SQLSERVER收集语句运行的统计信息并进行分析
对于语句的运行,除了执行计划本身,还有一些其他因素要考虑,例如语句的编译时间、执行时间、做了多少次磁盘读等。
如果DBA能够把问题语句单独测试运行,可以在运行前打开下面这三个开关,收集语句运行的统计信息。
这些信息对分析问题很有价值。
代码如下:
SET STATISTICS TIME ON
SET STATISTICS IO ON
SET STATISTICS PROFILE ON
SET STATISTICS TIME ON
--------------------------------------------------------------------------------
请先来看看SET STATISTICS TIME ON会返回什么信息。先运行语句:
代码如下:
DBCC DROPCLEANBUFFERS
--清除buffer pool里的所有缓存数据
DBCC freeproccache
GO
--清除buffer pool里的所有缓存的执行计划
SET STATISTICS TIME ON
GO
USE [AdventureWorks]
GO
SELECT DISTINCT([ProductID]),[UnitPrice] FROM [dbo].[SalesOrderDetail_test]
WHERE [ProductID]=777
GO
SET STATISTICS TIME OFF
GO
除了结果集之外,SQLSERVER还会返回下面这两段信息
代码如下:
SQL Server 分析和编译时间:
CPU 时间 = 15 毫秒,占用时间 = 104 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
(4 行受影响)
SQL Server 执行时间:
CPU 时间 = 171 毫秒,占用时间 = 1903 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
大家知道SQLSERVER执行语句是分以下阶段:分析-》编译-》执行
根据表格的统计信息分析出比较合适的执行计划,然后编译语句,最后执行语句
下面说一下上面的输出是什么意思:
--------------------------------------------------------------------------------
1、CPU时间 :这个值的含义指的是在这一步,SQLSERVER所花的纯CPU时间是多少。也就是说,语句花了多少CPU资源
2、占用时间 :此值指这一步一共用了多少时间。也就是说,这是语句运行的时间长短,有些动作会发生I/O操作,产生了I/O等待,或者是遇到阻塞、产生了阻塞等待。总之时间用掉了,但是没有用CPU资源。所以占用时间比CPU时间长是很正常的 ,但是CPU时间是语句在所有CPU上的时间总和。如果语句使用了多颗CPU,而其他等待几乎没有,那么CPU时间大于占用时间也是正常的
3、分析和编译时间:这一步,就是语句的编译时间。由于语句运行之前清空了所有执行计划,SQLSERVER必须要对他编译。
这里的编译时间就不为0了。由于编译主要是CPU的运算,所以一般CPU时间和占用时间是差不多的。如果这里相差比较大,就有必要看看SQLSERVER在系统资源上有没有瓶颈了。
这里他们是一个15毫秒,一个是104毫秒
4、SQLSERVER执行时间: 语句真正运行的时间。由于语句是第一次运行,SQLSERVER需要把数据从磁盘读到内存里,这里语句的运行发生了比较长的I/O等待。所以这里的CPU时间和占用时间差别就很大了,一个是171毫秒,而另一个是1903毫秒
总的来讲,这条语句花了104+1903+186=2193毫秒,其中CPU时间为15+171=186毫秒。语句的主要时间应该是都花在了I/O等待上
SET STATISTICS TIME ON
GO
SELECT DISTINCT([ProductID]),[UnitPrice] FROM [dbo].[SalesOrderDetail_test]
WHERE [ProductID]=777
GO
SET STATISTICS TIME OFF
GO
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
(4 行受影响)
SQL Server 执行时间:
CPU 时间 = 156 毫秒,占用时间 = 169 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
由于执行计划被重用,“SQL分析和编译时间” CPU时间是0,占用时间是0
由于数据已经缓存在内存里,不需要从磁盘上读取,SQL执行时间 CPU时间是156,占用时间这次和CPU时间非常接近,是169。
这里省下运行时间1903-169=1734毫秒,从这里可以再次看出,缓存对语句执行性能起着至关重要的作用
为了不影响其他测试,请运行下面的语句关闭SET STATISTICS TIME ON
代码如下:
SET STATISTICS TIME OFF
GO
