews 1 row(s) in 0.0350seconds =>["PageViews"]
如你所见,list命令返回一个名为PageViews的表,我们可以通过describe命令得到表的更多信息:
hbase(main):003:0> describe'PageViews'
DESCRIPTIONENABLED
'PageViews',{NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER=> 'ROW',
REPLICATION_SCOPE=> '0', VERSIONS => '1', COMPRESSION => 'NONEtrue
',MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS=> 'false',
BLOCKSIZE=> '65536', IN_MEMORY => 'false', BLOCKCACHE =>'true'}
1 row(s) in 0.0480seconds
Describe命令返回表的详细信息,包括列簇的列表,这里我们创建的仅有一个:info,现在为表添加以下数据,下面命令是在info中添加新的行:
hbase(main):004:0> put'PageViews', 'rowkey1', 'info:page', '/mypage' 0 row(s) in 0.0850seconds
Put命令插入一条行键为rowkey1的新纪录,指定在info下的page列,插入值为/mypage的记录,我们随后可以通过get命令通过行键rowkey1查询到这条记录:
hbase(main):005:0> get'PageViews', 'rowkey1' COLUMNCELL info:pagetimestamp=1410374788088, value=/mypage 1 row(s) in 0.0250seconds
你可以看到列info:page,或者更多具体的列,其值为/mypage,并带有时间戳表明该条记录是什么时候插入的。让我们在做表扫描之前再添加一行:
hbase(main):006:0> put'PageViews', 'rowkey2', 'info:page', '/myotherpage' 0 row(s) in 0.0050seconds
现在我们有两行记录了,让我们查询出PageViews表的所有记录:
hbase(main):007:0> scan'PageViews' ROWCOLUMN+CELL rowkey1column=info:page, timestamp=1410374788088, value=/mypage rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage 2 row(s) in 0.0350seconds
如前面所提到的,我们不能查询本身,但是我们可以对表进行scan操作,如果你执行scantable命令,它会返回表中所有行,这很有可能不是你想要做的。你可以给出行的范围来限制返回的结果,让我们插入一带有s开头行键的新记录:
hbase(main):012:0> put'PageViews', 'srowkey2', 'info:page', '/myotherpage'
现在,如果我增加点限制,想查询行键在r和s之间的记录,可以使用如下结构:
hbase(main):014:0> scan'PageViews', { STARTROW => 'r', ENDROW => 's' }
ROWCOLUMN+CELL
rowkey1column=info:page, timestamp=1410374788088, value=/mypage
rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage
2 row(s) in 0.0080seconds
这个scan返回了仅有s开头的记录,这个类比是基于全行键上的,所以rowkey1比r大,所有它被返回了。另外,scan的结果包含了所指范围的STARTROW,但不包含ENDROW,注意,ENDROW不是必须指定的,如果我们执行相同查询只给出了STARTROW,那么我们会得到行键比r大的所有记录。
hbase(main):013:0> scan'PageViews', { STARTROW => 'r' }
ROWCOLUMN+CELL
rowkey1column=info:page, timestamp=1410374788088, value=/mypage
rowkey2column=info:page, timestamp=1410374823590,value=/myotherpage
srowkey2column=info:page,timestamp=1410375975965, value=/myotherpage
3 row(s) in 0.0120seconds
HBase是一种NoSQL,通常被称为Hadoop Database,它是开源并基于Google BigTable白皮书,HBase运行在HDFS之上,因此使它具有高度可扩展性,并支持Hadoopmap-reduce程序设计模型。HBase有两种访问方式:通过行键进行随机访问;通过map-reduce脱机或批访问。
