MySQL为Null会导致5个问题(个个致命)
正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信息,如下图所示:

“兵马未动粮草先行”,看完了相关的配置之后,我们先来创建一张测试表和一些测试数据。
-- 如果存在 person 表先删除
DROP TABLE IF EXISTS person;
-- 创建 person 表,其中 username 字段可为空,并为其设置普通索引
CREATE TABLE person (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
mobile VARCHAR(13),
index(name)
) ENGINE='innodb';
-- person 表添加测试数据
insert into person(name,mobile) values('Java','13333333330'),
('MySQL','13333333331'),
('Redis','13333333332'),
('Kafka','13333333333'),
('Spring','13333333334'),
('MyBatis','13333333335'),
('RabbitMQ','13333333336'),
('Golang','13333333337'),
(NULL,'13333333338'),
(NULL,'13333333339');
select * from person;
构建的测试数据,如下图所示:
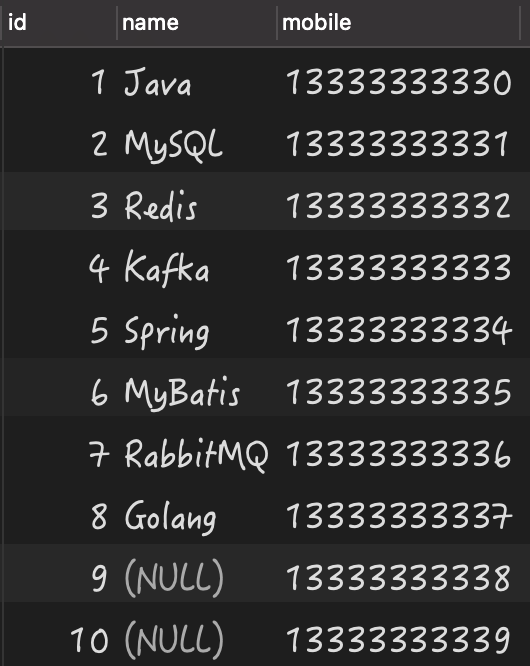
有了数据之后,我们就来看当列中存在 NULL 值时,究竟会导致哪些问题?
1.count 数据丢失
当某列存在 NULL 值时,再使用 count 查询该列,就会出现数据“丢失”问题,如下 SQL 所示:
select count(*),count(name) from person;
查询执行结果如下:

从上述结果可以看出,当使用的是 count(name) 查询时,就丢失了两条值为 NULL 的数据丢失。
解决方案
如果某列存在 NULL 值时,就是用 count(*) 进行数据统计。
扩展知识:不要使用 count(常量)
阿里巴巴《Java开发手册》强制规定:不要使用 count(列名) 或 count(常量) 来替代 count(),count() 是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*) 会统计值为 NULL 的行,而 count(列名) 不会统计此列为 NULL 值的行。
2.distinct 数据丢失
当使用 count(distinct col1, col2) 查询时,如果其中一列为 NULL,那么即使另一列有不同的值,那么查询的结果也会将数据丢失,如下 SQL 所示:
select count(distinct name,mobile) from person;
查询执行结果如下:

数据库的原始数据如下:

从上述结果可以看出手机号一列的 10 条数据都是不同的,但查询的结果却为 8。
3.select 数据丢失
如果某列存在 NULL 值时,如果执行非等于查询(<>/!=)会导致为 NULL 值的结果丢失。比如以下这个数据:

我需要查询除 name 等于“Java”以外的所有数据,预期返回的结果是 id 从 2 到 10 的数据,但当执行以下查询时:
select * from person where name<>'Java' order by id; -- 或 select * from person where name!='Java' order by id;
查询结果均为以下内容:

可以看出为 NULL 的两条数据凭空消失了,这个结果并不符合我们的正常预期。
解决方案
要解决以上的问题,只需要在查询结果中拼加上为 NULL 值的结果即可,执行 SQL 如下:
select * from person where name<>'Java' or isnull(name) order by id;
最终的执行结果如下:

4.导致空指针异常
如果某列存在 NULL 值时,可能会导致 sum(column) 的返回结果为 NULL 而非 0,如果 sum 查询的结果为 NULL 就可以能会导致程序执行时空指针异常(NPE),我们来演示一下这个问题。
首先,我们先构建一张表和一些测试数据:
-- 如果存在 goods 表先删除 DROP TABLE IF EXISTS goods; -- 创建 goods 表 CREATE TABLE goods ( id INT PRIMARY KEY auto_increment, num int ) ENGINE='innodb'; -- goods 表添加测试数据 insert into goods(num) values(3),(6),(6),(NULL); select * from goods;
表中原始数据如下:

接下来我们使用 sum 查询,执行以下 SQL:
select sum(num) from goods where id>4;
查询执行结果如下:
 当查询的结果为
当查询的结果为 NULL 而非 0 时,就可以能导致空指针异常。
解决空指针异常
可以使用以下方式来避免空指针异常:
select ifnull(sum(num), 0) from goods where id>4;
查询执行结果如下:

