基于Jupyter notebook搭建Spark集群开发环境的详细过程
一、概念介绍:
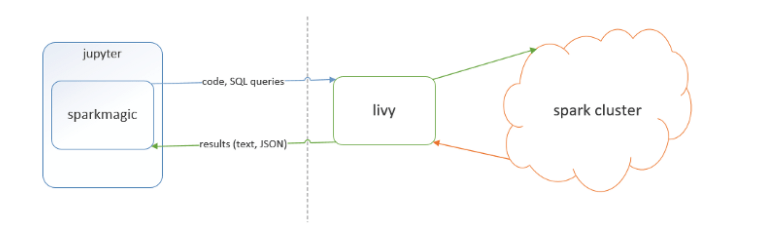
1、Sparkmagic:它是一个在Jupyter Notebook中的通过Livy服务器 Spark REST与远程Spark群集交互工作工具。Sparkmagic项目包括一组以多种语言交互运行Spark代码的框架和一些内核,可以使用这些内核将Jupyter Notebook中的代码转换在Spark环境运行。
2、Livy:它是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行。它提供了以下这些基本功能:提交Scala、Python或是R代码片段到远端的Spark集群上执行,提交Java、Scala、Python所编写的Spark作业到远端的Spark集群上执行和提交批处理应用在集群中运行
二、基本框架
为下图所示:
三、准备工作:
具备提供Saprk集群,自己可以搭建或者直接使用华为云上服务,如MRS,并且在集群上安装Spark客户端。同节点(可以是docker容器或者虚拟机)安装Jupyter Notebook和Livy,安装包的路径为:https://livy.incubator.apache.org/download/
四、配置并启动Livy:
修改livy.conf参考:https://enterprise-docs.anaconda.com/en/latest/admin/advanced/config-livy-server.html
添加如下配置:
livy.spark.master = yarn livy.spark.deploy-mode = cluster livy.impersonation.enabled = false livy.server.csrf-protection.enabled = false livy.server.launch.kerberos.keytab=/opt/workspace/keytabs/user.keytab livy.server.launch.kerberos.principal=miner livy.superusers=miner
修改livy-env.sh, 配置SPARK_HOME、HADOOP_CONF_DIR等环境变量
export JAVA_HOME=/opt/Bigdata/client/JDK/jdk export HADOOP_CONF_DIR=/opt/Bigdata/client/HDFS/hadoop/etc/hadoop export SPARK_HOME=/opt/Bigdata/client/Spark2x/spark export SPARK_CONF_DIR=/opt/Bigdata/client/Spark2x/spark/conf export LIVY_LOG_DIR=/opt/workspace/apache-livy-0.7.0-incubating-bin/logs export LIVY_PID_DIR=/opt/workspace/apache-livy-0.7.0-incubating-bin/pids export LIVY_SERVER_JAVA_OPTS="-Djava.security.krb5.conf=/opt/Bigdata/client/KrbClient/kerberos/var/krb5kdc/krb5.conf -Dzookeeper.server.principal=zookeeper/hadoop.hadoop.com -Djava.security.auth.login.config=/opt/Bigdata/client/HDFS/hadoop/etc/hadoop/jaas.conf -Xmx128m"
启动Livy:
./bin/livy-server start
五、安装Jupyter Notebook和sparkmagic
Jupyter Notebook是一个开源并且使用很广泛项目,安装流程不在此赘述
sparkmagic可以理解为在Jupyter Notebook中的一种kernel,直接pip install sparkmagic。注意安装前系统必须具备gcc python-dev libkrb5-dev工具,如果没有,apt-get install或者yum install安装。安装完以后会生成$HOME/.sparkmagic/config.json文件,此文件为sparkmagic的关键配置文件,兼容spark的配置。关键配置如图所示

