Python实现决策树并且使用Graphvize可视化的例子
一、什么是决策树(decision tree)——机器学习中的一个重要的分类算法
决策树是一个类似于数据流程图的树结构:其中,每个内部节点表示一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或者类的分布,树的最顶层是根结点
根据天气情况决定出游与否的案例
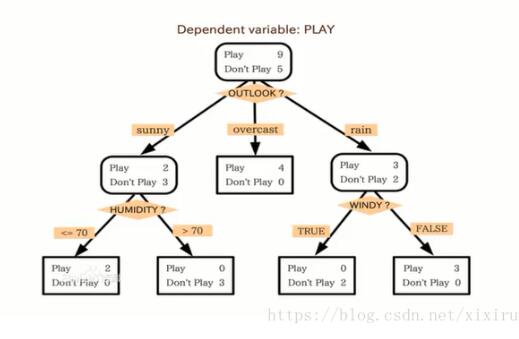
二、决策树算法构建
2.1决策树的核心思路
特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法)。
决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集不可分则停止决策树停止声场。
剪枝:决策树容易过拟合,需要剪枝来缩小树的结构和规模(包括预剪枝和后剪枝)。
2.2 熵的概念:度量信息的方式
实现决策树的算法包括ID3、C4.5算法等。常见的ID3核心思想是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常不确定的事情,或者是我们一无所知的事情,需要大量的信息====>信息量的度量就等于不确定性的 多少。也就是说变量的不确定性越大,熵就越大
信息熵的计算公司
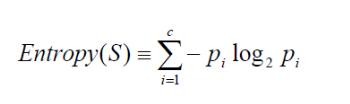
S为所有事件集合,p为发生概率,c为特征总数。
信息增益(information gain)是指信息划分前后的熵的变化,也就是说由于使用这个属性分割样例而导致的期望熵降低。也就是说,信息增益就是原有信息熵与属性划分后信息熵(需要对划分后的信息熵取期望值)的差值,具体计算如下:
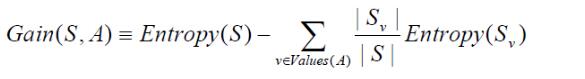
其中,第二项为属性A对S划分的期望信息。
三、IDE3决策树的Python实现
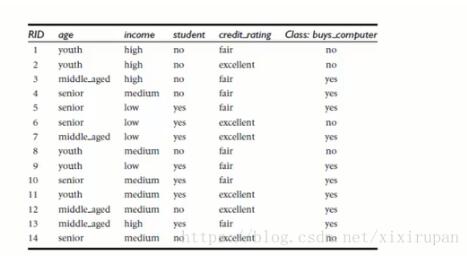
以下面这个不同年龄段的人买电脑的情况为例子建模型算法
'''
Created on 2018年7月5日
使用python内的科学计算的库实现利用决策树解决问题
@author: lenovo
'''
#coding:utf-8
from sklearn.feature_extraction import DictVectorizer
#数据存储的格式 python自带不需要安装
import csv
#预处理的包
from sklearn import preprocessing
from sklearn.externals.six import StringIO
from sklearn.tree import tree
from sklearn.tree import export_graphviz
'''
文件保存格式需要是utf-8
window中的目录形式需要是左斜杠 F:/AA_BigData/test_data/test1.csv
excel表格存储成csv格式并且是utf-8格式的编码
'''
'''
决策树数据源读取
scklearn要求的数据类型 特征值属性必须是数值型的
需要对数据进行预处理
'''
#装特征的值
featureList=[]
#装类别的词
labelList=[]
with open("F:/AA_BigData/test_data/decision_tree.csv", "r",encoding="utf-8") as csvfile:
decision =csv.reader(csvfile)
headers =[]
row =1
for item in decision:
if row==1:
row=row+1
for head in item:
headers.append(head)
else:
itemDict={}
labelList.append(item[len(item)-1])
for num in range(1,len(item)-1):
# print(item[num])
itemDict[headers[num]]=item[num]
featureList.append(itemDict)
print(headers)
print(labelList)
print(featureList)
'''
将原始数据转换成包含有字典的List
将建好的包含字典的list用DictVectorizer对象转换成0-1矩阵
'''
vec =DictVectorizer()
dumyX =vec.fit_transform(featureList).toarray();
#对于类别使用同样的方法
lb =preprocessing.LabelBinarizer()
dumyY=lb.fit_transform(labelList)
print(dumyY)
'''
1.构建分类器——决策树模型
2.使用数据训练决策树模型
'''
clf =tree.DecisionTreeClassifier(criterion="entropy")
clf.fit(dumyX,dumyY)
print(str(clf))
'''
1.将生成的分类器转换成dot格式的 数据
2.在命令行中dot -Tpdf iris.dot -o output.pdf将dot文件转换成pdf图的文件
'''
#视频上讲的不适用python3.5