SET STATISTICS IO ON
--------------------------------------------------------------------------------
这个开关能够输出语句做的物理读和逻辑读的数目。对分析语句的复杂度有很重要的作用
还是以刚才那个查询作为例子
代码如下:
DBCC DROPCLEANBUFFERS
GO
SET STATISTICS IO ON
GO
SELECT DISTINCT([ProductID]),[UnitPrice] FROM [dbo].[SalesOrderDetail_test]
WHERE [ProductID]=777
GO
他的返回是:
(4 行受影响)
表 'SalesOrderDetail_test'。扫描计数 5,逻辑读取 15064 次,物理读取 0 次,预读 15064 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
各个输出的含义是:
--------------------------------------------------------------------------------
表:表的名称。这里的表就是SalesOrderDetail_test
扫描计数:执行的扫描次数。按照执行计划,表格被扫描了几次。一般来讲大表扫描的次数越多越不好。唯一的例外是如果执行计划选择了并发运行, 由多个thread线程同时做一个表的读取,每个thread读其中的一部分,但是这里会显示所有thread的数目。也就是有几个thread在并发做, 就会有几个扫描。这时数目大一点没问题的。
逻辑读取:从数据缓存读取的页数。页数越多,说明查询要访问的数据量就越大,内存消耗量越大,查询也就越昂贵。
可以检查是否应该调整索引,减少扫描的次数,缩小扫描范围
物理读取:从磁盘读取的页数
预读:为进行查询而预读入缓存的页数
物理读取+预读:就是SQLSERVER为了完成这句查询而从磁盘上读取的页数。如果不为0,说明数据没有缓存在内存里。运行速度一定会受到影响
LOB逻辑读取:从数据缓存读取的text、ntext、image、大值类型(varchar(max)、nvarchar(max)、varbinary(max))页的数目
LOB物理读取:从磁盘读取的text、ntext、image、大值类型页的数目
LOB预读:为进行查询而放入缓存的text、ntext、image、大值类型页的数目
然后再来运行一遍,不清空缓存
代码如下:
SET STATISTICS IO ON
GO
SELECT DISTINCT([ProductID]),[UnitPrice] FROM [dbo].[SalesOrderDetail_test]
WHERE [ProductID]=777
GO
1 表 'SalesOrderDetail_test'。扫描计数 5,逻辑读取 15064 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,
2 lob 物理读取 0 次,lob 预读 0 次。
这次逻辑读取不变,还是15064页。但是物理读取和预读都是0了。说明数据已经缓存在内存里第二次运行不需要再从磁盘上读一遍,节省了时间为了不影响其他测试,请运行下面语句关闭SET STATISTICS IO ON
代码如下:
SET STATISTICS IO OFF
GO
SET STATISTICS PROFILE ON
--------------------------------------------------------------------------------
这是三个设置中返回最复杂的一个,他返回语句的执行计划,以及语句运行在每一步的实际返回行数统计。
通过这个结果,不仅可以得到执行计划,理解语句执行过程,分析语句调优方向,也可以判断SQLSERVER是否
选择了一个正确的执行计划。
代码如下:
SET STATISTICS PROFILE ON
GO
SELECT COUNT(b.[SalesOrderID])
FROM [dbo].[SalesOrderHeader_test] a
INNER JOIN [dbo].[SalesOrderDetail_test] b
ON a.[SalesOrderID]=b.[SalesOrderID]
WHERE a.[SalesOrderID]>43659 AND a.[SalesOrderID]<53660
GO
返回的结果集很长,下面说一下重要字段
--------------------------------------------------------------------------------
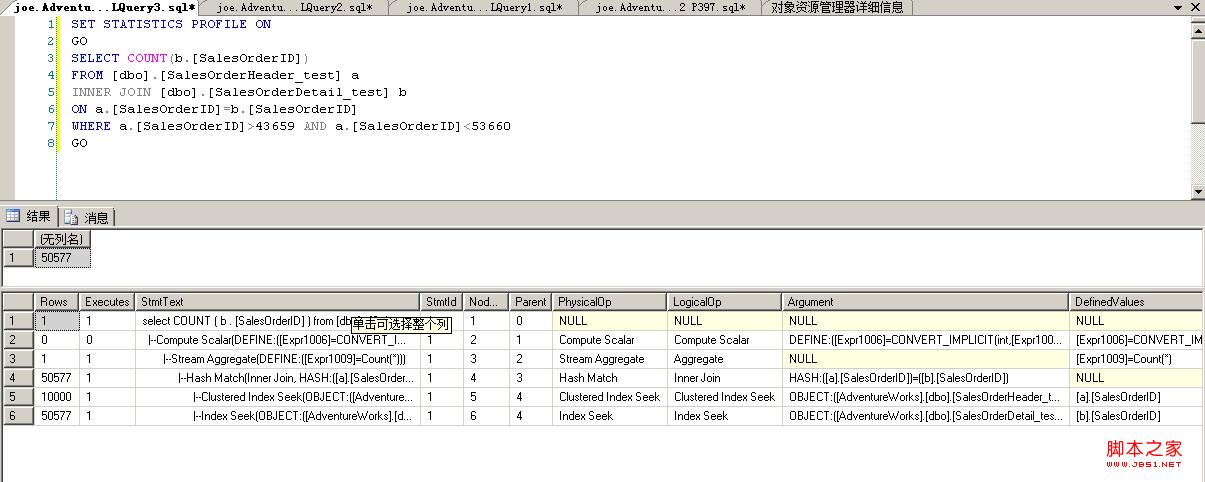
注意:这里是从最下面开始向上看的,也就是说从最下面开始一直执行直到得到结果集所以(行1)里的rows字段显示的值就是这个查询返回的结果集。
而且有多少行表明SQLSERVER执行了多少个步骤,这里有6行,表明SQLSRVER执行了6个步骤!!
