Python文件如何引入?详解引入Python文件步骤
python基本语法--引入Python文件
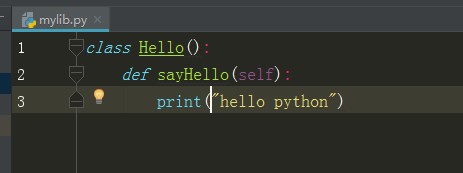
1、新建python文件 :在同目录lib下创建mylib.py和loadlib.py两个文件

2、在mylib.py文件中创建一个Hello的类
并且给这个类添加一个sayHello的方法,让她输出hello python
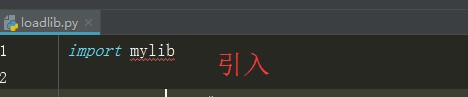
3、在loadlib.py 文件中引入mylib
import mylib
4、在loadlib中调用引用过来的python文件mylib.py中的Hello方法
这时import mylib中的mylib就相当与一个命名空间
我们要先创建mylib命名空间下Hello类的实例,然后再调用sayHello的方法
h = mylib.Hello()h.sayHello()

5、运行loadlib.py 文件,可以看到sayHello的方法成功运行了

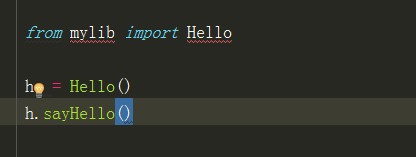
6、如果觉得每一次调用类还需要在命名空间下获取比较麻烦,
那么还有另一种引入的方式:
from mylib import Hello
然后直接调用就好了
h = Hello()h.sayHello()
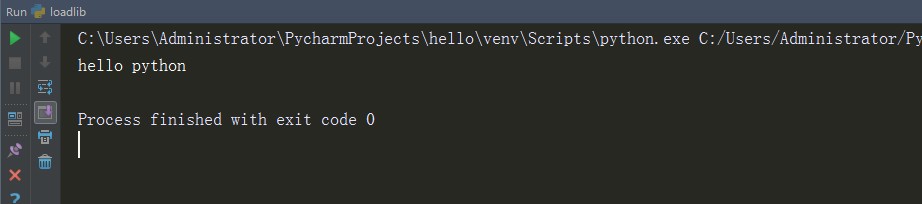
7、再次运行loadlib.py 文件,可以看到sayHello的方法依然成功运行了
总结
如果大家在学习的时候还有任何不明白的可以给小编留言,感谢你对我们的支持。
相关推荐
-
python引入不同文件夹下的自定义模块方法
初学Python,这个问题搞了我好久,现在来分享下我的解决思路,希望可以帮到大家. 先说下python引入模块的顺序:首先现在当前文件夹下查找,如果没有找到则查找Python系统变量中的模块.所以说,当我们引入同一个文件夹下的自定义模块时,可以很顺利的引入而不会报错.那么问题来了,不同文件夹下的呢?也用一样的方法吗? 举个栗子: 现在我们想在subPack1文件下的module_1.py中引入subPack2下的module_2.py. 但是我们在module_1.py中写下: import s
-
python引入导入自定义模块和外部文件的实例
项目中想使用以前的代码,或者什么样的需求致使你需要导入外部的包 如果是web 下,比如说django ,那么你新建一个app,把你需要导入的说用东东,都写到这个app中,然后在setting中的app也配上基本就ok了 如果是本地代码,可以有几种方式, 1.这种最简单,也可能最不实用,将你的外部文件放到跟需要调用外部文件的文件同一个包下,同一目录 folder ------toinvoke.py ------tobeinvoded.py 这样在toinvoke.py 中引入 import tov
-
Python中__init__.py文件的作用详解
__init__.py 文件的作用是将文件夹变为一个Python模块,Python 中的每个模块的包中,都有__init__.py 文件. 通常__init__.py 文件为空,但是我们还可以为它增加其他的功能.我们在导入一个包时,实际上是导入了它的__init__.py文件.这样我们可以在__init__.py文件中批量导入我们所需要的模块,而不再需要一个一个的导入. # package # __init__.py import re import urllib import sys impo
-
对python当中不在本路径的py文件的引用详解
众所周知,如果py文件不在当前路径,那么就不能import,因此,本文介绍如下两种有效的方法: 方法1: 修改环境变量,在~/.bashrc里面进行修改,然后source ~/.bashrc 方法2: 引入.pth文件 在site-packages添加一个路径文件,如mypkpath.pth,必须以.pth为后缀,写上你要加入的模块文件所在的目录名称就是了. 1 windows c:\python27\site-packages # 我们的学员把pth文件直接放在c:\python27 # (或
-

