SPFA 算法实例讲解
适用范围:给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了。 我们约定有向加权图G不存在负权回路,即最短路径一定存在。当然,我们可以在执行该算法前做一次拓扑排序,以判断是否存在负权回路,但这不是我们讨论的重 点。
算法思想:我们用数组d记录每个结点的最短路径估计值,用邻接表来存储图G。我们采取的方法是动态逼近法:设立一个先进先出的队列用来保存待优化的 结点,优化时每次取出队首结点u,并且用u点当前的最短路径估计值对离开u点所指向的结点v进行松弛操作,如果v点的最短路径估计值有所调整,且v点不在 当前的队列中,就将v点放入队尾。这样不断从队列中取出结点来进行松弛操作,直至队列空为止
期望的时间复杂度O(ke), 其中k为所有顶点进队的平均次数,可以证明k一般小于等于2。
实现方法:
建立一个队列,初始时队列里只有起始点,再建立一个表格记录起始点到所有点的最短路径(该表格的初始值要赋为极大值,该点到他本身的路径赋为 0)。然后执行松弛操作,用队列里有的点作为起始点去刷新到所有点的最短路,如果刷新成功且被刷新点不在队列中则把该点加入到队列最后。重复执行直到队列 为空。
判断有无负环:
如果某个点进入队列的次数超过N次则存在负环(SPFA无法处理带负环的图)
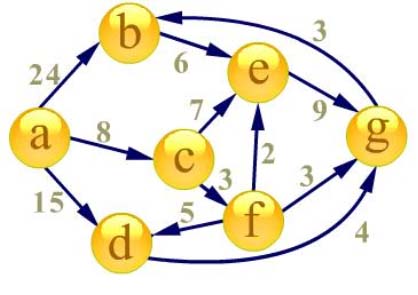
首先建立起始点a到其余各点的
最短路径表格
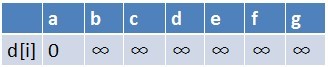
首先源点a入队,当队列非空时:
1、队首元素(a)出队,对以a为起始点的所有边的终点依次进行松弛操作(此处有b,c,d三个点),此时路径表格状态为:
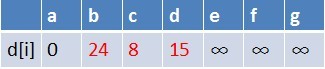
在松弛时三个点的最短路径估值变小了,而这些点队列中都没有出现,这些点
需要入队,此时,队列中新入队了三个结点b,c,d
队首元素b点出队,对以b为起始点的所有边的终点依次进行松弛操作(此处只有e点),此时路径表格状态为:
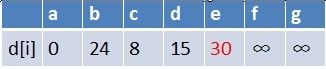
在最短路径表中,e的最短路径估值也变小了,e在队列中不存在,因此e也要
入队,此时队列中的元素为c,d,e
队首元素c点出队,对以c为起始点的所有边的终点依次进行松弛操作(此处有e,f两个点),此时路径表格状态为:
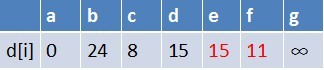
在最短路径表中,e,f的最短路径估值变小了,e在队列中存在,f不存在。因此
e不用入队了,f要入队,此时队列中的元素为d,e,f
队首元素d点出队,对以d为起始点的所有边的终点依次进行松弛操作(此处只有g这个点),此时路径表格状态为:
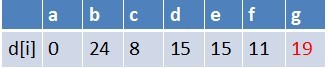
在最短路径表中,g的最短路径估值没有变小(松弛不成功),没有新结点入队,队列中元素为f,g
队首元素f点出队,对以f为起始点的所有边的终点依次进行松弛操作(此处有d,e,g三个点),此时路径表格状态为:
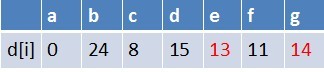
在最短路径表中,e,g的最短路径估值又变小,队列中无e点,e入队,队列中存在g这个点,g不用入队,此时队列中元素为g,e
队首元素g点出队,对以g为起始点的所有边的终点依次进行松弛操作(此处只有b点),此时路径表格状态为:
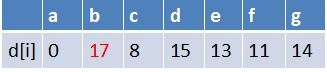
在最短路径表中,b的最短路径估值又变小,队列中无b点,b入队,此时队列中元素为e,b
队首元素e点出队,对以e为起始点的所有边的终点依次进行松弛操作(此处只有g这个点),此时路径表格状态为:
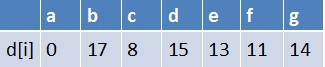
在最短路径表中,g的最短路径估值没变化(松弛不成功),此时队列中元素为b
队首元素b点出队,对以b为起始点的所有边的终点依次进行松弛操作(此处只有e这个点),此时路径表格状态为:
在最短路径表中,e的最短路径估值没变化(松弛不成功),此时队列为空了
最终a到g的最短路径为14
java代码
package spfa负权路径;
import java.awt.List;
import java.util.ArrayList;
import java.util.Scanner;
public class SPFA {
/**
* @param args
*/
public long[] result; //用于得到第s个顶点到其它顶点之间的最短距离
//数组实现邻接表存储
class edge{
public int a;//边的起点
public int b;//边的终点
public int value;//边的值