本文讲述了HBase的特征和它的优点,并简要回顾了行键设计的重点之处,它还向你展示了如何在本地配置HBase环境,使用命令创建表、插入数据、检索指定行以及最后如何进行scan操作
总结
以上所述是小编给大家介绍的hbase的优点,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
shell 命令行中操作HBase数据库实例详解
shell 命令行中操作HBase数据库 Shell控制 进入到shell命令行界面,执行hbase命令,并附加shell关键字: [grid@hdnode3 ~]$ hbase shell HBase Shell; enter ¨help¨ for list of supported commands. Type "exit" to leave the HBase Shell Version 0.90.5, r1212209, Fri Dec 9 05:40:36 UTC 2011
-
基于HBase Thrift接口的一些使用问题及相关注意事项的详解
HBase对于非Java语言提供了Thrift接口支持,这里结合对HBase Thrift接口(HBase版本为0.92.1)的使用经验,总结其中遇到的一些问题及其相关注意事项.1. 字节的存放顺序HBase中,由于row(row key和column family.column qualifier.time stamp)是按照字典序进行排序的,因此,对于short.int.long等类型的数据,通过Bytes.toBytes(-)转换成byte数组后,必须按照大端模式(高字节在低地址,低字节在
-
hbase shell基础和常用命令详解
HBase是Google Bigtable的开源实现,它利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务. 1. 简介 HBase是一个分布式的.面向列的开源数据库,源于google的一篇论文<bigtable:一个结构化数据的分布式存储系统>.HBase是Google Bigtable的开源实现,它利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase
-

Asp.Net Couchbase Memcached图文安装调用开发
安装服务端 服务端下载地址:http://www.couchbase.com/download 选择适合自己的进行下载安装就可以了,我这里选择的是Win7 64. 在安装服务端如果发生如下所示的错误,我在win7 64安装的过程中就遇到了. 这个时候可以先撤销安装.通过CMD命令运行regedit.展开HKEY_LOCAL_MACHINE\Software\Microsoft\ Windows\ CurrentVersion分支,在窗口的右侧区域找到名为"ProgramFilesDir"
-
python操作 hbase 数据的方法
配置 thrift python使用的包 thrift 个人使用的python 编译器是pycharm community edition. 在工程中设置中,找到project interpreter, 在相应的工程下,找到package,然后选择 "+" 添加, 搜索 hbase-thrift (Python client for HBase Thrift interface),然后安装包. 安装服务器端thrift. 参考官网,同时也可以在本机上安装以终端使用. thrift Ge
-
hbase 简介
概述 HBase是一个构建在HDFS上的分布式列存储系统: HBase是基于GoogleBigTable模型开发的,典型的key/value系统: HBase是ApacheHadoop生态系统中的重要一员,主要用于海量结构化数据存储: 从逻辑上讲,HBase将数据按照表.行和列进行存储. 与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力. Hbase表的特点 大:一个表可以有数十亿行,上百万列: 无模式:每行都有一个可排序的主键和任意多的列,
-
详解hbase与hive数据同步
hive的表数据是可以同步到impala中去的.一般impala是提供实时查询操作的,像比较耗时的入库操作我们可以使用hive,然后再将数据同步到impala中.另外,我们也可以在hive中创建一张表同时映射hbase中的表,实现数据同步. 下面,笔者依次进行介绍. 一.impala与hive的数据同步 首先,我们在hive命令行执行showdatabases;可以看到有以下几个数据库: 然后,我们在impala同样执行showdatabases;可以看到: 目前的数据库都是一样的. 下面,我们
-
深入浅析hbase的优点
hbase是运行在Hadoop上的NoSQL数据库,它是一个分布式的和可扩展的大数据仓库,也就是说HBase能够利用HDFS的分布式处理模式,并从Hadoop的MapReduce程序模型中获益.这意味着在一组商业硬件上存储许多具有数十亿行和上百万列的大表.除去Hadoop的优势,HBase本身就是十分强大的数据库,它能够融合key/value存储模式带来实时查询的能力,以及通过MapReduce进行离线处理或者批处理的能力.总的来说,Hbase能够让你在大量的数据中查询记录,也可以从中获得综合分
