分布式难题ElasticSearch解决大数据量检索面试
目录
- 引言
- 1、面试官:
- 我看你简历有写项目里有使用了ES,哪些场景用到了ES?
- 2、面试官:
- 那使用了ES后结果如何?
- 3、面试官:
- 关于ES的一些概念名字你了解多少?如索引,文档,倒排索引这些东西你是怎么理解的?
- 最重要的倒排索引
- 总结
- 关于ES的特性是使用场景概括:
引言
如果你的项目里有超过千万上亿级别的数据,且数据日增量较大需要高性能检索时,如订单数据,你该怎么办?
作为面试官,你需要找一个能解决这个问题的人!为应聘者,你该如何回答面试官这个问题?
你可以了解下使用搜索引擎框架,Elasticsearch (ES)是一个不错的开源搜索引擎框架。我们可以把 ES 当做“数据库”来使用,全球很多知名社区的全文检索都采用ES,如维基百科、Stack Overflow、Github等。
ElasticSearch是开源的,它基于lucene,是伸缩性强、分布式、高可用的全⽂搜索引擎,可以简单地通过RESTful 使用JSON格式索引数据。
尝试想一下,如果你做的是一个知识库系统,系统里有大量文章,如果你想通过某一个或关键字检索文章的内容,如果用MySQL来做这件事,光靠 like 查询根本无法满足,全文检索就是对一篇文章进行索引,ES可以把内容根据词的意义进行分词,然后分别创建索引,例如”我要励志做一个有追求的程序员” ,经过ES分词后是:“我“,“我要”,”励志“,“一个“,”有追求“,“程序员”,无论你根据哪个关键词去检索,都会检索到这句话。
让你不需要了解背后复杂的逻辑,即可完成搜索,Elasticsearch致力于隐藏分布式系统的复杂性。以下这些操作都是在底层自动完成的:
- 将你的文档分区到不同的容器或者分片(shards)中,它们可以存在于一个或多个节点中。
- 将分片均匀的分配到各个节点,对索引和搜索做负载均衡。
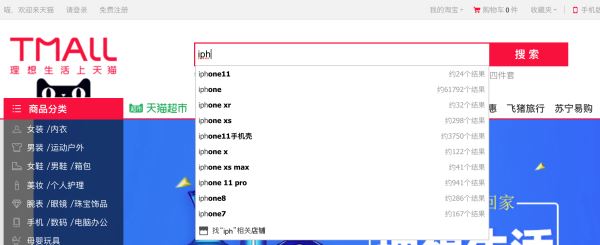
根据ES支持全文索引这个特性,我们还可以通过它做很多所有关于模糊搜索的功能,大数据量多维度聚合也是ES的强项,如天猫商城,通过关键字搜索商品,输入iph后就会自动加载iphone相关的所有商品,这是典型的搜索引擎使用场景。
1、面试官:
我看你简历有写项目里有使用了ES,哪些场景用到了ES?
问题分析: 凡事大数据量且需要检索的,这个时候你都可以想到ES,传统关系型数据库查询速度变慢,数据库分表联合查询速度慢。
答:有这样一个需求场景,运营系统需要一个订单分析工具,当时我们的订单库总数已经远远超过亿级别数据量,每天增量在百万级。
系统初期订单查询主要采用MySQL查询,并没有使用其他数据库,随着业务的发展,系统主要面临两个挑战:
- 随着数据增多,MySQL 分库分表后单张表数据依然增加到了几千万数据量级,查询越来越慢。
- 查询中带有大量聚合运算,如过滤计算异常订单总数,完成订单总数,计算订单金额等,MySQL并不擅长使用sql做大规模运算。
针对上述两个问题,我使用了 Elasticsearch 完美地应对慢查询这个问题,我使用ES作为主查询数据源,MySQL作为降级备案,如果 ES 集群因为各种原因不可用了,系统会把订单查询数据源自动切换到 MySQL 数据源,对于运营系统,虽然查询会变慢,但是不会耽误正常使用,而且这种降级的概率也极少发生。
系统架构图这样的:(尽量给面试官展示明白这个图)
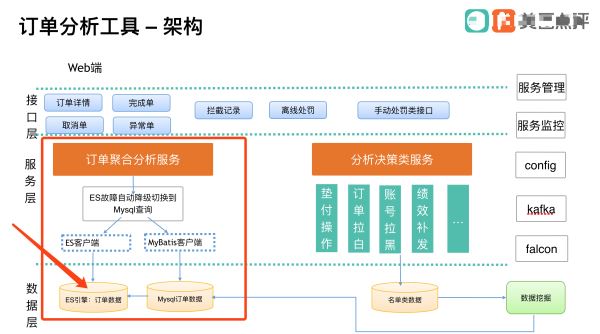
重点关注红色框,我使用了 ES 作为首选订单查询源,MySQL作为备份数据源,中间加入自动降级开关。
2、面试官:
那使用了ES后结果如何?