public edge(int a,int b,int value){
this.a=a;
this.b=b;
this.value=value;
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
SPFA spafa=new SPFA();
Scanner scan=new Scanner(System.in);
int n=scan.nextInt();
int s=scan.nextInt();
int p=scan.nextInt();
edge[] A=new edge[p];
for(int i=0;i<p;i++){
int a=scan.nextInt();
int b=scan.nextInt();
int value=scan.nextInt();
A[i]=spafa.new edge(a,b,value);
}
if(spafa.getShortestPaths(n,s,A)){
for(int i=0;i<spafa.result.length;i++){
System.out.println(spafa.result[i]+" ");
}
}else{
System.out.println("存在负环");
}
}
/*
* 参数n:给定图的顶点个数
* 参数s:求取第s个顶点到其它所有顶点之间的最短距离
* 参数edge:给定图的具体边
* 函数功能:如果给定图不含负权回路,则可以得到最终结果,如果含有负权回路,则不能得到最终结果
*/
private boolean getShortestPaths(int n, int s, edge[] A) {
// TODO Auto-generated method stub
ArrayList<Integer> list = new ArrayList<Integer>();
result=new long[n];
boolean used[]=new boolean[n];
int num[]=new int[n];
for(int i=0;i<n;i++){
result[i]=Integer.MAX_VALUE;
used[i]=false;
}
result[s]=0;//第s个顶点到自身距离为0
used[s]=true;//表示第s个顶点进入数组队
num[s]=1;//表示第s个顶点已被遍历一次
list.add(s); //第s个顶点入队
while(list.size()!=0){
int a=list.get(0);//获取数组队中第一个元素
list.remove(0);//删除数组队中第一个元素
for(int i=0;i<A.length;i++){
//当list数组队的第一个元素等于边A[i]的起点时
if(a==A[i].a&&result[A[i].b]>(result[A[i].a]+A[i].value)){
result[A[i].b]=result[A[i].a]+A[i].value;
if(!used[A[i].b]){
list.add(A[i].b);
num[A[i].b]++;
if(num[A[i].b]>n){
return false;
}
used[A[i].b]=true;//表示边A[i]的终点b已进入数组队
}
}
}
used[a]=false; //顶点a出数组对
}
return true;
}
}
以上这篇SPFA 算法实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

SPFA 算法实例讲解
适用范围:给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了. 我们约定有向加权图G不存在负权回路,即最短路径一定存在.当然,我们可以在执行该算法前做一次拓扑排序,以判断是否存在负权回路,但这不是我们讨论的重 点. 算法思想:我们用数组d记录每个结点的最短路径估计值,用邻接表来存储图G.我们采取的方法是动态逼近法:设立一个先进先出的队列用来保存待优化的 结点,优化时每次取出队首结点u,并且用u点当前的最短路
-
JS数组操作中的经典算法实例讲解
冒泡排序 <script type="text/javascript"> var arr = [3,7,6,2,1,5]; 定义一个交换使用的中间变量 var temp = 0; for(i=0;i<arr.length;i++){ for(j=0;j<arr.length;j++){ 如果下一个元素小于当前元素 if(arr[j]>arr[j+1]){ 互换 temp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = tem
-
NetworkX之Prim算法(实例讲解)