其中url为Livy服务的ip和端口,支持http和https两种协议
六、添加sparkmagic kernel
PYTHON3_KERNEL_DIR="$(jupyter kernelspec list | grep -w "python3" | awk '{print $2}')"
KERNELS_FOLDER="$(dirname "${PYTHON3_KERNEL_DIR}")"
SITE_PACKAGES="$(pip show sparkmagic|grep -w "Location" | awk '{print $2}')"
cp -r ${SITE_PACKAGES}/sparkmagic/kernels/pysparkkernel ${KERNELS_FOLDER}
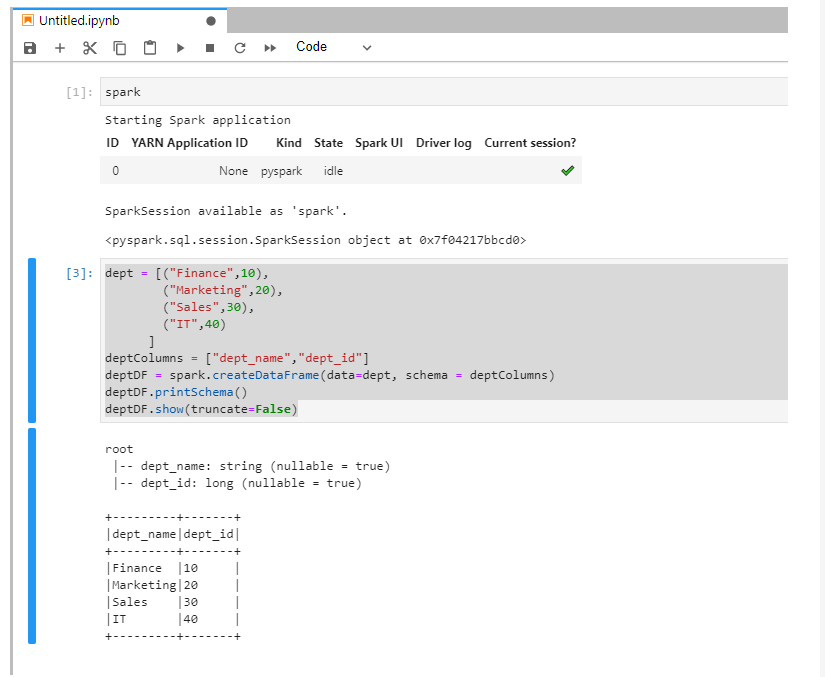
七、在Jupyter Notebook中运行spark代码验证:
八、访问Livy查看当前session日志:

到此这篇关于基于Jupyter notebook搭建Spark集群开发环境的详细过程的文章就介绍到这了,更多相关基于Jupyter notebook搭建Spark集群开发环境内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Jupyter notebook运行Spark+Scala教程
今天在intellij调试spark的时候感觉每次有新的一段代码,都要重新跑一遍,如果用spark-shell,感觉也不是特别方便,如果能像python那样,使用jupyter notebook进行编程就很方便了,同时也适合代码展示,网上查了一下,试了一下,碰到了很多坑,有些是旧的版本,还有些是版本不同导致错误,这里就记录下来安装的过程. 1.运行环境 硬件:Mac 事先装好:Jupyter notebook,spark2.1.0,scala 2.11.8 (这个版本很重要,关系到后面的安装)
-
Linux下远程连接Jupyter+pyspark部署教程
博主最近试在服务器上进行spark编程,因此,在开始编程作业之前,要先搭建一个便利的编程环境,这样才能做到舒心地开发.本文主要有以下内容: 1.python多版本管理利器-pythonbrew 2.Jupyter notebooks 安装与使用以及远程连接方法 3.Jupyter连接pyspark,实现web端sprak开发 一.python多版本管理利器-pythonbrew 在利用python进行编程开发的时候,很多时候我们需要多个Python版本进行测试,博主之前一直在Python2.x和
-

基于Jupyter notebook搭建Spark集群开发环境的详细过程
一.概念介绍: 1.Sparkmagic:它是一个在Jupyter Notebook中的通过Livy服务器 Spark REST与远程Spark群集交互工作工具.Sparkmagic项目包括一组以多种语言交互运行Spark代码的框架和一些内核,可以使用这些内核将Jupyter Notebook中的代码转换在Spark环境运行. 2.Livy:它是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行.它提供了以下这些基本功能:提
-
使用docker快速搭建Spark集群的方法教程
前言 Spark 是 Berkeley 开发的分布式计算的框架,相对于 Hadoop 来说,Spark 可以缓存中间结果到内存而提高某些需要迭代的计算场景的效率,目前收到广泛关注.下面来一起看看使用docker快速搭建Spark集群的方法教程. 适用人群 正在使用spark的开发者 正在学习docker或者spark的开发者 准备工作 安装docker (可选)下载java和spark with hadoop Spark集群 Spark运行时架构图 如上图: Spark集群由以下两个部分组成 集
-
Docker-Compose搭建Spark集群的实现方法
目录 一.前言 二.docker-compose.yml 三.启动集群 四.结合hdfs使用 一.前言 在前文中,我们使用Docker-Compose完成了hdfs集群的构建.本文将继续使用Docker-Compose,实现Spark集群的搭建. 二.docker-compose.yml 对于Spark集群,我们采用一个mater节点和两个worker节点进行构建.其中,所有的work节点均分配1一个core和 1GB的内存. Docker镜像选择了bitnami/spark的开源镜像,选择的s
