sqoop读取postgresql数据库表格导入到hdfs中的实现
最近再学习spark streaming做实时计算这方面内容,过程中需要从后台数据库导出数据到hdfs中,经过调研发现需要使用sqoop进行操作,本次操作环境是Linux下。
首先确保环境安装了Hadoop和sqoop,安装只需要下载 ,解压 以及配置环境变量,这里不多说了,网上教程很多。
一、配置sqoop以及验证是否成功
切换到配置文件下:cd $SQOOP_HOME/conf
创建配置环境文件: cp sqoop-env-template.sh sqoop-env.sh
修改配置文件:conf/vi sqoop-env.sh:修改内容如下
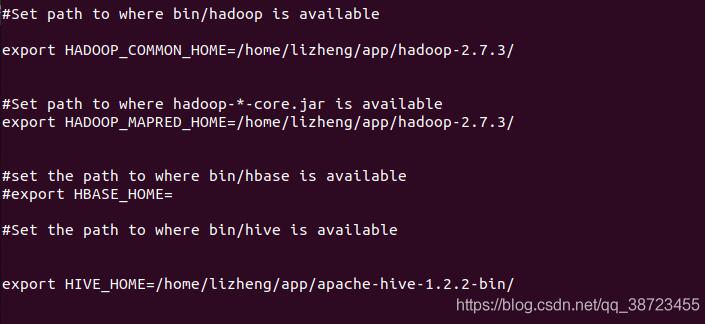
配置完成后,执行命令sqoop-version ,检查是否成功,如图显示sqoop 1.4.7即成功。

二、添加postgresql驱动jar包
因为这里使用sqoop读取postgresql的数据,所以需要将数据库驱动包放到$SQOOP_HOME/lib 下即可 。
三、导入pg数据库中表到hdfs中
1、首先要启动Hadoop集群,不然会报错
执行语句 $HADOOP_HOME/sbin/./start-all.sh
2、执行sqoop语句进行数据导入到hdfs
sqoop import \ --connect jdbc:postgresql:localhost:5432/test(数据库的名称) --username postgres (填自己的数据库用户名) --password 888888 (填自己数据库的密码) --table company (自己创建表的名称) --m 1 (mapreduce的个数)
执行结果如图:
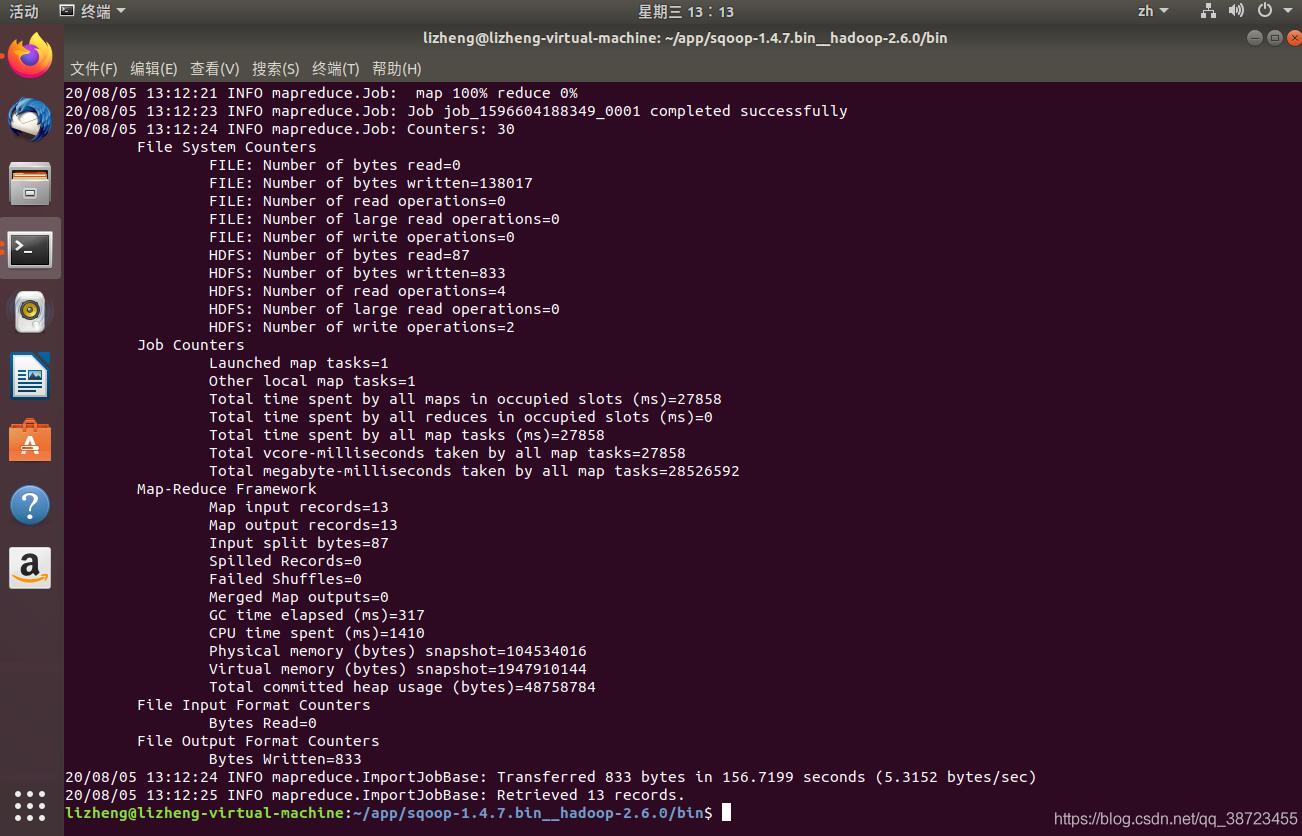
3、检查hdfs上是否成功存储到表数据
$HADOOP_HOME/bin hdfs dfs -cat /sqoop/part-m-00000(数据目录改成自己的)
结果如图所示:

显示使用sqoop 将 postgreql上的表格数据成功导入到hdfs中,这算今天也有点收获了!
补充:利用Sqoop从PostgreSQL导入数据时遇到的坑
sqoop import \ --connect "jdbc:postgresql://10.101.70.169:5432/db_name" \ --username "postgres" \ --password "123456" \ --table "test_user"\ --target-dir "/user/hive/warehouse/test.db/test_user" \ --fields-terminated-by '\t' \ --lines-terminated-by '\n' \ --hive-drop-import-delims \ --incremental lastmodified \ --merge-key id \ --check-column update_time \ --last-value "2019-03-25" \ --m 1 \ -- --schema "schema_name" \ --null-string '\\N' \ --null-non-string '\\N'
1、-- --schema 一定要放在后面,否则可能导致无运行日志或无法导入数据到指定目录且无法重新执行(报目录已存在)
2、PostgreSQL 须设置SET standard_conforming_strings = on;,否则--null-string和--null-non-string不起作用;