引言 Prim算法与Dijkstra的最短路径算法类似,它采用贪心策略.算法开始先把图中权值最小的边添加到树T中,然后不断把权值最小的边E(E的一个端点在T中,另一个在G-T中).当没有符合条件的E时算法结束,此时T就是G的一个最小生成树. NetworkX是一款Python的软件包,用于创造.操作复杂网络,以及学习复杂网络的结构.动力学及其功能. 本文借助networkx.Graph类实现Prim算法. 正文 Prim算法的代码 Prim def prim(G, s): dist = {} #
-
C语言杨氏矩阵查找算法实例讲解
目录 一.杨氏矩阵介绍 二.查找算法 1.查找思路 2.步骤 3.代码 三.杨氏矩阵例题 代码 特别注意 四.总结 本文以C语言实现,介绍杨氏矩阵中通用的查找算法. 一.杨氏矩阵介绍 杨氏矩阵种,每一行的数都从左到右递增,每一列的数都从上到下递增.如下图是一个简单的杨氏矩阵: 有一个数字矩阵,矩阵的每行从左到右是递增的,矩阵从上到下是递增的,请编写程序在这样的矩阵中查找某个数字是否存在. 要求:时间复杂度小于O(N) 二.查找算法 1.查找思路 杨氏矩阵是很有特点的,它有规律递增的特点决定了针对
-
Javascript迭代、递推、穷举、递归常用算法实例讲解
累加和累积 累加:将一系列的数据加到一个变量里面.最后的得到累加的结果 比如:将1到100的数求累加和 小球从高处落下,每次返回到原来一半,求第十次小球落地时小球走过的路程 <script> var h=100; var s=0; for(var i=0;i<10;i++){ h=h/2; s+=h; } s=s*2+100; </script> 累积:将一系列的数据乘积到一个变量里面,得到累积的结果. 常见的就是n的阶乘 var n=100; var result= 1;
-
java排序算法之_选择排序(实例讲解)
选择排序是一种非常简单的排序算法,从字面意思我们就可以知道,选择就是从未排序好的序列中选择出最小(最大)的元素,然后与第 i 趟排序的第 i-1(数组中下标从 0 开始) 个位置的元素进行交换,第 i 个元素之前的序列就是已经排序好的序列.整个排序过程只需要遍历 n-1 趟便可排好,最后一个元素自动为最大(最小)值. 举个小例子: arr[] = {3,1,2,6,5,4} 第 1 趟排序: index = 0, min = 1, 交换后 --> 1,3,2,6,5,4 第 2 趟排序: in
-
对python数据切割归并算法的实例讲解
当一个 .txt 文件的数据过于庞大,此时想要对数据进行排序就需要先将数据进行切割,然后通过归并排序,最终实现对整体数据的排序.要实现这个过程我们需要进行以下几步:获取总数据行数:根据行数按照自己的需要对数据进行切割:对每组数据进行排序 最后对所有数据进行归并排序. 下面我们就来实现这整个过程: 一:获取总数据的行 def get_file_lines(file_path): # 目标文件的路径 file_path = str(file_path) with open(file_path, 'r
-
python归并排序算法过程实例讲解
关于python的算法一直都是让我们又爱又恨,但是如果可以灵活运用起来,对我们的编写代码过程,可以大大提高效率,针对算法之一"归并排序"的灵活掌握,一起来看下吧~ 归并算法--小试牛刀 实例内容: 有 1 个无序列表如下: list = [23,35,12,34,54,78,76,99] 要求:使其按从小到大排序 图示思路 Python 代码 归并排序理解: 1.通过二分法把一个数组按照递归拆分为左右两组(至到独立元素为止) 2.按照从底层往高层的方法左右数组对比,同时对两个数组的第一
-
Java算法之数组冒泡排序代码实例讲解
冒泡排序是数组查找算法中最为简单的算法 冒泡排序原理: 假设一个数组长度为k(最高索引k-1),遍历前k - 1个(最高索引k-2)元素,若数组中的元素a[i]都与相邻的下一个元素a[i+1]进行比较,若a[i] > a[i+1] ,则这两个元素交换位置.以此类推,若a[i+1] > a[i+2],则交换位置-直至a[k-2]与a[k-1]比较完毕后,第0轮迭代结束.此时,a[k-1]为数组元素中的最大值. 第1轮迭代,再对数组a的前k-1个元素重复进行以上操作. - 第k-2轮迭代,对数组a
-
C++ STL中五个常用算法使用教程及实例讲解
目录 前言 sort()排序 常用遍历算法for_each() 常用遍历算法 搬运transform() 查找算法find 删除操作erase() 实例应用 前言 在C++中使用STL算法都要包含一个算法头文件 #include<algorithm> 这样我们才能使用这个STL算法函数 sort()排序 Sort函数包含在头文件为#include<algorithm>的c++标准库中,是一个专门用来排序的高效的函数,我们在解决问题时可以方便快捷的排列顺序. sort()函数中有三个