-
详解docker搭建redis集群的环境搭建
本文介绍了docker搭建redis集群的环境搭建,分享给大家,废话不多说,具体如下: 下载镜像 docker pull redis 准备配置文件 mkdir /home/docker/redis/ wget https://raw.githubusercontent.com/antirez/redis/3.0/redis.conf -O /home/docker/redis/redis.conf cd /home/docker/redis/ sed -i 's/# slaveof <maste
-
在 Windows 下搭建高效的 django 开发环境的详细教程
从初学 django 到现在(记得那时最新版本是 1.8,本文发布时已经发展到 3.1 了),开发环境一直都是使用从官方文档或者别的教程中学来的方式搭建的.但是在实际项目的开发中,越来越感觉之前的开发环境难以适应项目的发展.官方文档或一些教程中的环境搭建方式主要存在这些问题: python manage.py runserver 启动的开发服务器热重载非常慢,尤其是当项目中导入了大量模块时,有时候改一次代码要等几秒钟才能完成重载. 主力开发环境为 Windows + PyCharm,然而有时候依
-
vscode搭建STM32开发环境的详细过程
需要安装的软件 vscode 必装插件: C/C++:用于提供高亮显示和代码补全 Cortex-Debug:用于提供调试配置 make make工具可以直接下载xPack项目提供的windows-build-tools工具里面带了make工具. Release xPack Windows Build Tools v4.2.1-2 · xpack-dev-tools/windows-build-tools-xpack (github.com) openocd arm-none-eabi stm32
-
ol7.7安装部署4节点hadoop 3.2.1分布式集群学习环境的详细教程
准备4台虚拟机,安装好ol7.7,分配固定ip192.168.168.11 12 13 14,其中192.168.168.11作为master,其他3个作为slave,主节点也同时作为namenode的同时也是datanode,192.168.168.14作为datanode的同时也作为secondary namenodes 首先修改/etc/hostname将主机名改为master.slave1.slave2.slave3 然后修改/etc/hosts文件添加 192.168.168.11 m
-
windows下在vim中搭建c语言开发环境的详细过程
1 代码格式化 C语言代码的格式化需要使用clang-format,而clang-format被集成在了llvm中,所以需要先安装llvm,点击此处下载 下载之后运行安装文件,将其中的bin目录添加到环境变量path中(需重启电脑使新添加的环境变量生效).例如我安装后的目录为C:\wsr\LLVM\bin,图中的clang-format就是格式化c代码需要的组件 1.1 clang-format初体验 test1.c #include <stdio.h> int main(int argc,
-
openEuler 搭建java开发环境的详细过程
目录 1. 初始化环境 2. 安装jdk8 3. 安装SVN 4. 安装Git 5. 安装Node.js 6. 下载并激活IntelliJ IDEA 7. 下载并激活Navicat 本文操作系统及版本号:↓openEuler release 22.03 LTSLinux version 5.10.0-60.35.0.64.oe2203.x86 _64 1. 初始化环境 # 1. 更新依赖库 yum -y update # 2. 安装常用工具包 yum -y install wget tar vi
-
Clion配置opencv开发环境的详细过程
之前尝试用vs写opencv的项目,但是因为各种使用习惯很难改过来,加上vs的快捷键和代码智能提示相当的蛋疼,所以尝试着在clion上配置opencv开发环境. 以下是详细配置过程: 预先需要安装的软件: clion:这个是jetbrain家出品的C++集成开发环境,如果你用习惯了idea,pycharm,那么上手这个软件,应该也是比较简单的.相比较巨硬家的visual studio而言,个人觉得vs的快捷键着实蛋疼,而且用的确实少,一些窗口设置不太习惯.这个软件安装比较简单,不详细展开 min