3、--null-string和--null-non-string放在-- --schema后面,否则执行时报Can't parse input data: '\N'
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

PostgreSQL 允许远程访问设置的操作
postgres远程连接方式配置 配置pg_hba.conf文件 目录C:\Program Files\PostgreSQL\9.5\data (QXY)主机 [postgres@qxy data]$ pwd /spark/pgsql/data [postgres@qxy data]$ cat pg_hba.conf # TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections o
-
PostgreSQL 流复制异步转同步的操作
非常重要的synchronous_commit参数 流复制的同步方式,有主库配置文件postgresql.conf,中的synchronous_commit控制着.所以理解该参数的配置十分重要. 单实例环境 参数值 说明 优点 缺点 on 或 local 当事务提交时,WAL先写入WAL buffer 再写到 WAL文件(落盘)中.设置为on表示提交事务时需要等待本地WAL最终落盘后,才向客户端返回成功. 非常安全 数据库性能有损耗 off 当事务提交时,不需要等待WAL先写入WAL buffe
-
PostgreSQL 设置允许访问IP的操作
PostgreSQL安装后默认只能localhost:5432访问 检验方法: curl localhost:5432 # 访问成功提示 curl: (52) Empty reply from server curl 127.0.0.1:5432 # 访问不成功提示 curl: (7) Failed to connect to 172.17.201.227 port 5432: Connection refused 修改pg_hba.conf pg_hba.conf和postgresql.con
-
navicat无法连接postgreSQL-11的解决方案
1. 通过find / -name postgresql.conf 和 find / -name pg_hba.conf 找到这两个文件 2. 设置外网访问: 1)修改配置文件 postgresql.conf listen_addresses = '*' 2)修改pg_hba.conf 在原来的host下面新加一行 # IPv4 local connections: host all all 127.0.0.1/32 trust host all all 0.0.0.0/0 password 3
-
sqoop 实现将postgresql表导入hive表
使用sqoop导入数据至hive常用语句 直接导入hive表 sqoop import --connect jdbc:postgresql://ip/db_name --username user_name --table table_name --hive-import -m 5 内部执行实际分三部,1.将数据导入hdfs(可在hdfs上找到相应目录),2.创建hive表名相同的表,3,将hdfs上数据传入hive表中 sqoop根据postgresql表创建hive表 sqoop creat
-
解决sqoop从postgresql拉数据,报错TCP/IP连接的问题