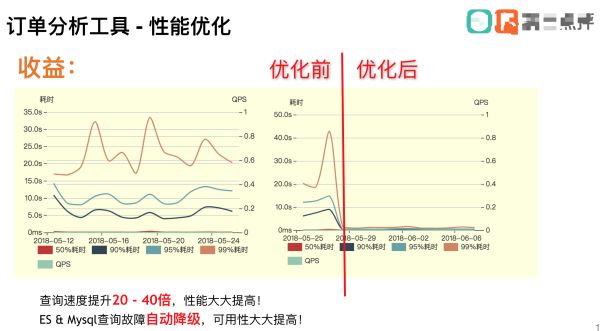
答:使用 ES 后,查询速度当然是大大的提高。
使用MySQL的时候99%的查询时间在10s+,架构引入ES后上线后,查询时间迅速降低到毫秒级别。
我还保留了性能监控的图放在我述职报告里,为升级加薪打下扎实的基础。
面试官一直点头,对我这一波操作非常认可。
3、面试官:
关于ES的一些概念名字你了解多少?如索引,文档,倒排索引这些东西你是怎么理解的?
问题分析:有些人刚刚接触 Elasticsearch 的时候,只顾用,只知道ES快,能装很多数据,但是面试官稍微问了一个倒排索引就懵逼了,还好意思说你会用搜索引擎?
答:先说说ES中的 Index,Document,Type,以及对应MySQL数据库
索引(Index):
索引的概念相当于MySQL里数据库的概念,用ES创建一个索引就是创建一个库,比如电商系统里给订单创建一个订单的索引,那客服系统就可以通过订单索引快速查询订单所有信息快速处理客诉。
文档(Document):
ES属于文档型数据库,文档的概念就相当于MySQL里一条数据的概念,很多个文档(很多条数据)构成了一个索引。
类型(Type)
上面说文档的概念就相当于MySQL里一条数据的概念,MySQL里一条数据有很多个字段,比如订单号,用户手机号,订单金额等,Type 的概念相当于根据每个字段聚合所一张表,如根据订单号分组,按照手机号分组,这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤文档,无论根据哪个字段搜索都有对应的Type(表)。
如果还不明白,直接给你整理成表:ES VS Mysql
| ElasticSearch | 关系型数据库:MySQL | |
|---|---|---|
| 对应关系: | 索引 | 库 |
| 对应关系: | 类型type | 数据表 |
| 对应关系: | 文档 | 行 |
| 对应关系: | 字段Field | 列 |
最重要的倒排索引
Tip: 如果你使用过 Elasticsearch 不知道倒排索引的概念那恐怕有点说不过去,倒排索引也叫反向索引(Inverted Index)
(开始给面试官举例分析倒排索引,我可是货真价实做过功课的)
有这样三段话:
- hello everyone
- this article is based on inverted index
- which is hashmap like data structure
使用ES保存后结构如下:
hello (1, 1)
everyone (1, 2)
this (2, 1)
article (2, 2)
is (2, 3); (3, 2)
based (2, 4)
on (2, 5)
inverted (2, 6)
index (2, 7)
which (3, 1)
hashmap (3, 3)
like (3, 4)
data (3, 5)
structure (3, 6)
hello 出现在第1句话第1个单词,所以是(1, 1) ,is (2, 3); (3, 2) 表示is出现在第2句第3个单词和第3句第2个单词,这样经过拆分后,每个关键词出现在哪句话哪个位置都一目了然,非常方便检索,这便是倒排索引的概念。试想一下,我们使用的百度或是谷歌检索,是不是这种数据结构更容易让我们找到你想要的所有内容,这便是倒排索引带给我们的便利之处,倒排索引允许快速全文搜索,但是在将文档添加到数据库时会增加处理成本
面试官: 行了行了,我知道你理解了,时间有限咱先不聊这个了。
这才是面试理想效果,让面试官无话可说。
总结
- 如果你要做分布式的实时文件存储,每个字段都被索引并可被搜索;
- 如果你要做实时分析搜索;
- 如果你要处理PB级结构化或非结构化数据;
这个时候请先想到使用搜索引擎。
关于 ES 的特性是使用场景概括:
大数据量聚合检索和排序,如计算用户订单总金额,订单数据等。自动补全,如搜索框通过关键字自动补全。高亮查询。关键字检索,模糊检索,拼音查询。记录系统后台日志,日志检索。
以上就是分布式难题ElasticSearch解决大数据量检索面试的详细内容,更多关于分布式ElasticSearch大数据量检索面试的资料请关注我们其它相关文章!