Rows:执行计划的每一步返回的实际行数
Executes:执行计划的每一步被运行了多少次
StmtText:执行计划的具体内容。执行计划以一棵树的形式显示。每一行都是运行的一步,都会有结果集返回,也都会有自己的cost
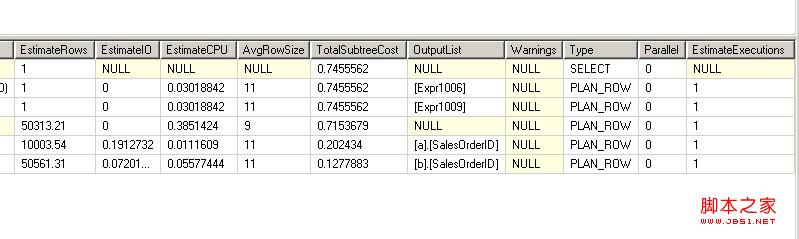
EstimateRows:SQLSERVER根据表格上的统计信息,预估的每一步的返回行数。在分析执行计划时,我们会经常将Rows和EstimateRows这两列做对比,先确认SQLSERVER预估得是否正确,以判断统计信息是否有更新
EstimateIO:SQLSERVER根据EstimateRows和统计信息里记录的字段长度,预估的每一步会产生的I/O cost
EstimateCPU:SQLSERVR根据EstimateRows和统计信息里记录的字段长度,以及要做的事情的复杂度,预估每一步会产生的CPU cost
TotalSubtreeCost:SQLSERVER根据EstimateIO和EstimateCPU通过某种计算公式,计算出每一步执行计划子树的cost (包括这一步自己的cost和他的所有下层步骤的cost总和),下面介绍的cost说的都是这个字段值
Warnings:SQLSERVER在运行每一步时遇到的警告,例如,某一步没有统计信息支持cost预估等。
Parallel:执行计划的这一步是不是使用了并行的执行计划
从上面结果可以看出执行计划分成4步,其中第一步又分成并列的两个子步骤
步骤a1(第5行):从[SalesOrderHeader_test]表里找出所有a.[SalesOrderID]>43659 AND a.[SalesOrderID]<53660的值
因为表在这个字段上有一个聚集索引,所以SQL可以直接使用这个索引的seek
SQL预测返回10000条记录,实际也就返回了10000条记录.。这个预测是准确的。这一步的cost是0.202(totalsubtreecost)
步骤a2(第6行):从[SalesOrderDetail_test]表里找出所有 a.[SalesOrderID]>43659 AND a.[SalesOrderID]<53660的值
因为表在这个字段上有一个非聚集索引,所以SQL可以直接使用这个索引的seek 这里能够看出SQL聪明的地方。虽然查询语句只定义了[SalesOrderHeader_test]表上有a.[SalesOrderID]>43659 AND a.[SalesOrderID]<53660过滤条件,但是根据语义分析,SQL知道这个条件在[SalesOrderDetail_test]上也为真。所以SQL选择先把这个条件过滤然后再做join。这样能够大大降低join的cost
在这一步SQL预估返回50561条记录,实际返回50577条。cost是0.127,也不高
步骤b(第4行):将a1和a2两步得到的结果集做一个join。因为SQL通过预估知道这两个结果集比较大,所以他直接选择了Hash Match的join方法。
SQL预估这个join能返回50313行,实际返回50577行。因为SQL在两张表的[SalesOrderID]上都有统计信息,所以这里的预估非常准确
这一步的cost等于totalsubtreecost减去他的子步骤,0.715-0.202-0.127=0.386。由于预估值非常准确,可以相信这里的cost就是实际每一步的cost
步骤c(第3行):在join返回的结果集基础上算count(*)的值这一步比较简单,count(*)的结果总是1,所以预测值是正确的。
其实这一步的cost是根据上一步(b)join返回的结果集大小预估出来的。我们知道步骤b的预估返回值非常准确,所以这一步的预估cost也不会有什么大问题
这棵子树的cost是0.745,减去他的子节点cost,他自己的cost是0.745-0.715=0.03。是花费很小的一步
步骤b(第2行):将步骤c返回的值转换为int类型,作为结果返回
这一步是上一步的继续,更为简单。convert一个值的数据类型所要的cost几乎可以忽略不计。所以这棵子树的cost和他的子节点相等,都是0.745。
也就是说,他自己的cost是0
通过这样的方法,用户可以了解到语句的执行计划、SQLSERVER预估的准确性、cost的分布
最后说一下:不同SQLSERVER版本,不同机器cost可能会不一样,例如SQL2005 ,SQL2008
相关推荐
-
sqlserver 统计sql语句大全收藏