问题: sqoop从postgresql拉数据,在执行到mapreduce时报错Connection refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections 问题定位过程: 1.postgresql 5432端口已开放,执行任务的节点能telnet通,并且netcat测试通过 2.sqoop list-tables命令可正常执行,sq
-
postgresql流复制原理以及流复制和逻辑复制的区别说明
流复制的原理: 物理复制也叫流复制,流复制的原理是主库把WAL发送给备库,备库接收WAL后,进行重放. 逻辑复制的原理: 逻辑复制也是基于WAL文件,在逻辑复制中把主库称为源端库,备库称为目标端数据库,源端数据库根据预先指定好的逻辑解析规则对WAL文件进行解析,把DML操作解析成一定的逻辑变化信息(标准SQL语句),源端数据库把标准SQL语句发给目标端数据库,目标端数据库接收到之后进行应用,从而实现数据同步. 流复制和逻辑复制的区别: 流复制主库上的事务提交不需要等待备库接收到WAL文件后的确认
-
sqoop读取postgresql数据库表格导入到hdfs中的实现
最近再学习spark streaming做实时计算这方面内容,过程中需要从后台数据库导出数据到hdfs中,经过调研发现需要使用sqoop进行操作,本次操作环境是Linux下. 首先确保环境安装了Hadoop和sqoop,安装只需要下载 ,解压 以及配置环境变量,这里不多说了,网上教程很多. 一.配置sqoop以及验证是否成功 切换到配置文件下:cd $SQOOP_HOME/conf 创建配置环境文件: cp sqoop-env-template.sh sqoop-env.sh 修改配置文件:co
-
postgresql数据库导出和导入及常用的数据库管理工具
目录 简介 一.数据库的导出和导入 1. 使用pgAdmin导出和导入数据库 2. 使用Navicate导出和导入数据库 3. 使用DBeaver导出和导入数据库 二.数据库表的导出和导入 1. 使用pgAdmin导出和导入数据表 2. 使用Navicat导出和导入数据表 3. 使用DBeaver导出和导入数据表 总结 简介 本篇文章主要介绍PostgreSQL库和表的导出和导入以及常用的数据库管理工具的使用 一.数据库的导出和导入 1. 使用pgAdmin导出和导入数据库 导出 导入 新建数据
-
如何将excel表格数据导入postgresql数据库
实际的工作中,我们经常会碰到统计数据的工作,有些维度的统计数据因为工作需要我们需要导出为excel作为报表附件供不同的部门审查.为了方便以后的对比工作,领导会让在数据库中创建一张表,用于专门记录这些数据.此时我们DBA需要将这些excel表格导入到数据库中,copy和\copy命令为我们提供了解决办法,本文主要通过copy命令的使用,介绍如何将excel表格导入至数据库中.关于copy及\copy命令的区别,请广大博友通过另一篇文章<如何将postgresql数据库表内数据导出为excel格式>
-
java读取cvs文件并导入数据库
本文实例为大家分享了java读取cvs文件并导入数据库的具体代码,供大家参考,具体内容如下 首先获取文件夹下面的所有类型相同的excel,可以用模糊匹配contains("匹配字段") public static List getDictory(String path) { File f = new File(path); List<String> dictories = new ArrayList<String>(); if (!f.exists()) { S
-
使用python将mdb数据库文件导入postgresql数据库示例