5.增加了查询难度
当某列值中有 NULL 值时,在进行 NULL 值或者非 NULL 值的查询难度就增加了。
所谓的查询难度增加指的是当进行 NULL 值查询时,必须使用 NULL 值匹配的查询方法,比如 IS NULL 或者 IS NOT NULL 又或者是 IFNULL(cloumn) 这样的表达式进行查询,而传统的 =、!=、<>... 等这些表达式就不能使用了,这就增加了查询的难度,尤其是对小白程序员来说,接下来我们来演示一下这些问题。
还是以 person 表为例,它的原始数据如下:

错误用法 1:
select * from person where name<>null;
执行结果为空,并没有查询到任何数据,如下图所示:

错误用法 2:
select * from person where name!=null;
执行结果也为空,没有查询到任何数据,如下图所示:
正确用法 1:
select * from person where name is not null;
执行结果如下:

正确用法 2:
select * from person where !isnull(name);
执行结果如下:
推荐用法
阿里巴巴《Java开发手册》推荐我们使用 ISNULL(cloumn) 来判断 NULL 值,原因是在 SQL 语句中,如果在 null 前换行,影响可读性;而 ISNULL(column) 是一个整体,简洁易懂。从性能数据上分析 ISNULL(column) 执行效率也更快一些。
扩展知识:NULL 不会影响索引
细心的朋友可能发现了,我在创建 person 表的 name 字段时,为其创建了一个普通索引,如下图所示:

然后我们用 explain 来分析查询计划,看当 name 中有 NULL 值时是否会影响索引的选择。
explain 的执行结果如下图所示:

从上述结果可以看出,即使 name 中有 NULL 值也不会影响 MySQL 使用索引进行查询。
总结
本文我们讲了当某列为 NULL 时可能会导致的 5 种问题:丢失查询结果、导致空指针异常和增加了查询的难度。因此在最后提倡大家在创建表的时候尽量设置 is not null 的约束,如果某列确实没有值,可以设置空值('')或 0 作为其默认值。
到此这篇关于MySQL为Null会导致5个问题(个个致命)的文章就介绍到这了,更多相关MySQL为Null导致问题内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
mysql not in、left join、IS NULL、NOT EXISTS 效率问题记录
NOT IN.JOIN.IS NULL.NOT EXISTS效率对比 语句一:select count(*) from A where A.a not in (select a from B) 语句二:select count(*) from A left join B on A.a = B.a where B.a is null 语句三:select count(*) from A where not exists (select a from B where A.a = B.a) 知道以上三
-