相关推荐
-
分布式全文检索引擎ElasticSearch原理及使用实例
一 什么是 ElasticSearch Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作: 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索. 可实现亿级数据实时查询 实时分析的分布式搜索引擎. 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据. 二 安装(wind
-
Elasticsearch写入瓶颈导致skywalking大盘空白
目录 前言 问题定位 THREAD-B,找出当前阻塞其他线程的线程 解决方案 临时方案,SKYWALKING参数调优 最终方案-优化ES的写入性能 结语 前言 继上次skywalking出故障<解析Arthas协助排查线上skywalking不可用问题>不到一个月,线上skywalking又出毛病了.又是大盘空白,trace列表最近的数据都查询不出来,但是时间稍久的数据就能查询出来,如一天前的数据有,一个小时前的数据就没有,这个只是表象,最终查明症结是ES的服务写入瓶颈,导致写入写入数据的线程
-
Elasticsearch使用常见问题解决方案
一.和redis一起使用会造成netty启动冲突问题,所以需要在***Application入口文件中添加方法: @PostConstruct public void init() { // see Netty4Utils.setAvailableProcessors() System.setProperty("es.set.netty.runtime.available.processors", "false"); } 二.NoNodeAvailableExcep
-
java 使用ElasticSearch完成百万级数据查询附近的人功能
上一篇文章介绍了ElasticSearch使用Repository和ElasticSearchTemplate完成构建复杂查询条件,简单介绍了ElasticSearch使用地理位置的功能. 这一篇我们来看一下使用ElasticSearch完成大数据量查询附近的人功能,搜索N米范围的内的数据. 准备环境 本机测试使用了ElasticSearch最新版5.5.1,SpringBoot1.5.4,spring-data-ElasticSearch2.1.4. 新建Springboot项目,勾选Elas
-

分布式难题ElasticSearch解决大数据量检索面试
目录 引言 1.面试官: 我看你简历有写项目里有使用了ES,哪些场景用到了ES? 2.面试官: 那使用了ES后结果如何? 3.面试官: 关于ES的一些概念名字你了解多少?如索引,文档,倒排索引这些东西你是怎么理解的? 最重要的倒排索引 总结 关于ES的特性是使用场景概括: 引言 如果你的项目里有超过千万上亿级别的数据,且数据日增量较大需要高性能检索时,如订单数据,你该怎么办? 作为面试官,你需要找一个能解决这个问题的人!为应聘者,你该如何回答面试官这个问题? 你可以了解下使用搜索引擎框架,Ela
-
SQL2005 大数据量检索的分页
@StartIndex为当前页起始序号,@EndIndex为当前页结束记录序号,可以直接作为参数输入,也可以通过输入PageSize和PageIndex计算得出 复制代码 代码如下: select * from ( select *,row_number() over(order by OrderColumn) as orderindex from TableName ) as a where a.orderindex between @StartIndex and @EndIndex
-
详解Mysql数据库平滑扩容解决高并发和大数据量问题
目录 1 停机方案 2 停写方案 3 平滑扩容之双写方案(中小型数据) 4 平滑扩容之2N方案大数据量问题解决 4.1 扩容问题 4.2 解决方案 4.3 双主架构思想 4.4 环境部署 5 数据库秒级平滑2N扩容实践 5.1 新增数据库VIP 5.2 应用服务增加动态数据源 5.3 解除原双主同步 5.4 安装MariaDB扩容服务器 5.5 增加KeepAlived服务实现高可用 5.6 清理数据并验证 1 停机方案 发布公告 停止服务 离线数据迁移(拆分,重新分配数据) 数据校验 更改配置
-