mdb格式文件可以通过mdbtools工具将内中包含的每张表导出到csv格式文件.由于access数据库和postgresQL数据库格式上会存在不通性,所以使用python的文件处理,将所得csv文件修改成正确.能识别的格式. 导入脚本说明(此脚本运行于linux): 1.apt-get install mdbtools,安装mdbtools工具 2.将mdb 文件拷贝到linux虚拟机中,修改脚本中mdb文件目录'dir' 3.修改服务器及数据库配置 4.执行脚本 复制代码 代码如下: # -
-
PHP读取CSV大文件导入数据库的实例
PHP如何对CSV大文件进行读取并导入数据库? 对于数百万条数据量的CSV文件,文件大小可能达到数百M,如果简单读取的话很可能出现超时或者卡死的现象. 为了成功将CSV文件里的数据导入数据库,分批处理是非常必要的. 下面这个函数是读取CSV文件中指定的某几行数据: /** * csv_get_lines 读取CSV文件中的某几行数据 * @param $csvfile csv文件路径 * @param $lines 读取行数 * @param $offset 起始行数 * @return arr
-
Python如何读取MySQL数据库表数据
本文实例为大家分享了Python读取MySQL数据库表数据的具体代码,供大家参考,具体内容如下 环境:Python 3.6 ,Window 64bit 目的:从MySQL数据库读取目标表数据,并处理 代码: # -*- coding: utf-8 -*- import pandas as pd import pymysql ## 加上字符集参数,防止中文乱码 dbconn=pymysql.connect( host="**********", database="kimbo&
-
Python使用PyGreSQL操作PostgreSQL数据库教程
PostgreSQL是一款功能强大的开源关系型数据库,本文使用python实现了对开源数据库PostgreSQL的常用操作,其开发过程简介如下: 一.环境信息: 1.操作系统: RedHat Enterprise Linux 4 Windows XP SP2 2.数据库: PostgreSQL8.3 3. 开发工具: Eclipse+Pydev+python2.6+PyGreSQL(提供pg模块) 4.说明: a.PostgreSQL数据库运行于RedHat Linux上,Win
-
php读取sqlite数据库入门实例代码
SQLite简介 SQLite是一款轻型的数据库,是遵守ACID的关联式数据库管理系统,它的设计目标是嵌入 式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了. 它能够支持 Windows/Linux/Unix等等主流的操作系统,同时能够跟很多程序语言相结合,比如Tcl.PHP.Java.C++..Net等,还有ODBC接口,同样比起 Mysql.PostgreSQL这两款开源世界著名的数据库管理系统来讲,它的处理速度比他们都快. 单
-
Java连接postgresql数据库的示例代码
本文介绍了Java连接postgresql数据库的示例代码,分享给大家,具体如下: 1.下载驱动jar 下载地址:https://jdbc.postgresql.org/download.html 2.导入jar包 新建lib文件夹,将下载的jar驱动包拖到文件夹中. 将jar驱动包添加到Libraries 3.程序代码如下:HelloWorld.java package test; import java.sql.Connection; import java.sql.DriverManage