关于Python OS模块常用文件/目录函数详解
模块:包含定义函数和变量的python文件,可以被别的程序引入. os模块是操作系统接口模块,提供了一些方便使用操作系统相关功能函数,这里介绍下os模块中对于文件/目录常用函数和使用方法. 1. 返回当前文件目录:getcwd() 2.改变工作目录:chdir(path) 将当前工作目录更改为path的目录 3. 更改当前进程根目录:chroot(path) 4.列举出目录中的文件名:listdir(path) 返回列表,包含了path所有文件和目录名称,排序无顺序 5.创建目录:mkdir(p
-
Python学习之文件的读取详解
目录 文件读取的模式 文件对象的读取方法 使用 read() 函数一次性读取文件全部内容 使用 readlines() 函数 读取文件内容 使用 readline() 函数 逐行读取文件内容 mode().name().closed() 函数演示 文件读取小实战 with open() 函数 利用with open() 函数读取文件的小实战 上一章节 我们学习了如何利用 open() 函数创建一个文件,以及如何在文件内写入内容:今天我们就来了解一下如何将文件中的内容读取出去来的方法. 文件读取的
-
Python 文件操作的详解及实例
Python 文件操作的详解及实例 一.文件操作 1.对文件操作流程 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 现有文件如下: 昨夜寒蛩不住鸣. 惊回千里梦,已三更. 起来独自绕阶行. 人悄悄,帘外月胧明. 白首为功名,旧山松竹老,阻归程. 欲将心事付瑶琴. 知音少,弦断有谁听. f = open('小重山') #打开文件 data=f.read()#获取文件内容 f.close() #关闭文件 注意:if in the win,hello文件是utf8保存的,打
-
Python中使用pypdf2合并、分割、加密pdf文件的代码详解
朋友需要对一个pdf文件进行分割,在网上查了查发现这个pypdf2可以完成这些操作,所以就研究了下这个库,并做一些记录.首先pypdf2是python3版本的,在之前的2版本有一个对应pypdf库. 可以使用pip直接安装: pip install pypdf2 官方文档: pythonhosted.org/PyPDF2/ 里面主要有这几个类: PdfFileReader . 该类主要提供了对pdf文件的读操作,其构造方法为: PdfFileReader(stream, strict=True,
-
对Python的交互模式和直接运行.py文件的区别详解
看到类似C:\>是在Windows提供的命令行模式,看到>>>是在Python交互式环境下. 在命令行模式下,可以执行python进入Python交互式环境,也可以执行python hello.py运行一个.py文件,但是在Python交互 式环境下,只能输入Python代码执行. Python的交互模式和直接运行.py文件有什么区别呢? 直接输入python进入交互模式,相当于启动了Python解释器,但是等待你一行一行地输入源代码,每输入一行就执行一行. 直接运行.py文件相当
-
对python遍历文件夹中的所有jpg文件的实例详解
python发现文件夹下所有的jpg文件,并且安装文件排放的顺序输出 glob模块是最简单的模块之一,内容非常少.用它可以查找符合特定规则的文件路径名.跟使用windows下的文件搜索差不多.查找文件只用到三个匹配符:"*", "?", "[]"."*"匹配0个或多个字符:"?"匹配单个字符:"[]"匹配指定范围内的字符,如:[0-9]匹配数字. glob.glob 返回所有匹配的文件路
-
用python标准库difflib比较两份文件的异同详解
[需求背景] 有时候我们要对比两份配置文件是不是一样,或者比较两个文本是否异样,可以使用linux命令行工具diff a_file b_file,但是输出的结果读起来不是很友好.这时候使用python的标准库difflib就能满足我们的需求. 下面这个脚本使用了difflib和argparse,argparse用于解析我们给此脚本传入的两个参数(即两份待比较的文件),由difflib执行比较,比较的结果放到了一个html里面,只要找个浏览器打开此html文件,就能直观地看到比较结果,两份文件有差
-
python爬虫智能翻页批量下载文件的实例详解
python爬虫遇到爬取文件内容时,需要一页页的翻页爬取,这样很是麻烦,其实可以获取每个列表信息下的文件名和文件链接,让文件名和文件链接处理为列表,保存后下载,实现智能翻页批量下载文件,本文以以京客隆为例,批量下载文件,如财务资料,他的每一份报告都是一份pdf格式的文档.以此页面为目标,下载他每个分类的文件python爬虫实战之智能翻页批量下载文件. 1.引入库 import requests import pandas as pd from lxml import etree import r