针对Sqlserver大数据量插入速度慢或丢失数据的解决方法
我的设备上每秒将2000条数据插入数据库,2个设备总共4000条,当在程序里面直接用insert语句插入时,两个设备同时插入大概总共能插入约2800条左右,数据丢失约1200条左右,测试了很多方法,整理出了两种效果比较明显的解决办法: 方法一:使用Sql Server函数: 1.将数据组合成字串,使用函数将数据插入内存表,后将内存表数据复制到要插入的表. 2.组合成的字符换格式:'111|222|333|456,7894,7458|0|1|2014-01-01 12:15:16;1111|222
-
完美解决TensorFlow和Keras大数据量内存溢出的问题
内存溢出问题是参加kaggle比赛或者做大数据量实验的第一个拦路虎. 以前做的练手小项目导致新手产生一个惯性思维--读取训练集图片的时候把所有图读到内存中,然后分批训练. 其实这是有问题的,很容易导致OOM.现在内存一般16G,而训练集图片通常是上万张,而且RGB图,还很大,VGG16的图片一般是224x224x3,上万张图片,16G内存根本不够用.这时候又会想起--设置batch,但是那个batch的输入参数却又是图片,它只是把传进去的图片分批送到显卡,而我OOM的地方恰是那个"传进去&quo
-
解决Mybatis 大数据量的批量insert问题
前言 通过Mybatis做7000+数据量的批量插入的时候报错了,error log如下: , ('G61010352', '610103199208291214', '学生52', 'G61010350', '610103199109920192', '学生50', '07', '01', '0104', ' ', , ' ', ' ', current_timestamp, current_timestamp ) 被中止,呼叫 getNextException 以取得原因. at org.p
-
php 大数据量及海量数据处理算法总结
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题.下面的一些问题基本直接来源于公司的面试笔试题目,方法不一定最优,如果你有更好的处理方法,欢迎与我讨论. 1.Bloom filter 适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集 基本原理及要点: 对于原理来说很简单,位数组+k个独立hash函数.将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明
-
大数据量,海量数据处理方法总结
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题.下面的一些问题基本直接来源于公司的面试笔试题目,方法不一定最优,如果你有更好的处理方法,欢迎与我讨论. 1.Bloom filter 适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集 基本原理及要点: 对于原理来说很简单,位数组+k个独立hash函数.将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明
-
大数据量高并发的数据库优化详解
如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. 一.数据库结构的设计 在一个系统分析.设计阶段,因为数据量较小,负荷较低.我们往往只注意到功能的实现,而很难注意到性能的薄弱之处,等到系统投入实际运行一段时间后,才发现系统的性能在降低,这时再来考虑提高系统性能则要花费更多的人力物力,而整个系统也不可避免的形成了一个打补丁工程. 所以在考虑整个系统的流程的时候,我们必须
-
Mysql大数据量查询优化思路详析
目录 1. 千万级别日志查询的优化 2. 几百万黑名单库的查询优化 3. Mybatis批量插入处理问题 项目场景: Mysql大表查询优化,理论上千万级别以下的数据量Mysql单表查询性能处理都是可以的. 问题描述: 在我们线上环境中,出现了mysql几千万级别的日志查询.几百万级别的黑名单库查询分页查询及条件查询都慢的问题,针对Mysql表优化做了一些优化处理. 原因分析:首先说一下日志查询,在Mysql中如果索引加的比较合适,走索引情况下千万级别查询不会超过一秒,Mysql查询的速度和检索