1.计算每个人的总成绩并排名 select name,sum(score) as allscore from stuscore group by name order by allscore 2.计算每个人的总成绩并排名 select distinct t1.name,t1.stuid,t2.allscore from stuscore t1,( select stuid,sum(score) as allscore from stuscore group by stuid)t2where t1
-

SQLServer2005 中的几个统计技巧
在SQLServer中我们可以用over子句中来代替子查询实现来提高效率,over子句除了排名函数之外也可以和聚合函数配合.实现代码如下: 复制代码 代码如下: use tempdb go if (object_id ('tb' ) is not null ) drop table tb go create table tb (name varchar (10 ), val int ) go insert into tb select 'aa' , 10 union all select 'a
-
SQLSERVER语句的执行时间显示的统计结果是什么意思
在SQL语句调优的时候,大部分都会查看语句执行时间,究竟SQLSERVER显示出来的统计结果是什么意思? 下面看一下例子 比较简单的语句: 复制代码 代码如下: 1 SET STATISTICS TIME ON 2 USE [pratice] 3 GO 4 SELECT * FROM [dbo].[Orders] 结果: 复制代码 代码如下: SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒. SQL Server 执行时间: CPU 时间 = 0 毫秒
-
SQLserver 实现分组统计查询(按月、小时分组)
设置AccessCount字段可以根据需求在特定的时间范围内如果是相同IP访问就在AccessCount上累加. 复制代码 代码如下: Create table Counter ( CounterID int identity(1,1) not null, IP varchar(20), AccessDateTime datetime, AccessCount int ) 该表在这儿只是演示使用,所以只提供了最基本的字段 现在往表中插入几条记录 insert into Counter selec
-
如何统计全天各个时间段产品销量情况(sqlserver)
数据库环境:SQL SERVER 2005 现有一个产品销售实时表,表数据如下: 字段name是产品名称,字段type是销售类型,1表示售出,2表示退货,字段num是数量,字段ctime是操作时间. 要求: 在一行中统计24小时内所有货物的销售(售出,退货)数据,把日期考虑在内. 分析: 这实际上是行转列的一个应用,在进行行转列之前,需要补全24小时的所有数据.补全数据可以通过系统的数字辅助表 spt_values来实现,进行行转列时,根据type和处理后的ctime分组即可. 1.建表,导入数
-
SQLSERVER收集语句运行的统计信息并进行分析
对于语句的运行,除了执行计划本身,还有一些其他因素要考虑,例如语句的编译时间.执行时间.做了多少次磁盘读等. 如果DBA能够把问题语句单独测试运行,可以在运行前打开下面这三个开关,收集语句运行的统计信息. 这些信息对分析问题很有价值. 复制代码 代码如下: SET STATISTICS TIME ON SET STATISTICS IO ON SET STATISTICS PROFILE ON SET STATISTICS TIME ON ----------------------------
-
SQLServer中使用扩展事件获取Session级别的等待信息及SQLServer 2016中Session级别等待信息的增强
什么是等待 简单说明一下什么是等待: 当应用程序对SQL Server发起一个Session请求的时候,这个Session请求在数据库中执行的过程中会申请其所需要的资源, 比如可能会申请内存资源,表上的锁资源,物理IO资源,网络资源等等, 如果当前Session运行过程中需要申请的某些资源无法立即得到满足,就会产生等待. SQL Server会以不用的方式来展现这个等待信息,比活动Session的等待信息,实例级的等待信息等等. SQL Server中,等待事件是作为DBA进行TroubleSh
-
Oracle统计信息的导出导入测试示例详解
背景: 有时我们会希望可以对Oracle的统计信息整体进行导出导入.比如在数据库迁移前后,希望统计信息保持不变;又比如想对统计信息重新进行收集,但是担心重新收集的结果反而引发性能问题,想先保存当前的统计信息,这样即使重新收集后效果不好还可以导入之前的统计信息. Oracle提供给我们一些方法,比较常用的粒度有两种: schema级别统计信息的导出导入 通过调用DBMS_STATS.EXPORT_SCHEMA_STATS和DBMS_STATS.IMPORT_SCHEMA_STATS来进行. dat