with open("F:/AA_BigData/test_data/decisiontree.dot", "w") as wFile:
export_graphviz(clf,out_file=wFile,feature_names=vec.get_feature_names())
Graphvize对决策树的可视化

以上这篇Python实现决策树并且使用Graphvize可视化的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python实现ID3决策树算法
ID3决策树是以信息增益作为决策标准的一种贪心决策树算法 # -*- coding: utf-8 -*- from numpy import * import math import copy import cPickle as pickle class ID3DTree(object): def __init__(self): # 构造方法 self.tree = {} # 生成树 self.dataSet = [] # 数据集 self.labels = [] # 标签集 # 数据导入函数
-

Python实现决策树C4.5算法的示例
为什么要改进成C4.5算法 原理 C4.5算法是在ID3算法上的一种改进,它与ID3算法最大的区别就是特征选择上有所不同,一个是基于信息增益比,一个是基于信息增益. 之所以这样做是因为信息增益倾向于选择取值比较多的特征(特征越多,条件熵(特征划分后的类别变量的熵)越小,信息增益就越大):因此在信息增益下面加一个分母,该分母是当前所选特征的熵,注意:这里而不是类别变量的熵了. 这样就构成了新的特征选择准则,叫做信息增益比.为什么加了这样一个分母就会消除ID3算法倾向于选择取值较多的特征呢? 因为特
-
Python3.0 实现决策树算法的流程
决策树的一般流程 检测数据集中的每个子项是否属于同一个分类 if so return 类标签 Else 寻找划分数据集的最好特征 划分数据集 创建分支 节点 from math import log import operator #生成样本数据集 def createDataSet(): dataSet = [[1,1,'yes'], [1,1,'yes'], [1,0,'no'], [0,1,'no'], [0,1,'no']] labels = ['no surfacing','flipp
-
基于Python实现的ID3决策树功能示例
本文实例讲述了基于Python实现的ID3决策树功能.分享给大家供大家参考,具体如下: ID3算法是决策树的一种,它是基于奥卡姆剃刀原理的,即用尽量用较少的东西做更多的事.ID3算法,即Iterative Dichotomiser 3,迭代二叉树3代,是Ross Quinlan发明的一种决策树算法,这个算法的基础就是上面提到的奥卡姆剃刀原理,越是小型的决策树越优于大的决策树,尽管如此,也不总是生成最小的树型结构,而是一个启发式算法. 如下示例是一个判断海洋生物数据是否是鱼类而构建的基于ID3思想
-
解读python如何实现决策树算法
数据描述 每条数据项储存在列表中,最后一列储存结果 多条数据项形成数据集 data=[[d1,d2,d3...dn,result], [d1,d2,d3...dn,result], . . [d1,d2,d3...dn,result]] 决策树数据结构 class DecisionNode: '''决策树节点 ''' def __init__(self,col=-1,value=None,results=None,tb=None,fb=None): '''初始化决策树节点 args: col -
-
python实现决策树ID3算法的示例代码
在周志华的西瓜书和李航的统计机器学习中对决策树ID3算法都有很详细的解释,如何实现呢?核心点有如下几个步骤 step1:计算香农熵 from math import log import operator # 计算香农熵 def calculate_entropy(data): label_counts = {} for feature_data in data: laber = feature_data[-1] # 最后一行是laber if laber not in label_counts
-
Python决策树分类算法学习
从这一章开始进入正式的算法学习. 首先我们学习经典而有效的分类算法:决策树分类算法. 1.决策树算法 决策树用树形结构对样本的属性进行分类,是最直观的分类算法,而且也可以用于回归.不过对于一些特殊的逻辑分类会有困难.典型的如异或(XOR)逻辑,决策树并不擅长解决此类问题. 决策树的构建不是唯一的,遗憾的是最优决策树的构建属于NP问题.因此如何构建一棵好的决策树是研究的重点. J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3算法.后续的C4.5,
-
python实现C4.5决策树算法
C4.5算法使用信息增益率来代替ID3的信息增益进行特征的选择,克服了信息增益选择特征时偏向于特征值个数较多的不足.信息增益率的定义如下: # -*- coding: utf-8 -*- from numpy import * import math import copy import cPickle as pickle class C45DTree(object): def __init__(self): # 构造方法 self.tree = {} # 生成树 self.dataSet =