解决从集合运算到mysql的not like找不出NULL的问题
记一次有趣的发现: 有一个表,总记录数是1000条,现在有一条查询语句: #查询语句1 #找出表中id中含有'A'或'B'或'C'的字段 select * from table1 where id like '%A%' or id like '%B%' or id like '%C%' ; #成功查出300条 嗯查询正常,有300条记录呢. 然后我随便再敲一次查询语句-: #查询语句2 #找出表中id中不含有'A'且不含有'B'且不含有'C'的字段 select * from table1 wh
-
MySQL IFNULL判空问题解决方案
问题:mybatis返回的null类型数据消失,导致前端展示出错 思路:如果查询出的结果是空值,应当转换成空字符串.当然在前端也能进行判断,但要求后台实现这个功能. 解决方案: 使用如下方法查询: SELECT IFNULL(sex,'') AS sex FROM user --如果查询到这个sex为null值,那么就赋值成空字符串 不过,如果查询语句本身为null,那么返回前端的还是null,这个就要在代码里判断了. 比如: SELECT IFNULL(sex,'') AS sex FROM
-
解决mysql使用not in 包含null值的问题
注意!!! select * from user where uid not in (a,b,c,null); 这个sql不回返回任何结果.要避免not in的list中出现null的情况. 另外: –如果null参与算术运算,则该算术表达式的值为null.(例如:+,-,*,/ 加减乘除) –如果null参与比较运算,则结果可视为false.(例如:>=,<=,<> 大于,小于,不等于) –如果null参与聚集运算,则聚集函数都置为null(使用isnull(字段,0)等方式可以
-
MySQL中NOT IN填坑之列为null的问题解决
前一段时间在公司做一个小功能的时候,统计一下某种情况下有多少条数据,然后修改的问题,当时感觉很简单,写了一个如下的 SQL: SELECT COUNT(*) FROM t1 where tl.c1 not IN (SELECT t2.c1 FROM t2); 预期的结果是:有多少条数据在 t1 中,同时不在 t2 中,结果为:0,也就是 t1 中数据都在 t2 中,但是很容易就发现某些数据在 t1 中不在 t2 中,所以就感觉很奇怪,这个 SQL 看着也没问题啊.经过一番查询原来是因为 t2 的
-
MySQL为Null会导致5个问题(个个致命)
正式开始之前,我们先来看下 MySQL 服务器的配置和版本号信息,如下图所示: "兵马未动粮草先行",看完了相关的配置之后,我们先来创建一张测试表和一些测试数据. -- 如果存在 person 表先删除 DROP TABLE IF EXISTS person; -- 创建 person 表,其中 username 字段可为空,并为其设置普通索引 CREATE TABLE person ( id INT PRIMARY KEY auto_increment, name VARCHAR(2
-
低版本Druid连接池+MySQL驱动8.0导致线程阻塞、性能受限
目录 现象 根因分析 getLastPacketReceivedTimeMs()方法调用时机 解决方案 现象 应用升级MySQL驱动8.0后,在并发量较高时,查看监控打点,Druid连接池拿到连接并执行SQL的时间大部分都超过200ms 对系统进行压测,发现出现大量线程阻塞的情况,线程dump信息如下: "http-nio-5366-exec-48" #210 daemon prio=5 os_prio=0 tid=0x00000000023d0800 nid=0x3be9 waiti
-
MySQL隐式类型转换导致索引失效的解决
目录 问题 复现 隐式转换 总结 参考 问题 在工作中发现,有一个接口只执行一条SQL查询语句,并且SQL明明使用了主键列,但是速度很慢. 在MySQL中EXPLAINN后发现,执行时并没有使用主键索引,而是进行了全表扫描. 复现 数据表DDL如下,使用 user_id 作为主键索引: CREATE TABLE `user_message` ( `user_id` varchar(50) NOT NULL COMMENT '用户ID', `msg_id` int(11) NOT NULL COM
-
mysql IS NULL使用索引案例讲解
简介 mysql的sql查询语句中使用is null.is not null.!=对索引并没有任何影响,并不会因为where条件中使用了is null.is not null.!=这些判断条件导致索引失效而全表扫描. mysql官方文档也已经明确说明is null并不会影响索引的使用. MySQL can perform the same optimization on col_name IS NULL that it can use for col_name = constant_value.
-
浅谈mysql哪些情况会导致索引失效
下面有一些培训教学机构的口诀和我个人的一些总结: 为了讲解以下索引内容,我们先建立一个临时的表 test02 CREATE TABLE `sys_user` ( `id` varchar(64) NOT NULL COMMENT '主键', `name` varchar(64) DEFAULT NULL COMMENT '名字', `age` int(64) DEFAULT NULL COMMENT '年龄', `pos` varchar(64) DEFAULT NULL COMMENT '职位
-
mysql 转换NULL数据方法(必看)
使用mysql查询数据库,当执行left join时,有些关联的字段内容是NULL,因此获取记录集后,需要对NULL的数据进行转换操作. 本文将提供一种方法,可以在查询时直接执行转换处理.使获取到的记录集不需要再进行转换. mysql提供了IFNULL函数 IFNULL(expr1, expr2) 如果expr1不是NULL,IFNULL()返回expr1,否则返回expr2 实例: user表结构和数据 +----+-----------+ | id | name | +----+------
-
mysql中null(IFNULL,COALESCE和NULLIF)相关知识点总结
本文实例讲述了mysql中null(IFNULL,COALESCE和NULLIF)相关知识点.分享给大家供大家参考,具体如下: 在MySQL中,NULL值表示一个未知值,它不同于0或空字符串'',并且不等于它自身. 我们如果将NULL值与另一个NULL值或任何其他值进行比较,则结果为NULL,因为一个不知道是什么的值(NULL值)与另一个不知道是什么的值(NULL值)比较,其值当然也是一个不知道是什么的值(NULL值). 然而我们通常,使用NULL值来表示数据丢失,未知或不适用的情况. 例如,潜
-
解决MySQL数据库意外崩溃导致表数据文件损坏无法启动的问题
问题故障: MySQL数据库意外崩溃,一直无法启动数据库. 报错日志: 启动报错:service mysqld restart ERROR! MySQL server PID file could not be found! Starting MySQL. ERROR! The server quit without updating PID file (/www/wdlinux/mysql/var/iZ2358oz5deZ.pid). 数据库error日志: 200719 22:07:43 I
-
深入探寻mysql自增列导致主键重复问题的原因
废话少说,进入正题. 拿到问题后,首先查看现场,发现问题表的中记录的最大值比自增列的值要大,那么很明显,当有记录进行插入时,自增列产生的值就有可能与已有的记录主键冲突,导致出错.首先想办法解决问题,通过人工调大自增列的值,保证大于表内已有的主键即可,调整后,导数据正常.问题是解决了,接下来要搞清楚问题原因,什么操作导致了这种现象的发生呢? 这里有一种可能,即业务逻辑包含更新自增主键的代码,由于mysql的update动作不会同时更新自增列值,若更新主键值比自增列大,也会导致上述现象:记录最大值比
-
SQL Server、Oracle和MySQL判断NULL的方法
本文讲述SQL Server.Oracle.MySQL查出值为NULL的替换. 在SQL Server Oracle MySQL当数据库中查出某值为NULL怎么办? 1.MSSQL: ISNULL() 语法 Java代码 复制代码 代码如下: ISNULL ( check_expression , replacement_value ) ISNULL ( check_expression , replacement_value ) 参数 check_expression 将被检查是否为 NULL