-
浅析Redis Sentinel 与 Redis Cluster
一.前言 互联网高速发展的今天,对应用系统的抗压能力要求越来越高,传统的应用层+数据库已经不能满足当前的需要.所以一大批内存式数据库和Nosql数据库应运而生,其中redis,memcache,mongodb,hbase等被广泛的使用来提高系统的吞吐性,所以如何正确使用cache是作为开发的一项基技能.本文主要介绍Redis Sentinel 及 Redis Cluster的区别及用法,Redis的基本操作可以自行去参看其官方文档 . 其他几种cache有兴趣的可自行找资料去学习. 二.Redi
-
浅析JSONP技术原理及实现
跨域问题一直是前端中常见的问题,每当说到跨域,第一浮现的技术必然就是JSONP JSONP在我的理解,它并不是ajax,它是在文档中插入一个script标签,创建_callback方法,通过服务器配合执行_callback方法,并传入一些参数 JSONP的局限就在于,因为是通过插入script标签,所以参数只能通过url传入,因此只能满足get请求,特别jQuery的ajax方法时,即使设置type: 'POST',但是只要设置了dataType: 'jsonp',在请求时,都会自动使用GET请
-
浅析JS中的 map, filter, some, every, forEach, for in, for of 用法总结
1.map 有返回值,返回一个新的数组,每个元素为调用func的结果. let list = [1, 2, 3, 4, 5]; let other = list.map((d, i) => { return d * 2; }); console.log(other); // print: [2, 4, 6, 8, 10] 2.filter 有返回值,返回一个符合func条件的元素数组 let list = [1, 2, 3, 4, 5]; let other = list.filter((d,
-
浅析在javascript中创建对象的各种模式
最近在看<javascript高级程序设计>(第二版) javascript中对象的创建 •工厂模式 •构造函数模式 •原型模式 •结合构造函数和原型模式 •原型动态模式 面向对象的语言大都有一个类的概念,通过类可以创建多个具有相同方法和属性的对象.虽然从技术上讲,javascript是一门面向对象的语言,但是javascript没有类的概念,一切都是对象.任意一个对象都是某种引用类型的实例,都是通过已有的引用类型创建:引用类型可以是原生的,也可以是自定义的.原生的引用类型有:Object.A
-
浅析js绑定事件的常用方法
浅析js绑定事件的常用方法 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http:
-
浅析ActiveX控件的CAB压缩
浅析ActiveX控件的CAB压缩 任凤华 摘 要 本文简单介绍了CAB压缩,以及使用WinCAB将ActiveX控件压缩为CAB文件的具体步骤. 关键词 ActiveX控件:CAB压缩:WinCAB:INF文件 1. 引言 ActiveX控件技术是从OLE基础上发展起来的,是将OLE进行了扩展从而使其适应Intern et.Intranet.商业应用程序等的开发.当ActiveX控件的程序代码在Internet上传输时,使用压缩技术传输程序代码变得非常有意义. 从另一方面来看,如果Activ
-
浅析创建javascript对象的方法
一.工厂模式 function person (name,age) { var p=new Object(); p.name=name; p.age=age; p.showMessage=function(){ console.log("name:"+this.name+" age:"+this.age); } return p; } var p1=person("k1",28); var p2=person("k2",29)
-
fragment中的add和replace方法的区别浅析
使用 FragmentTransaction 的时候,它提供了这样两个方法,一个 add , 一个 replace ,对这两个方法的区别一直有点疑惑. 我觉得使用 add 的话,在按返回键应该是回退到上一个 Fragment,而使用 replace 的话,那个别 replace 的就已经不存在了,所以就不会回退了.但事实不是这样子的.add 和 replace 影响的只是界面,而控制回退的,是事务. public abstract FragmentTransaction add (int con
-
深入浅析Spring-boot-starter常用依赖模块
Spring-boot的2大优点: 1.基于Spring框架的"约定优先于配置(COC)"理念以及最佳实践之路. 2.针对日常企业应用研发各种场景的Spring-boot-starter自动配置依赖模块,且"开箱即用"(约定spring-boot-starter- 作为命名前缀,都位于org.springframenwork.boot包或者命名空间下). 应用日志和spring-boot-starter-logging 常见的日志系统大致有:java.util默认提