-
Oracle 11g收集多列统计信息详解
前言 通常,当我们将SQL语句提交给Oracle数据库时,Oracle会选择一种最优方式来执行,这是通过查询优化器Query Optimizer来实现的.CBO(Cost-Based Optimizer)是Oracle默认使用的查询优化器模式.在CBO中,SQL执行计划的生成,是以一种寻找成本(Cost)最优为目标导向的执行计划探索过程.所谓成本(Cost)就是将CPU和IO消耗整合起来的量化指标,每一个执行计划的成本就是经过优化器内部公式估算出的数字值. 我们在写SQL语句的时候,经常会碰到w
-
SQL Server统计信息更新时采样百分比对数据预估准确性的影响详解
为什么要写统计信息 最近看到园子里有人写统计信息,楼主也来凑热闹. 话说经常做数据库的,尤其是做开发的或者优化的,统计信息造成的性能问题应该说是司空见惯. 当然解决办法也并非一成不变,"一招鲜吃遍天"的做法已经行不通了(题外话:整个时代不都是这样子吗) 当然,还是那句话,既然写了就不能太俗套,写点不一样的,本文通过分析一个类似实际案例来解读统计信息的更新的相关问题. 对于实际问题,不但要解决问题,更重要的是要从理论上深入分析,才能更好地驾驭数据库. 何时更新统计信息 (1)查询执行缓慢
-
详解mysql持久化统计信息
一.持久化统计信息的意义: 统计信息用于指导mysql生成执行计划,执行计划的准确与否直接影响到SQL的执行效率:如果mysql一重启 之前的统计信息就没有了,那么当SQL语句来临时,那么mysql就要收集统计信息然后再生成SQL语句的执行 计划.如果能在关闭mysql的时候就把统计信息保存起来,那么在启动时就不要再收集一次了,这种处理方式 有助于效率的提升. 二.统计信息准确与否也同样重要: 第一目中我们说明了"持久化统计信息的意义",我们的假设统计信息是有用的,是准确的:如果统计信
-
Oracle 12c新特性之如何检测有用的多列统计信息详解
前言 之前和大家分享过Oracle 11g下的一个新特性--收集多列统计信息(http://www.jb51.net/article/109514.htm),今天和大家分享Oracle 12c的一个新特性--自动检测有用列组信息.二者相得益彰,大家可以具体情况酌情使用. 言归正传,我们可以针对一个表,基于特定的工作负荷,通过使用DBMS_STATS.SEED_COL_USAGE和REPORT_COL_USAGE来确定我们需要哪些列组.当你不清除需要创建哪个扩展统计信息时,这个技术是非常有用的.需
-
自增长键列统计信息的处理方法
这篇文章通过文字代码的形式讲解了如何处理用自增长键列的统计信息.我们都知道,在SQL Server里每个统计信息对象都有关联的直方图.直方图用多个步长描述指定列数据分布情况.在一个直方图里,SQL Server最大支持200的步长,但当你查询的数据范围在直方图最后步长后,这是个问题.我们来看下面的代码,重现这个情形: -- Create a simple orders table CREATE TABLE Orders ( OrderDate DATE NOT NULL, Col2 INT NO
-
C# 基于udp广播收集局域网类所有设备信息
一个简单好理解的例子,复制过去就能用,能看到效果 首先对功能的思考,他怎么去实现 1.制定udp广播的端口(如果收发用同一个端口就会一直接收到自己给自己广播的消息) 2.启动后向局域网广播约定的字符串(字符串包含了广播端的IP和用来接收响应的端口号) 3.设备需要内置一个功能,打开约定的接收广播端口,持续做好对udp服务端的响应工作,接收广播字符串后解析,向广播端发送自己的IP和自己设备的型号信息(送至:解析到的IP,端口号) 4.广播端接收这个设备发送的字符串,解析生成模型,放进动态的list
-
oracle自动统计信息时间的修改过程记录
今天是2022年1月7日今天值夜班,同事让给优化一个sql,优化完成后,顺便看了下新系统的统计信息情况,发现在晚上做数据采集的时间,系统资源增加,发现是统计信息在跑,在模拟环境测试,特此记录. - trc get trace path - undo show undo info - user | users list all users info - version show database version - xo <sql_id> [phv] xplan.display_awr for