-
Python实现决策树并且使用Graphvize可视化的例子
一.什么是决策树(decision tree)--机器学习中的一个重要的分类算法 决策树是一个类似于数据流程图的树结构:其中,每个内部节点表示一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或者类的分布,树的最顶层是根结点 根据天气情况决定出游与否的案例 二.决策树算法构建 2.1决策树的核心思路 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法). 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集
-
Python实现决策树并且使用Graphviz可视化的例子
一.什么是决策树(decision tree)--机器学习中的一个重要的分类算法 决策树是一个类似于数据流程图的树结构:其中,每个内部节点表示一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或者类的分布,树的最顶层是根结点 根据天气情况决定出游与否的案例 二.决策树算法构建 2.1决策树的核心思路 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不同产生了不同的特征决策树算法). 决策树生成:根据所选特征评估标准,从上至下递归地生成子节点,直到数据集
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
python实现决策树
本文实例为大家分享了python实现决策树的具体代码,供大家参考,具体内容如下 算法优缺点: 优点:计算复杂度不高,输出结果易于理解,对中间值缺失不敏感,可以处理不相关的特征数据 缺点:可能会产生过度匹配的问题 适用数据类型:数值型和标称型 算法思想: 1.决策树构造的整体思想: 决策树说白了就好像是if-else结构一样,它的结果就是你要生成这个一个可以从根开始不断判断选择到叶子节点的树,但是呢这里的if-else必然不会是让我们认为去设置的,我们要做的是提供一种方法,计算机可以根据这种方法得
-
python输出决策树图形的例子
windows10: 1,先要pip安装pydotplus和graphviz: pip install pydotplus pip install graphviz 2,www.graphviz.org下载msi文件并安装. 3,系统环境变量path中增加两项: C:\Program Files (x86)\Graphviz2.38\bin C:\Program Files (x86)\Graphviz2.38 #确认graphviz是安装在上面路径当中. 4,python中使用方法: from
-
python实现决策树分类算法
本文实例为大家分享了python实现决策树分类算法的具体代码,供大家参考,具体内容如下 1.概述 决策树(decision tree)--是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用. 2.算法思想 通俗来说,决策树分类的思想类似于找对象.现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26. 女儿:长的帅不帅? 母亲:挺帅的. 女儿:收入高不?
-
python代码实现TSNE降维数据可视化教程
TSNE降维 降维就是用2维或3维表示多维数据(彼此具有相关性的多个特征数据)的技术,利用降维算法,可以显式地表现数据.(t-SNE)t分布随机邻域嵌入 是一种用于探索高维数据的非线性降维算法.它将多维数据映射到适合于人类观察的两个或多个维度. python代码 km.py #k_mean算法 import pandas as pd import csv import pandas as pd import numpy as np #参数初始化 inputfile = 'x.xlsx' #销量及
-
如何使用Python处理HDF格式数据及可视化问题
原文链接:https://blog.csdn.net/Fairy_Nan/article/details/105914203 HDF也是一种自描述格式文件,主要用于存储和分发科学数据.气象领域中卫星数据经常使用此格式,比如MODIS,OMI,LIS/OTD等卫星产品.对HDF格式细节感兴趣的可以Google了解一下. 这一次呢还是以Python为主,来介绍如何处理HDF格式数据.Python中有不少库都可以用来处理HDF格式数据,比如h5py可以处理HDF5格式(pandas中 read_hdf
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
Python绘制K线图之可视化神器pyecharts的使用
K线图 概念 股市及期货市bai场中的K线图的du画法包含四个zhi数据,即开盘dao价.最高价.最低价zhuan.收盘价,所有的shuk线都是围绕这四个数据展开,反映大势的状况和价格信息.如果把每日的K线图放在一张纸上,就能得到日K线图,同样也可画出周K线图.月K线图.研究金融的小伙伴肯定比较熟悉这个,那么我们看起来比较复杂的K线图,又是这样画出来的,本文我们将一起探索K线图的魅力与神奇之处吧! K线图 用处 K线图用处于股票分析,作为数据分析,以后的进入大数据肯定是一个趋势和热潮,K线图的专